2016-07-07_23:56:12.137560Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-PRCL_FM_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.138100Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.138900Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.142360Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_FM_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.146050Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_FM_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.150410Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-MCL_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.152560Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-MCL_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.254650Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_2_2 => 0
2016-07-07_23:56:12.255230Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_3_2 => 0
2016-07-07_23:56:12.261690Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_4_2 => 0
2016-07-07_23:56:12.137560Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-PRCL_FM_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.138100Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.138900Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.142360Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_FM_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.146050Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-SRCL_FM_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.150410Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-MCL_TRIG_THRESH_ON => -100
2016-07-07_23:56:12.152560Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-MCL_TRIG_THRESH_OFF => -100
2016-07-07_23:56:12.254650Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_2_2 => 0
2016-07-07_23:56:12.255230Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_3_2 => 0
2016-07-07_23:56:12.261690Z ISC_LOCK [DRMI_ON_POP.main] ezca: H1:LSC-TRIG_MTRX_4_2 => 0
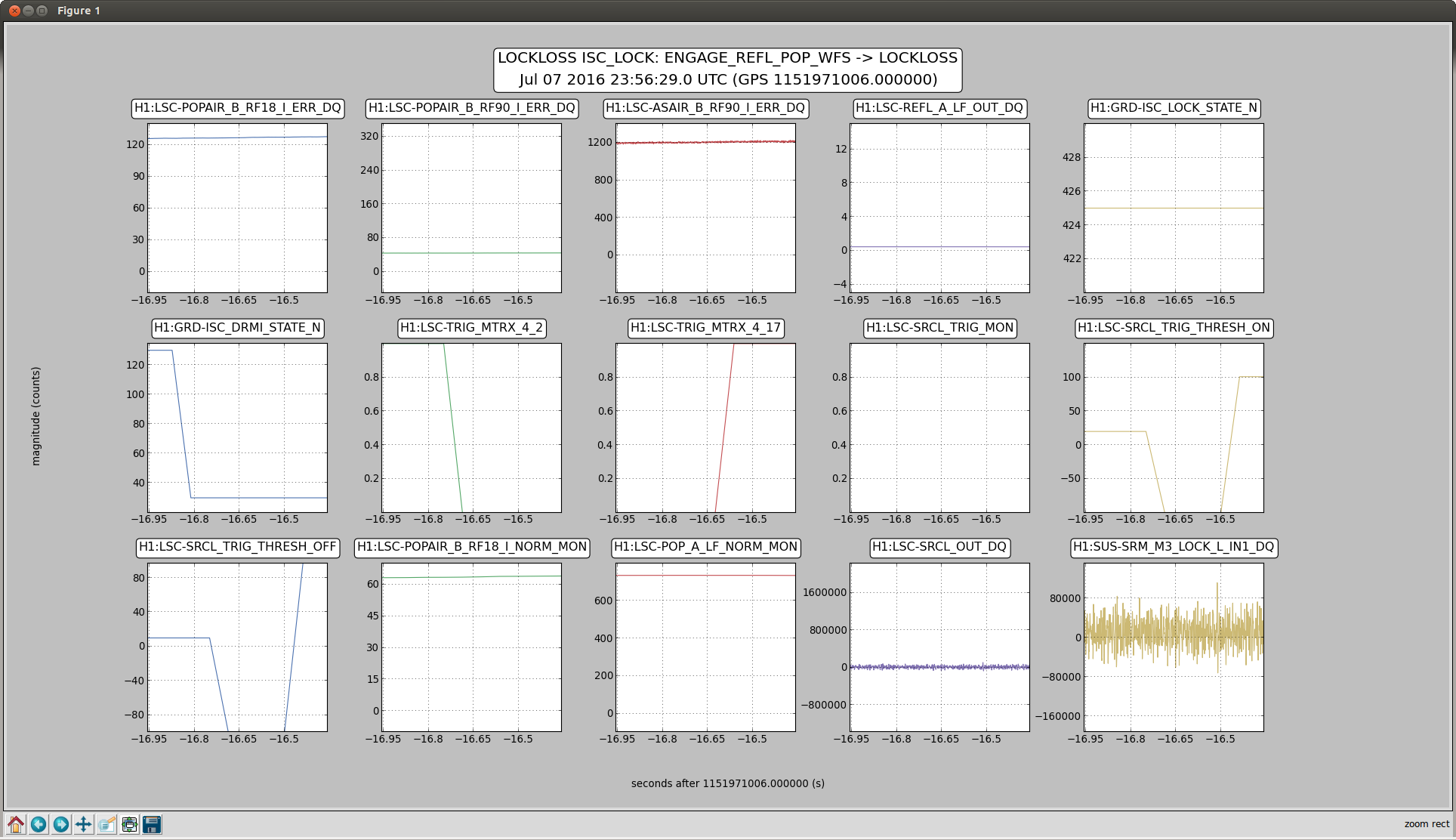
after this the ISC_LOCK guardian has a 0.1 second sleep while before restting the matrix elements. Durring this sleep, the ISC_DRMI guardian logs that SRCL was triggered off, although it seems like it should not have been according to the logic in the model and the values plotted in the attached screenshot. This is mystery number 1.
2016-07-07_23:56:12.263190Z ISC_DRMI [DRMI_3F_LOCKED.run] DRMI TRIGGERED NOT LOCKED:
2016-07-07_23:56:12.263210Z ISC_DRMI [DRMI_3F_LOCKED.run] LSC-MICH_TRIG_MON = 1.0
2016-07-07_23:56:12.263220Z ISC_DRMI [DRMI_3F_LOCKED.run] LSC-PRCL_TRIG_MON = 1.0
2016-07-07_23:56:12.263220Z ISC_DRMI [DRMI_3F_LOCKED.run] LSC-SRCL_TRIG_MON = 0.0
2016-07-07_23:56:12.263230Z ISC_DRMI [DRMI_3F_LOCKED.run] DRMI not Locked
2016-07-07_23:56:12.324180Z ISC_DRMI state returned jump target: LOCK_DRMI_1F
2016-07-07_23:56:12.324390Z ISC_DRMI [DRMI_3F_LOCKED.exit]
2016-07-07_23:56:12.324880Z ISC_DRMI STALLED
2016-07-07_23:56:12.386490Z ISC_DRMI JUMP: DRMI_3F_LOCKED->LOCK_DRMI_1F
2016-07-07_23:56:12.390010Z ISC_DRMI calculating path: LOCK_DRMI_1F->DRMI_3F_LOCKED
2016-07-07_23:56:12.390590Z ISC_DRMI new target: DRMI_LOCK_WAIT
2016-07-07_23:56:12.391260Z ISC_DRMI executing state: LOCK_DRMI_1F (30)
2016-07-07_23:56:12.391420Z ISC_DRMI [LOCK_DRMI_1F.enter]
In the attached screenshot, you can see that LSC-SRCL_TRIG_MON is never 0 according to the recorded data, but as Dave confirmed to us last time this happened, the recorded data is not necessarily the same as the data that the guardian recieves. However, the channel SUS-SRM_M3_LOCK_L_IN1_DQ is recorded at 2 kHz and should have been 0 if LSC-SRCL was not triggered, and we don't see anything like that happening in the screenshot. So was the SRCL trigger actually off, or is it possible that the epics data received by guardian thought it was triggered off when it was actually on. If SRCL was really triggered off, this could potentially cause locklosses.
After thinking that DRMI lost lock, the ISC_DRMI guardian makes a jump transition, and gets stalled as expected. But why does it continue on to try relocking DRMI (which is what ultimately caused the lockloss)? I don't think we are unstalling nodes anywhere in this state of ISC_LOCK, so it must be that the expected behavoir of a stalled node is to run the jump state and not continue after that?
Evan and I extended the sleep between steps of the triggering transition to 0.2 seconds rather than 0.1 but since I don't understand why this happened, I'm not sure that will fix the problem. We can create an IDLE state of the DRMI guardian which will not check for locklosses, that would prevent this bug from causing locklosses but doesn't address the more disturbing problems. Hopefully someone can help us understand why the data recieved by the guardian doesn't seem to agree with what we expect to happen based on the triger logic, or what the recorded data (even the fast data) seems to indicate happened.