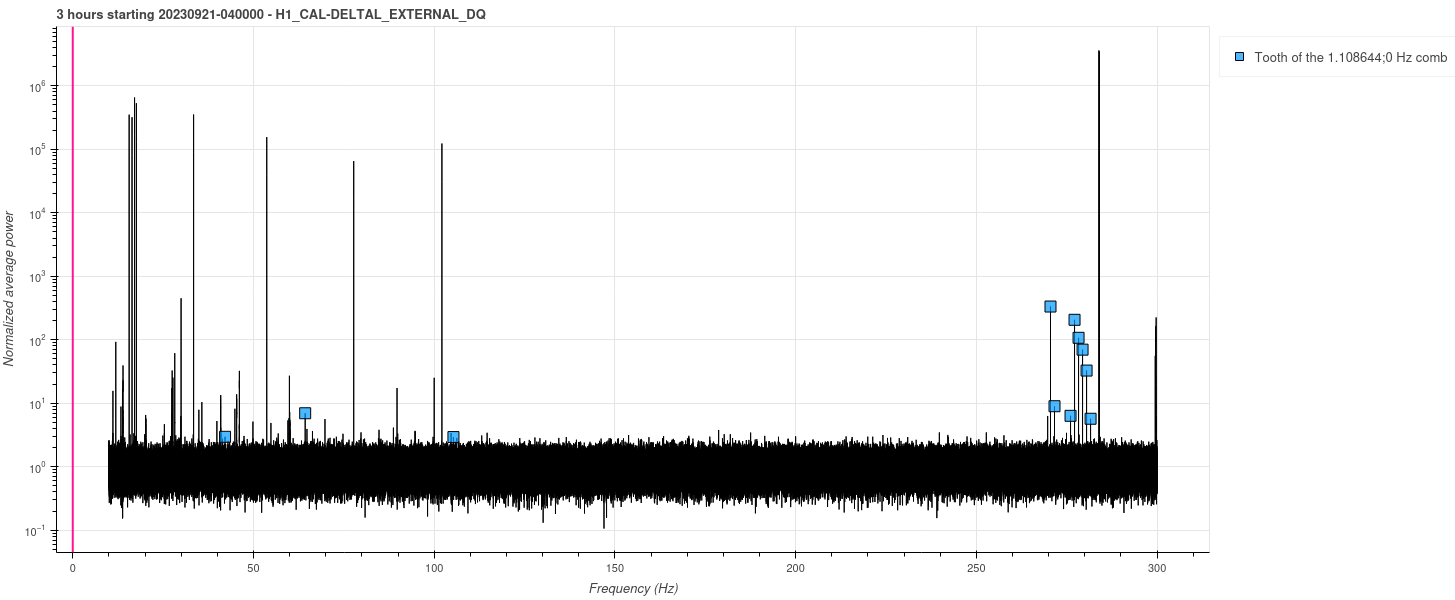
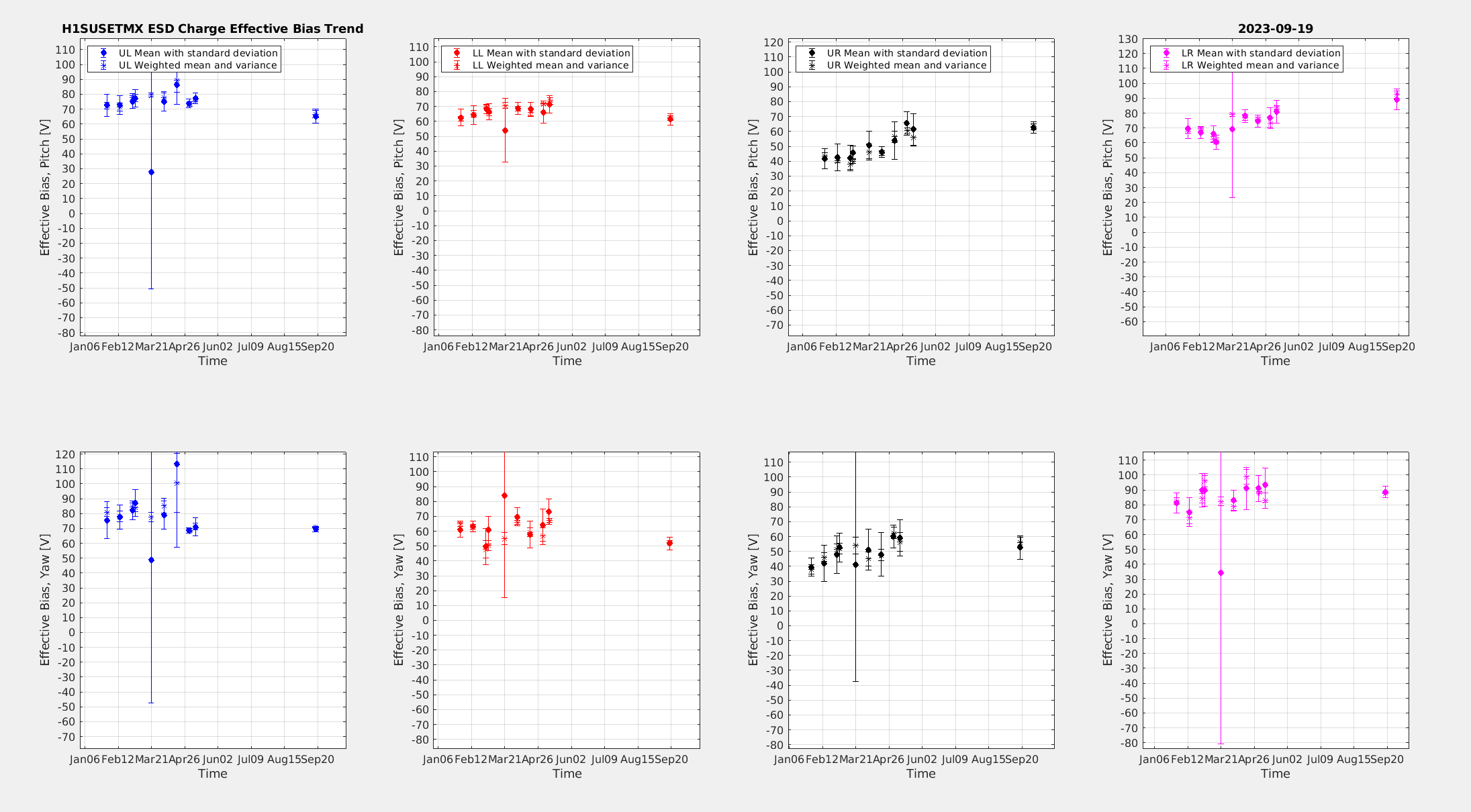
marc.pirello@LIGO.ORG - posted 12:04, Tuesday 19 September 2023 (72968)
Power Supply Health Check
Per WP11435 I performed a health check on the Kepco power supplies at EY, EX, and CER.
EY -All supplies pass, no excess vibrations, no sounds, good airflow, no temperature issues.
EX - All supplies pass, no excess vibrations, no sounds, good airflow, no temperature issues.
CER - All but one supplies pass, no excess vibrations, no sounds, good airflow, no temperature issues.
** ISC C1 - Slot 38 RHS N18V 6A 99F at fan housing, 105 at rear, very slight fan stumbling / rumbling. We need to keep an eye on this one, spare supply is staged.
While heading out to EX I spied some wildlife very close to the OSB. Coyote attacks on people are very rare. What to do if a coyote approaches you, make noise, clap your hands, whistle, they will move along.
Images attached to this report