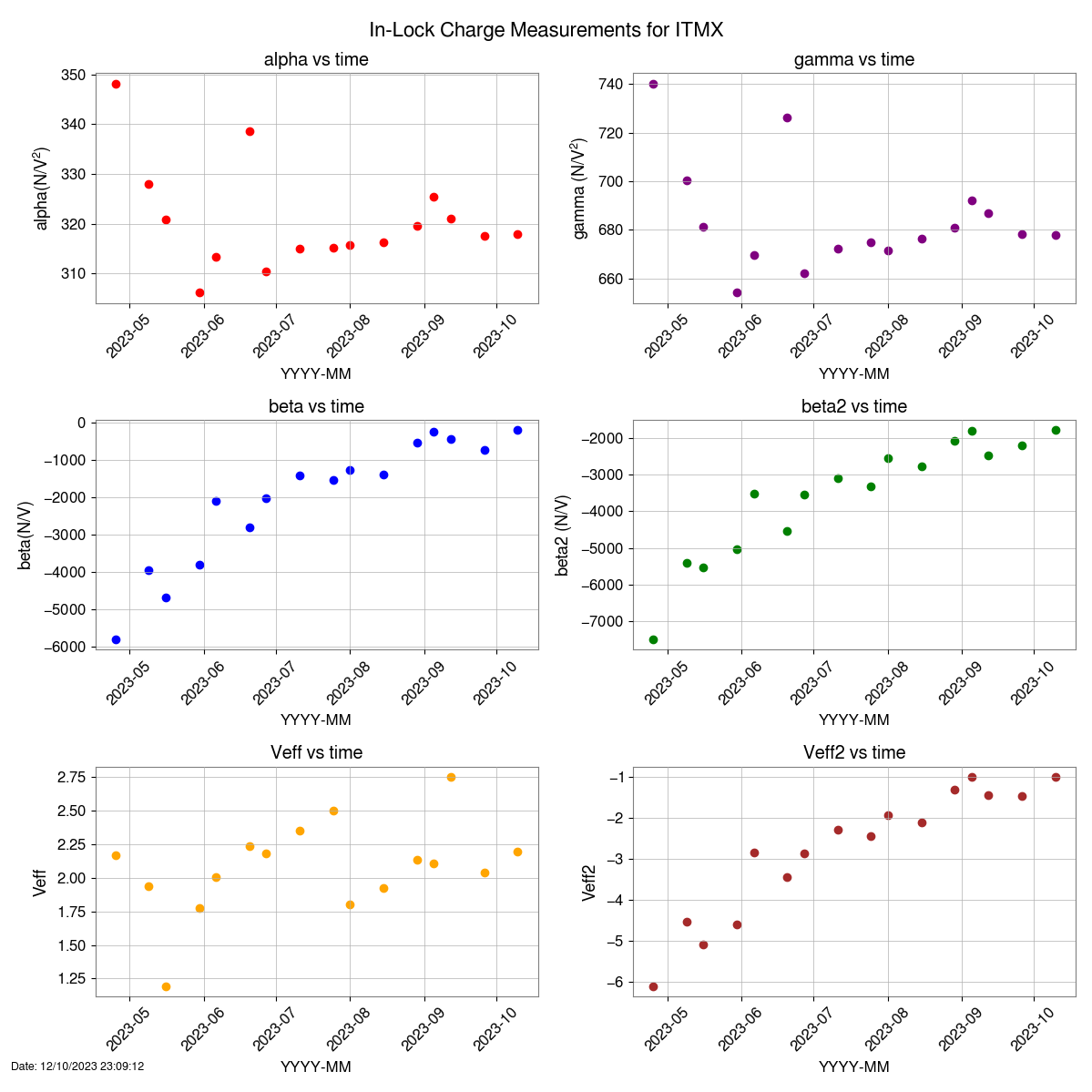
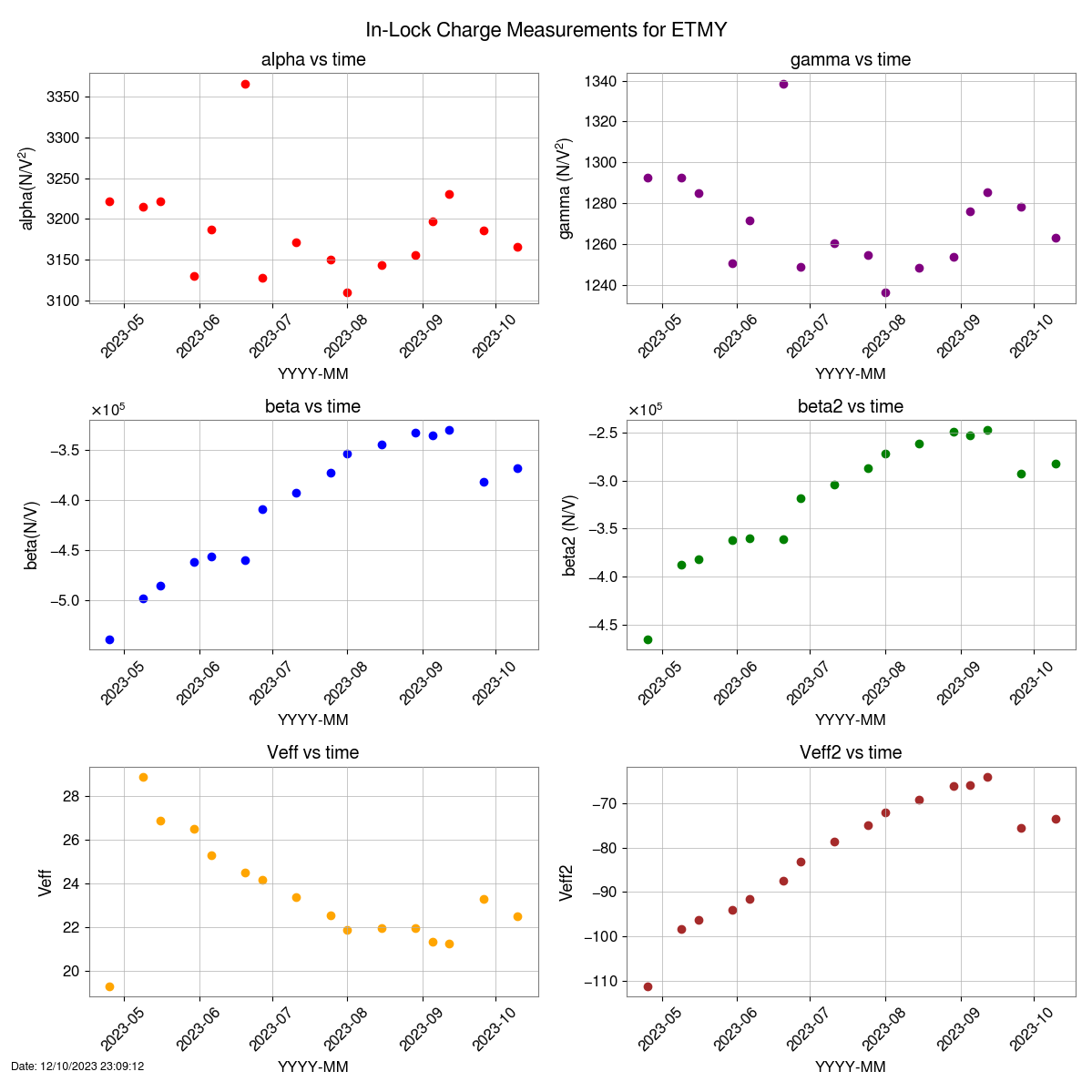
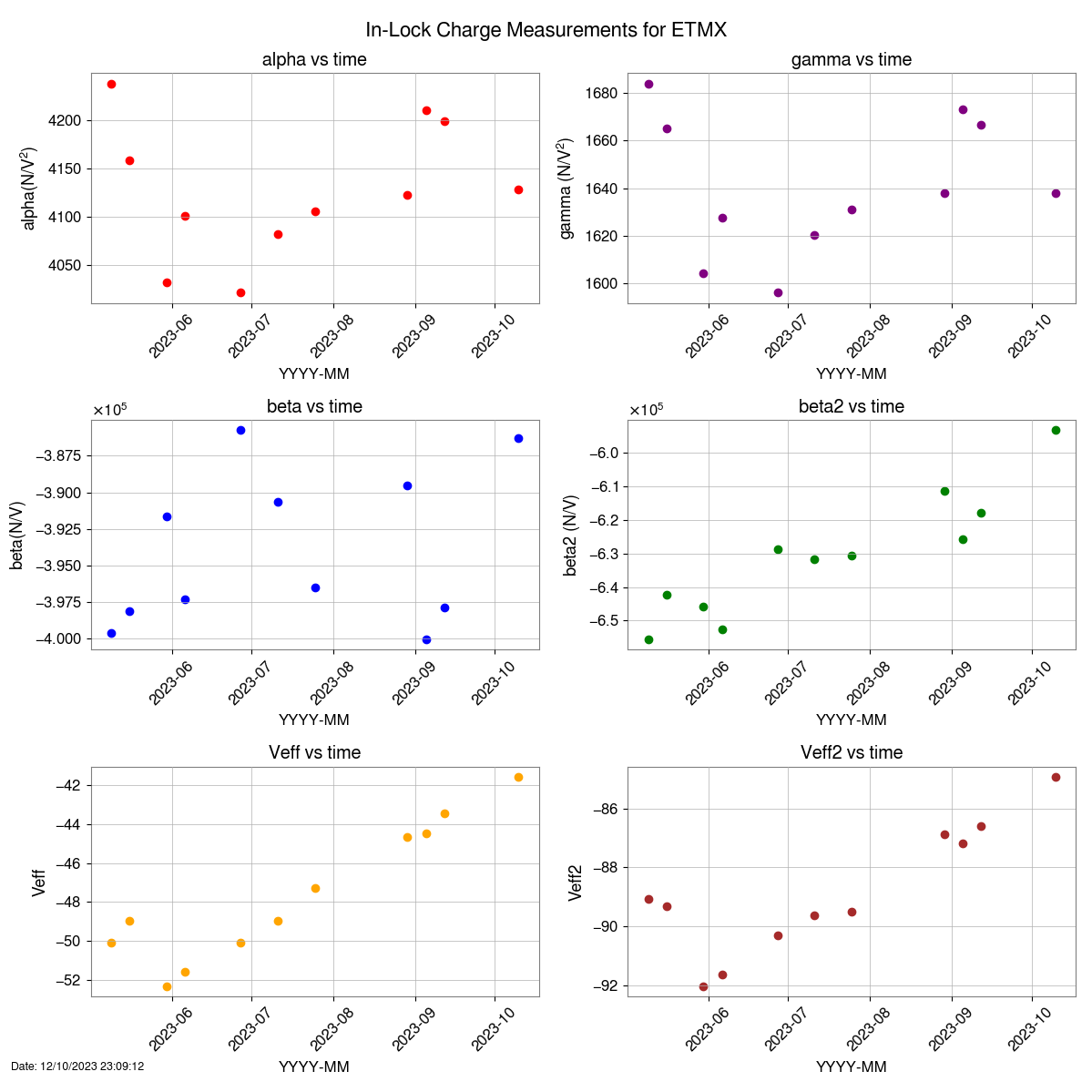
Closes FAMIS#26212, last checked 73167
Everything looking good besides ISS diffracted power low
Laser Status:
NPRO output power is 1.822W (nominal ~2W)
AMP1 output power is 67.6W (nominal ~70W)
AMP2 output power is 136.1W (nominal 135-140W)
NPRO watchdog is GREEN
AMP1 watchdog is GREEN
AMP2 watchdog is GREEN
PMC:
It has been locked 20 days, 1 hr 15 minutes
Reflected power = 16.57W
Transmitted power = 109.4W
PowerSum = 125.9W
FSS:
It has been locked for 0 days 10 hr and 20 min
TPD[V] = 0.7294V
ISS:
The diffracted power is around 1.7%
Last saturation event was 0 days 10 hours and 20 minutes ago
Possible Issues:
ISS diffracted power is low



{kind=link}