david.barker@LIGO.ORG - posted 08:44, Tuesday 05 September 2023 (72675)
h1hpiham1 model restarted
WP11409
A new h1hpiham1 model was installed on h1seih16, no DAQ restart was needed.
WP11409
A new h1hpiham1 model was installed on h1seih16, no DAQ restart was needed.
TITLE: 09/05 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Preventive Maintenance
OUTGOING OPERATOR: Ryan C
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 3mph Gusts, 1mph 5min avg
Primary useism: 0.02 μm/s
Secondary useism: 0.13 μm/s
QUICK SUMMARY: PEM injections and SUS charge are finishing up, IFO locked for 45min. Maintenance about to start
The ITMY ISI watchdog tripped, hasn't shown up on H1locklosses yet.
We're going through an initial alignment on the relock.
Reaquired NLN at 13:17, just waiting on the camera_servo
ITMY IST ST2 watchdog tripped at 13:21, not totally sure why. We lost lock 4 minutes later
These lock losses were caused by the ITMY capacitive position sensors glitching. See LHO:72683.
ITMY stage2 watchdog tripped and killed the lock, not sure why it tripped. Its the second time in a row that it's happened.
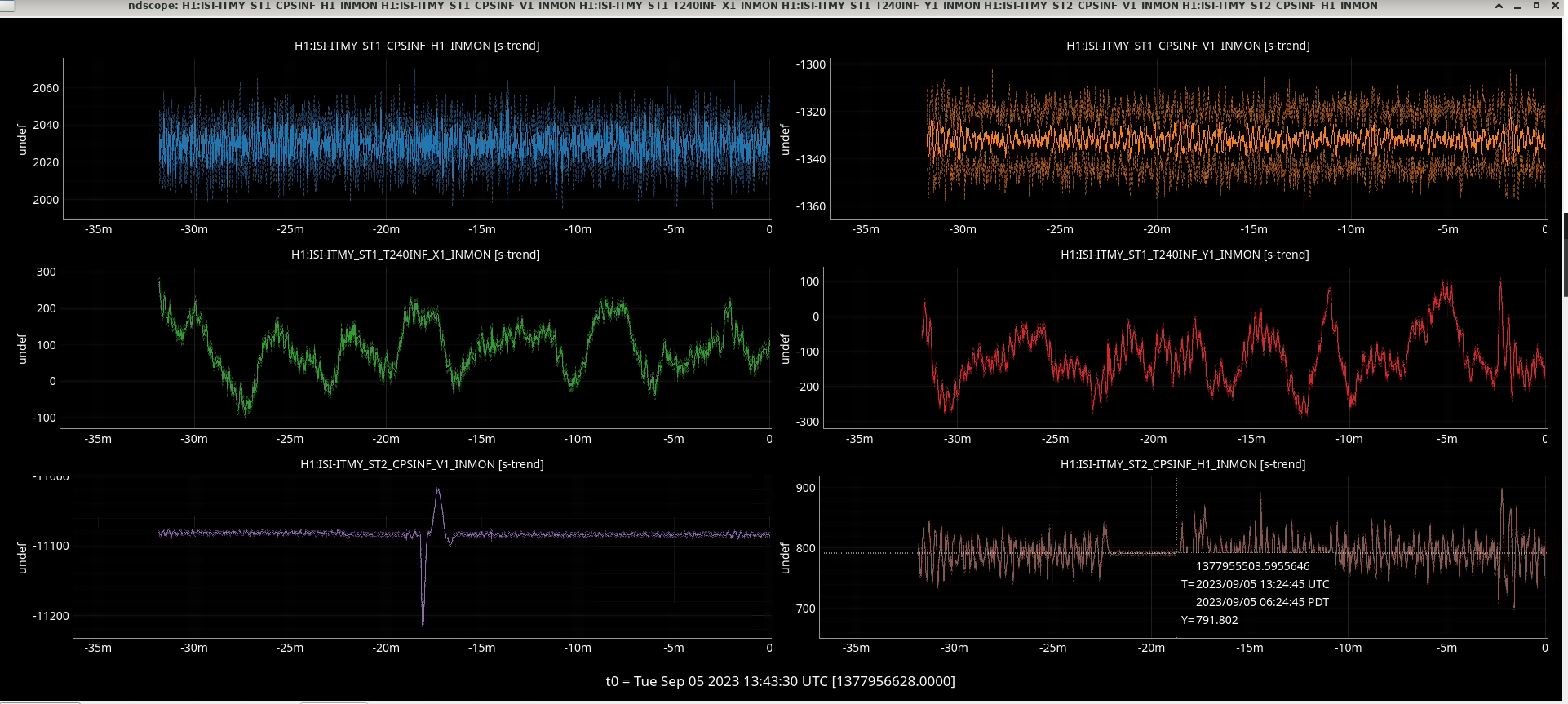
Reaquired NLN at 14:09UTC
These lock losses were caused by the ITMY capacitive position sensors glitching. See LHO:72683.
Workstations were updated and rebooted, including opslogin0 and the operator's workstations. This was an OS package upgrade. It did not include updates to the Conda environment except cdsws16 (in the back right of the CR) and zotws26 (Dave's workstation) have been updated to a new Conda environment.
This environment runs python 3.10 instead of python 3.9. Package changes are listed here:
https://git.ligo.org/cds/packaging/cds-conda-distribution/-/wikis/Environments#version-2023-09-04-01
Observing reaquired at 10:18
TITLE: 09/05 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 145Mpc
INCOMING OPERATOR: Ryan C
SHIFT SUMMARY:
IFO is in NLN and OBSERVING (as of 03:07 UTC, 4hr and 10 minute lock so far). See Midshift Update for details on this shift's two lock acquisitons (seperate lockloss alogs also linked within).
There has been nothing significant since last lock was acquired.
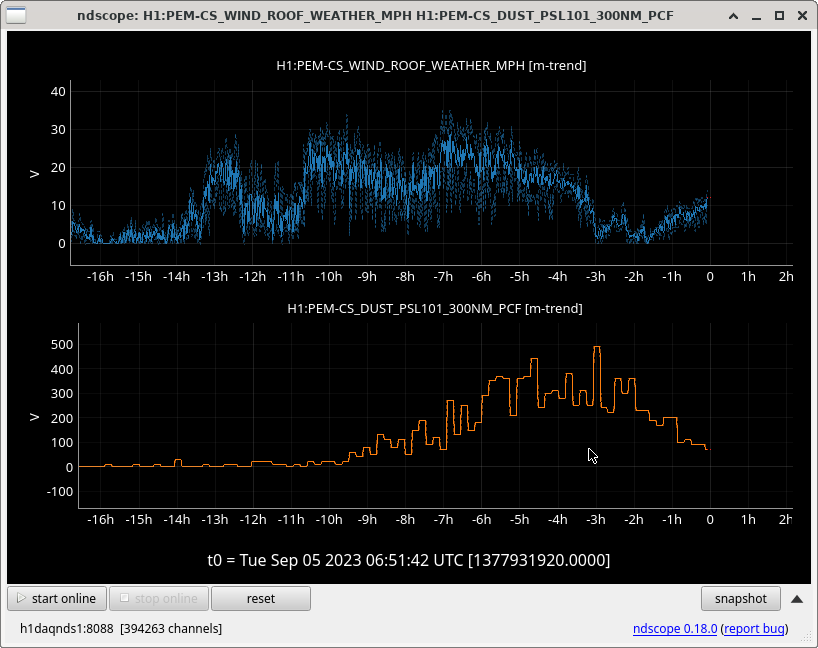
PSL Dust Monitor 101 levels are back to normal (scope of dust moving with CS reduced windspeeds below - you can see the dust "lagging" behind the wind as it settles).
LOG:
None
IFO is in NLN and OBSERVING as of 3:07 UTC
Locklosses (and lock acquisitions after Lockloss 00:12UTC)
Wind has been really high. We lost the first lock at 00:12UTC and then guardian lost lock 6 more times while relocking from:
1. DRMI at 0:33 UTC
2. Locking ALS at 0:35 UTC
3. Locking ALS at 0:37 UTC
4. Find IR at 0:40 UTC
5. Locking ALS at 00:42 UTC
6. Locking ALS at 00:44 UTC
As my lockloss alog 00:12UTC said, I think this was most certainly from the wind, given regular gusts nearing 40 hitting MX, EX. Seeing this, I put IFO in down at 00:45 UTC until I could see the wind speed go lower (and put the obs mode as wind). After 15 minutes, it seemed that the wind speed highs were about 10mph lower. I then tried to re-lock again at 1:02UTC. I don't think that this is/was an issue with locking at all because guardian went through the states quickly and as expected only to fail right as a 35+mph gust hits (looking at H1PEM_WEATHER_WIND) so I reckon that alignment is fine, but just getting bumped by particularly acute wind gusts. This behavior tracks with Ton'y lockloss 20:53 alog earlier today.
Finally, I managed to reach NLN at 1:42UTC and Observing at 1:58UTC (the wind speeds were about 20mph across the stations at this time).
We were observing for all of about one minute before we lost lock again - this may have been caused by wind or a 5.7 Fiji EQ though neither cause is terribly convincing given lower wind speeds and low magnitude.
Lockloss at 2:01 UTC. Relocking again...
Reached second NLN at 2:50 UTC and Observing at 3:07 UTC (wind speeds have calmed down a lot now - hopefully we can hold this lock).
Other:
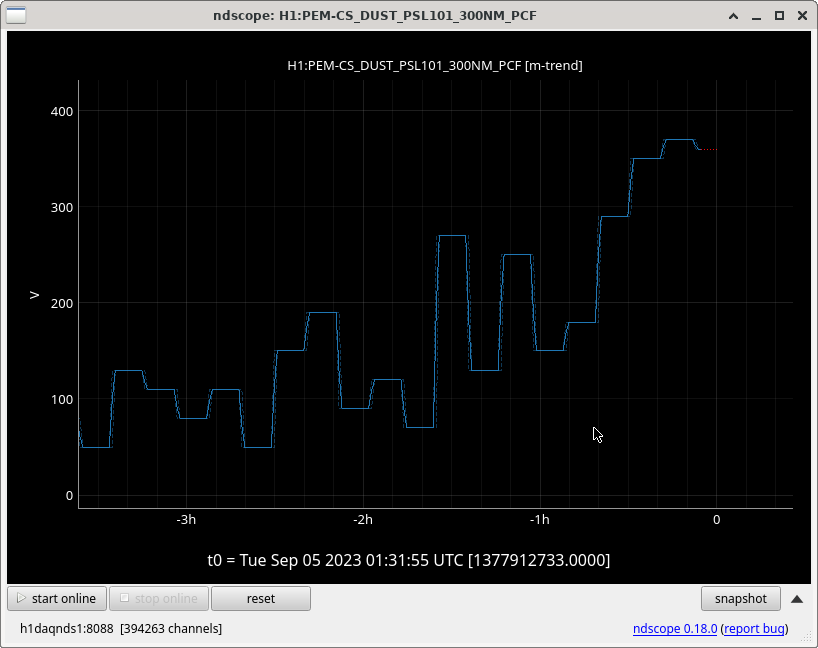
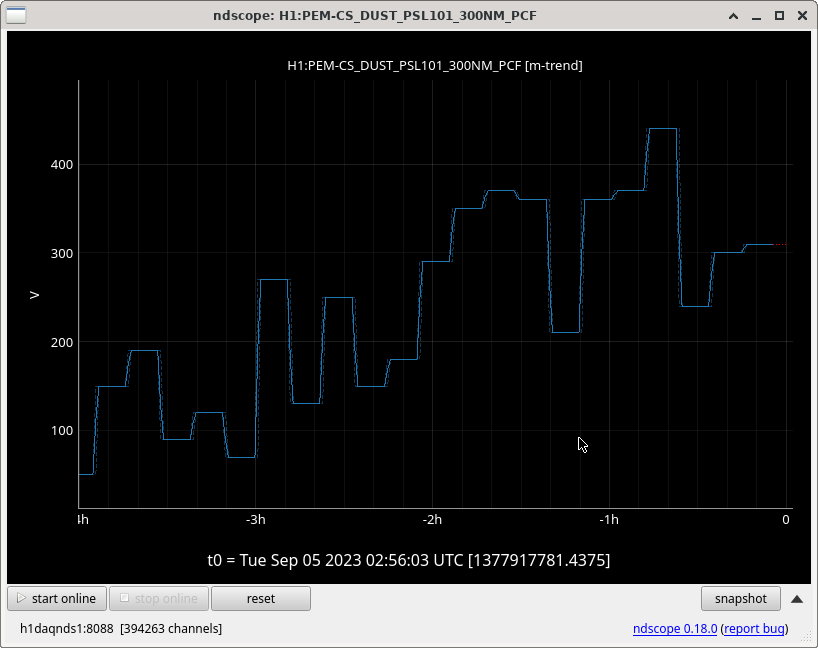
PSL Dust Monitor_101 is giving the RED alarm. I acknowledged it and tried to investigate by looking at the PEM PSL screen, but and seems that this is going up with the wind (screenshot at 1:33 UTC below). It is not far above the red threshold and occasionally goes from yellow to red and back. It seems that the dust peaked at 443 cts and is now at 280 (second screenshot at 3:00 UTC below). It seems to be going down with the wind as well.
Lockloss after being in observing for one minute only. This also happened 1 minute after guardian automatically reached "Seismic to CALM".
DRMI Unlocked causing a lockloss to a 1:25 hr lock. Looks like it happened during (and due to) a ~37ish mph wind gust (same as previous lockloss).
Potentially relevant: PSL dust monitor 101 is also giving the first (yellow) warning alarm.
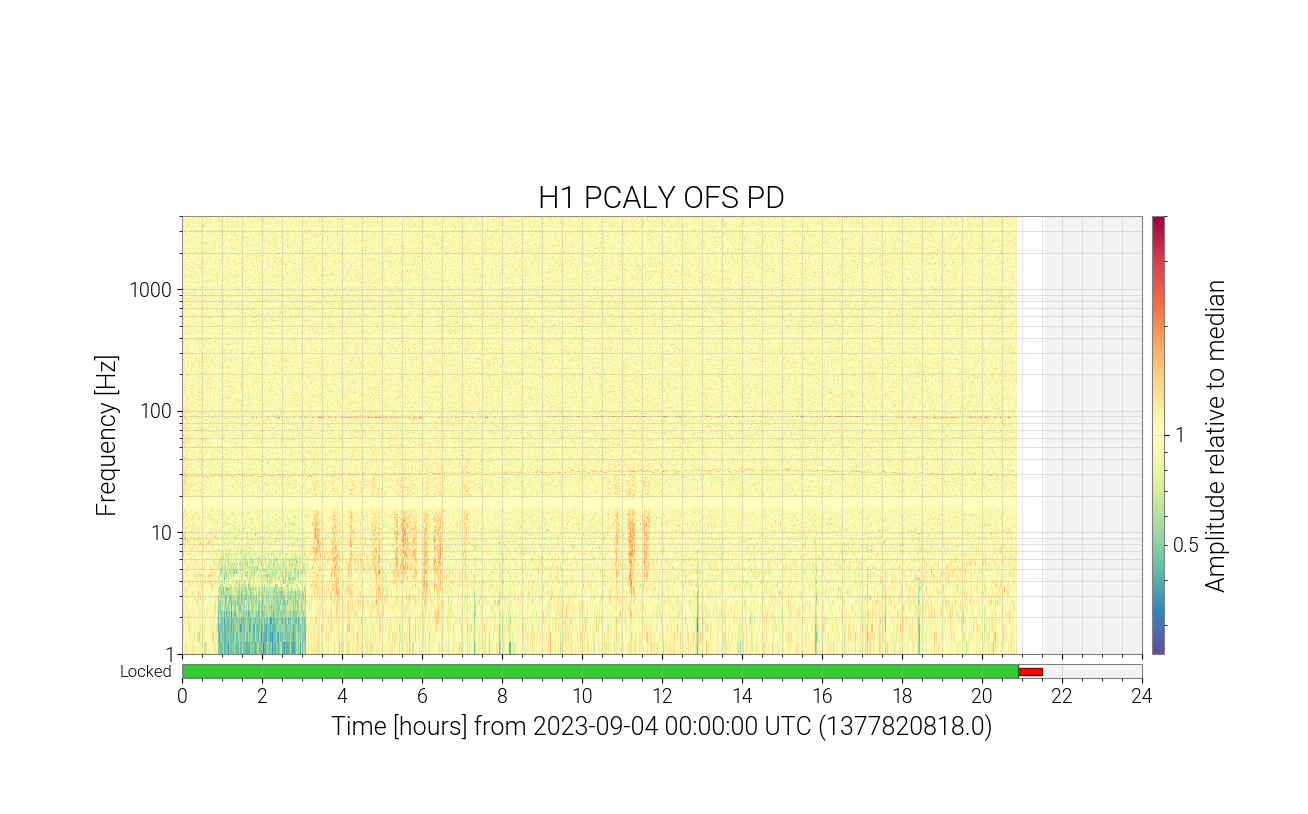
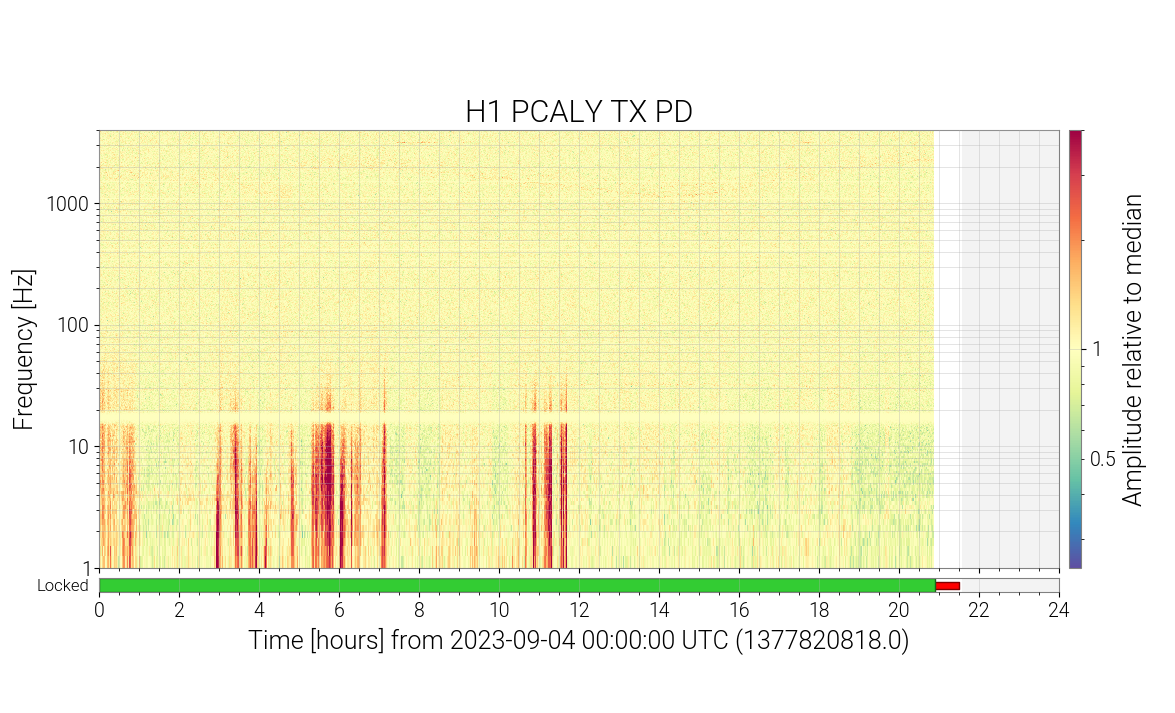
The noise that is described in this alog: 71725
This type of noise can be seen on summary pages for PCAL on many days, on both arms, at different times.
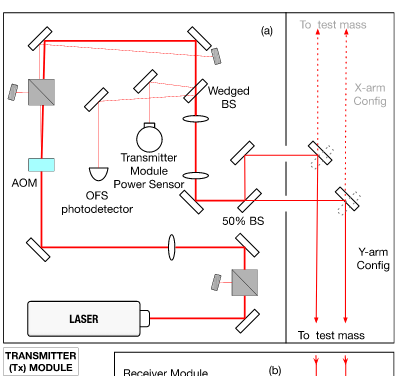
Looking at the Layout of the Transmitter module.
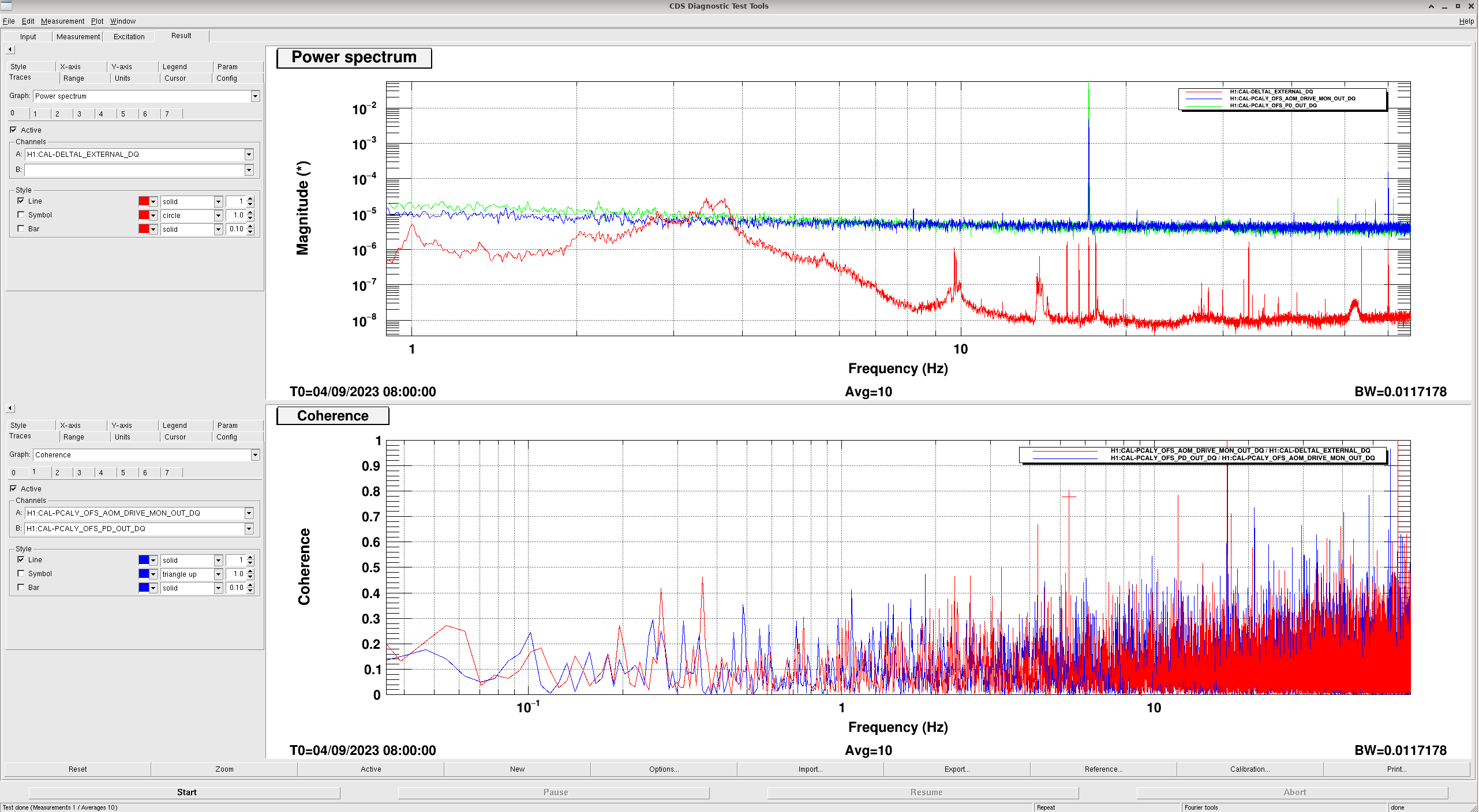
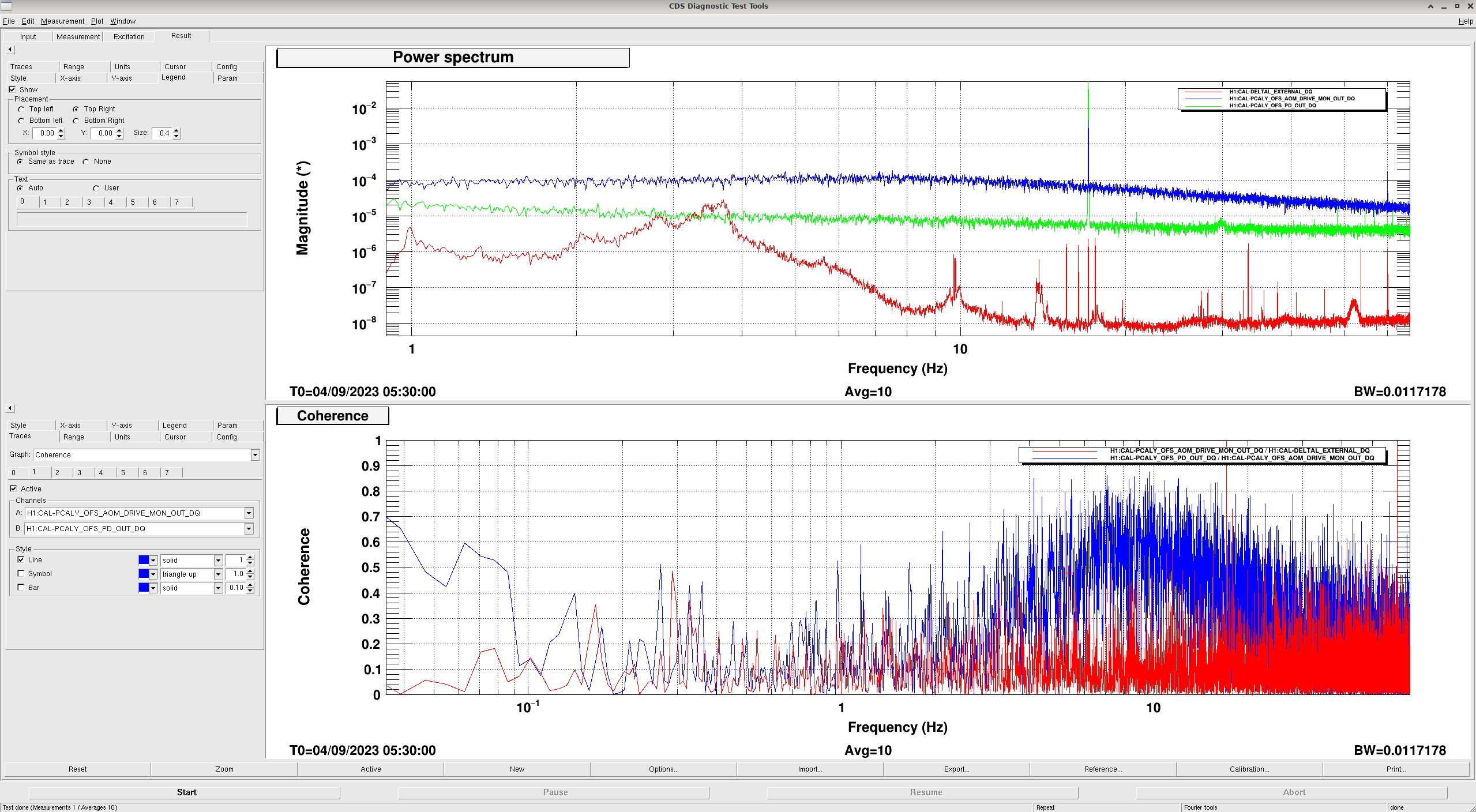
Because the noise can be seen on both the TxPD and OFSPD, this means that the source of the noise is up stream of the OFS and TxPD. Either the AOM or the LASER itself.
I took some Coherence and Power spectrum plots of the OFSPD and AOM DRIVE while the system was performing well at 08:00 UTC today.
And
I then took some Coherence and Power spectrum plots of the OFSPD and AOM DRIVE while the system was NOT performing well at 05:30 UTC today.
And
These were my settings.

TITLE: 09/04 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
OUTGOING OPERATOR: Tony
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 20mph Gusts, 16mph 5min avg
Primary useism: 0.04 μm/s
Secondary useism: 0.17 μm/s
QUICK SUMMARY:
IFO is in NLN and Observing as of 22:40UTC
TITLE: 09/04 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
INCOMING OPERATOR: Ibrahim
SHIFT SUMMARY:
20:32UTC Wind is gusting ar over 38 MPH now.
20:28UTC GRB-Short E435288 Canididate Standing down
Lockloss from NLN 20:53 UTC Due to motion pick up by the seismon.
Lockloss at LOCKING_ALS 21:13 UTC
Initial Alignment completed.
Lockloss at DHAR_WFS 21:58 UTC
NOMINAL_LOW_NOISE reached at 22:46 UTC
Observing reached at 23:02 UTC
LOG:
No Log
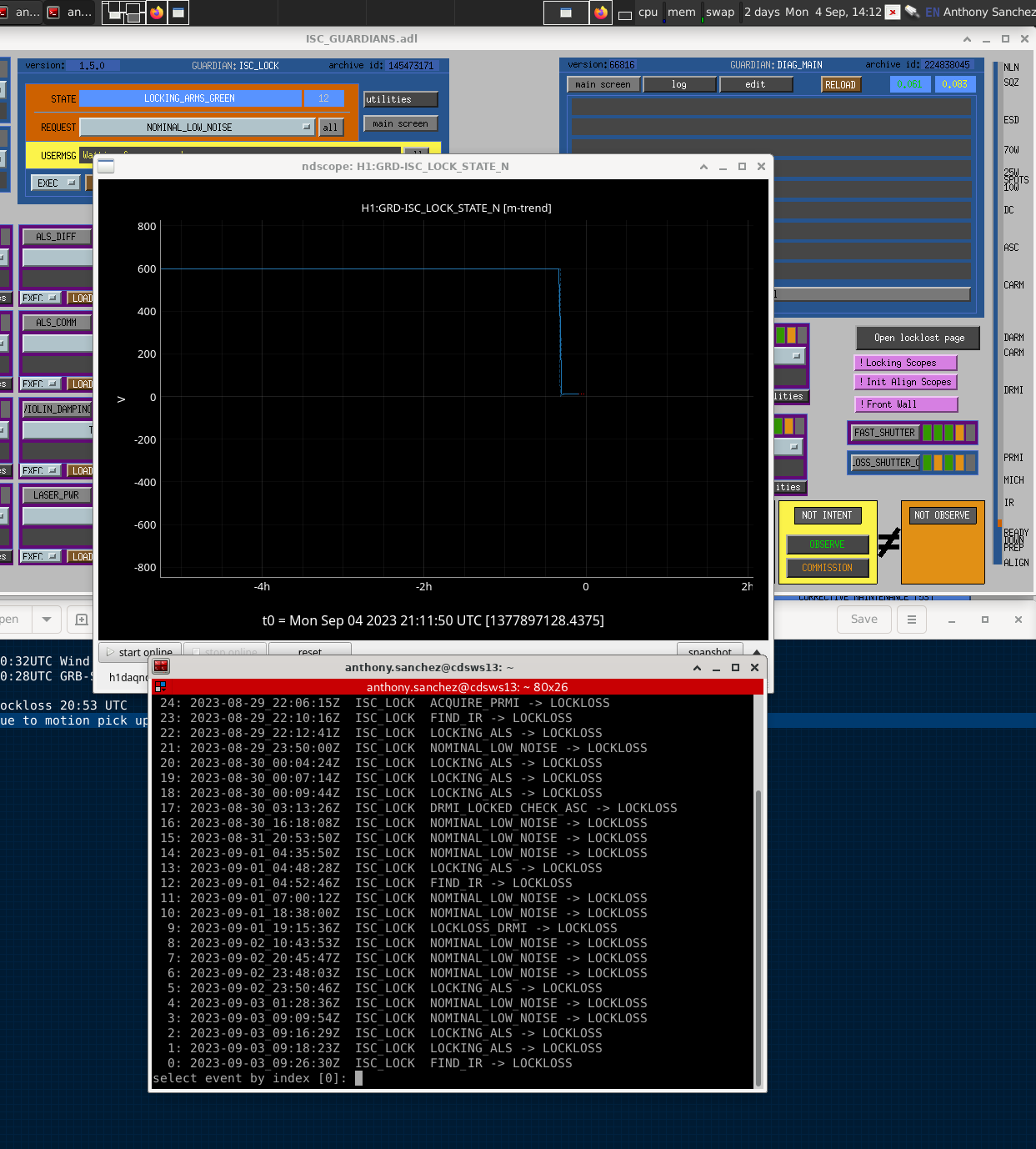
Lockloss select tool has stopped working for some reason. ScreenShot of the results of my lockloss select results only showing yesterdays locklosses.
That's unfortunate cause I really enjoy using that tool.
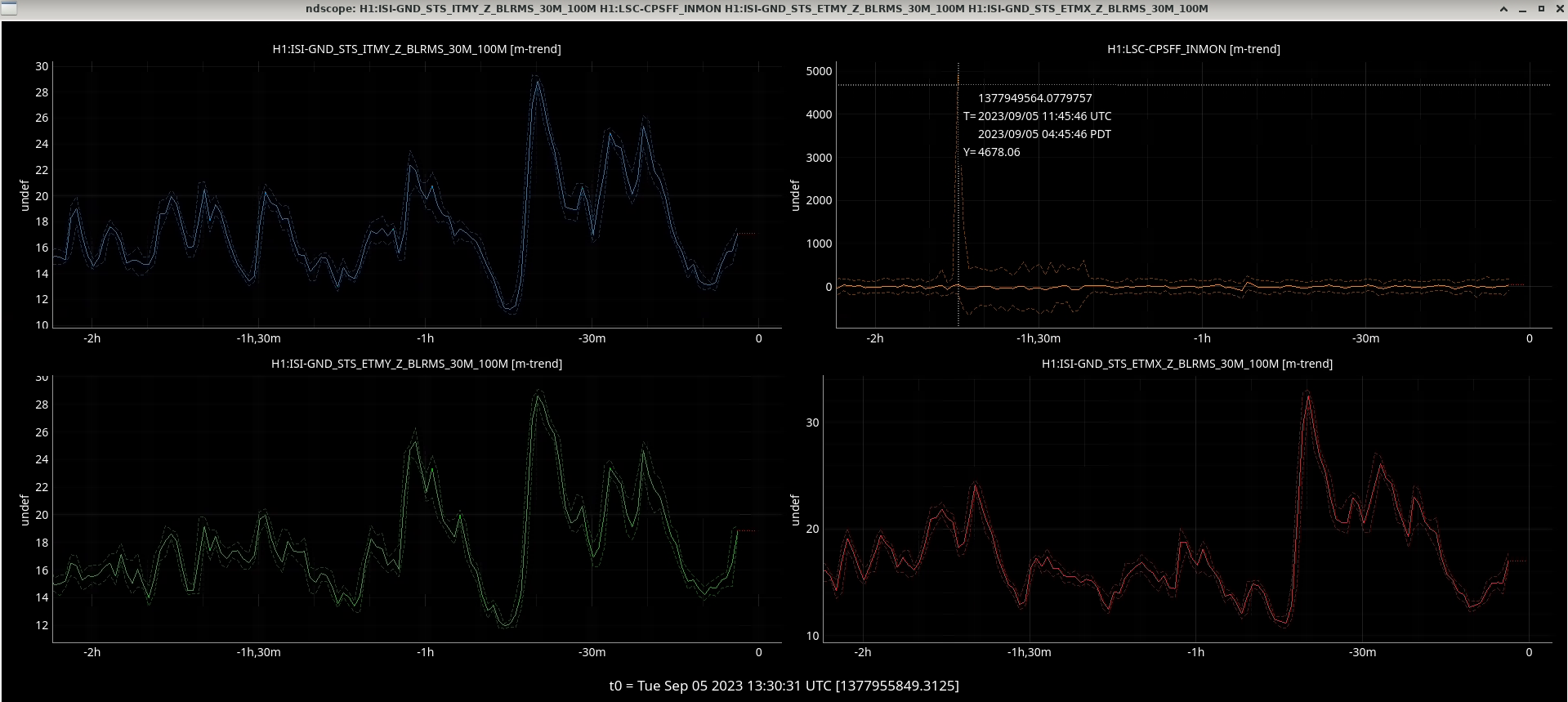
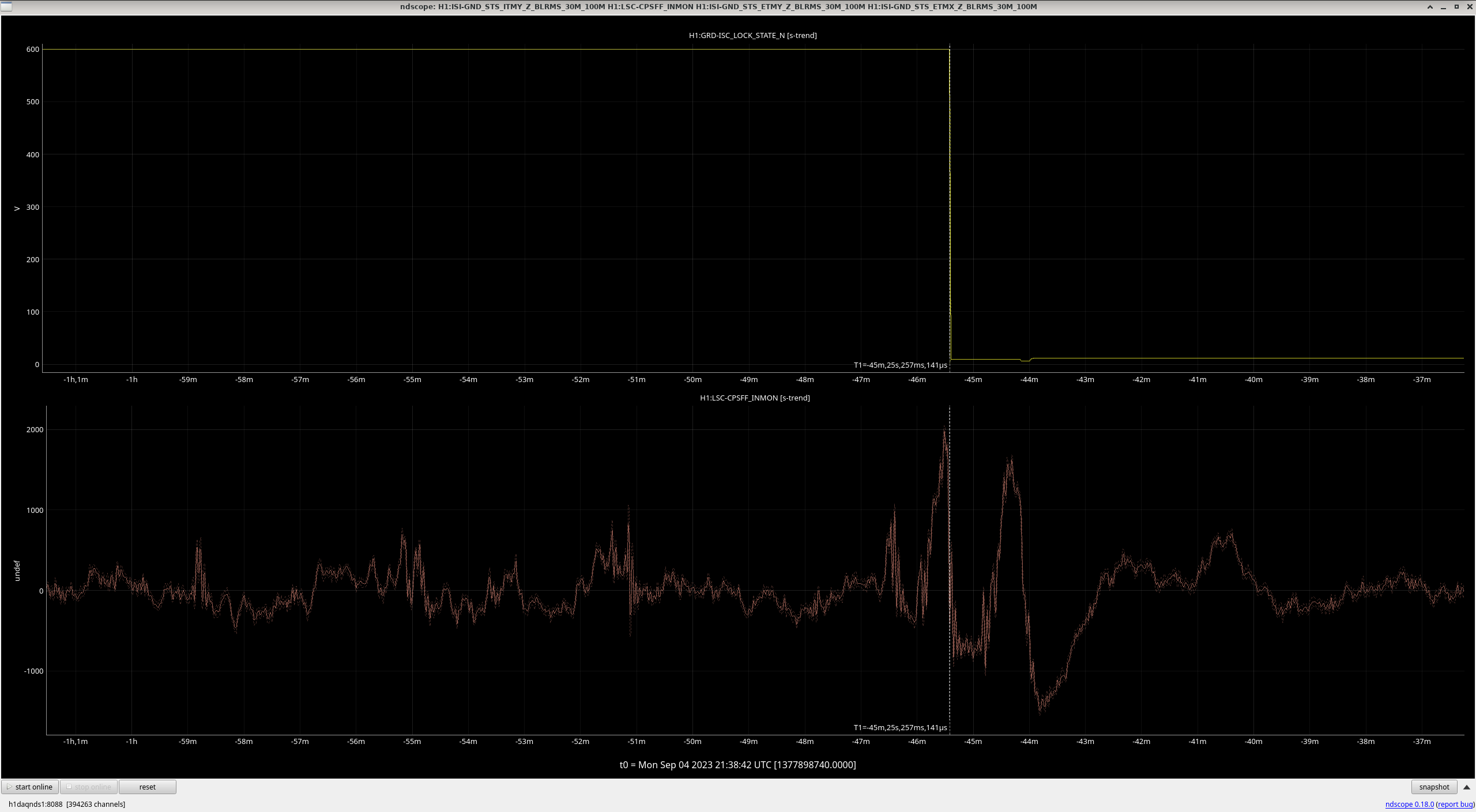
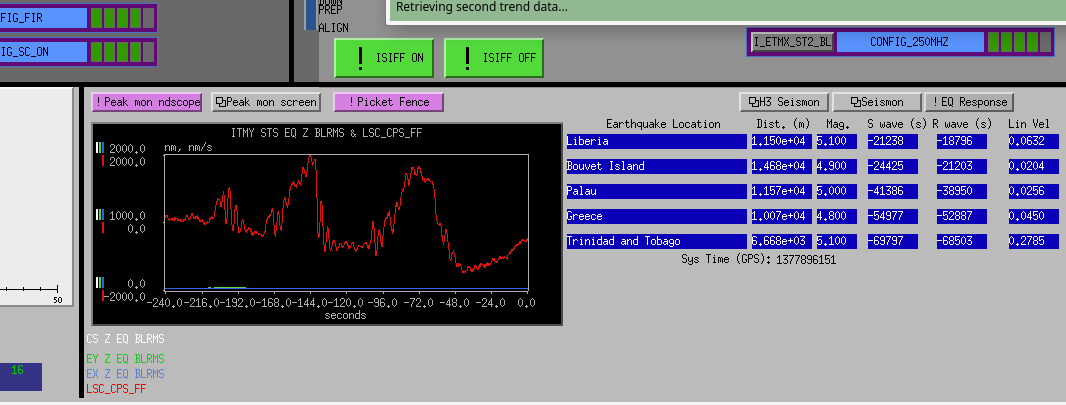
I happened to have the SEI ISI CONFIG screen up during the lockloss and snapped this screen shot.
Which started my hunt for ground motion that caused this lockloss.
I was able to get this screenshot though which shows an increase of ground motion from the LSC-CPSFF , an abrupt drop off and a corresponding lockloss at the same time.
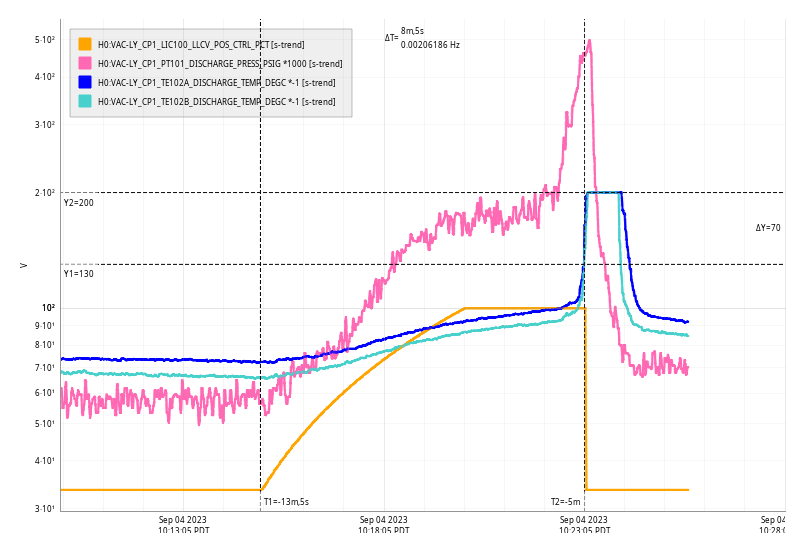
Mon Sep 04 10:23:05 2023 INFO: Fill completed in 8min 1secs
Fill did not run at 10:00:00 due to timing bug, I reconfigured it to run at 10:15:00 just for today.