Ryan C., Ibrahim, Austin
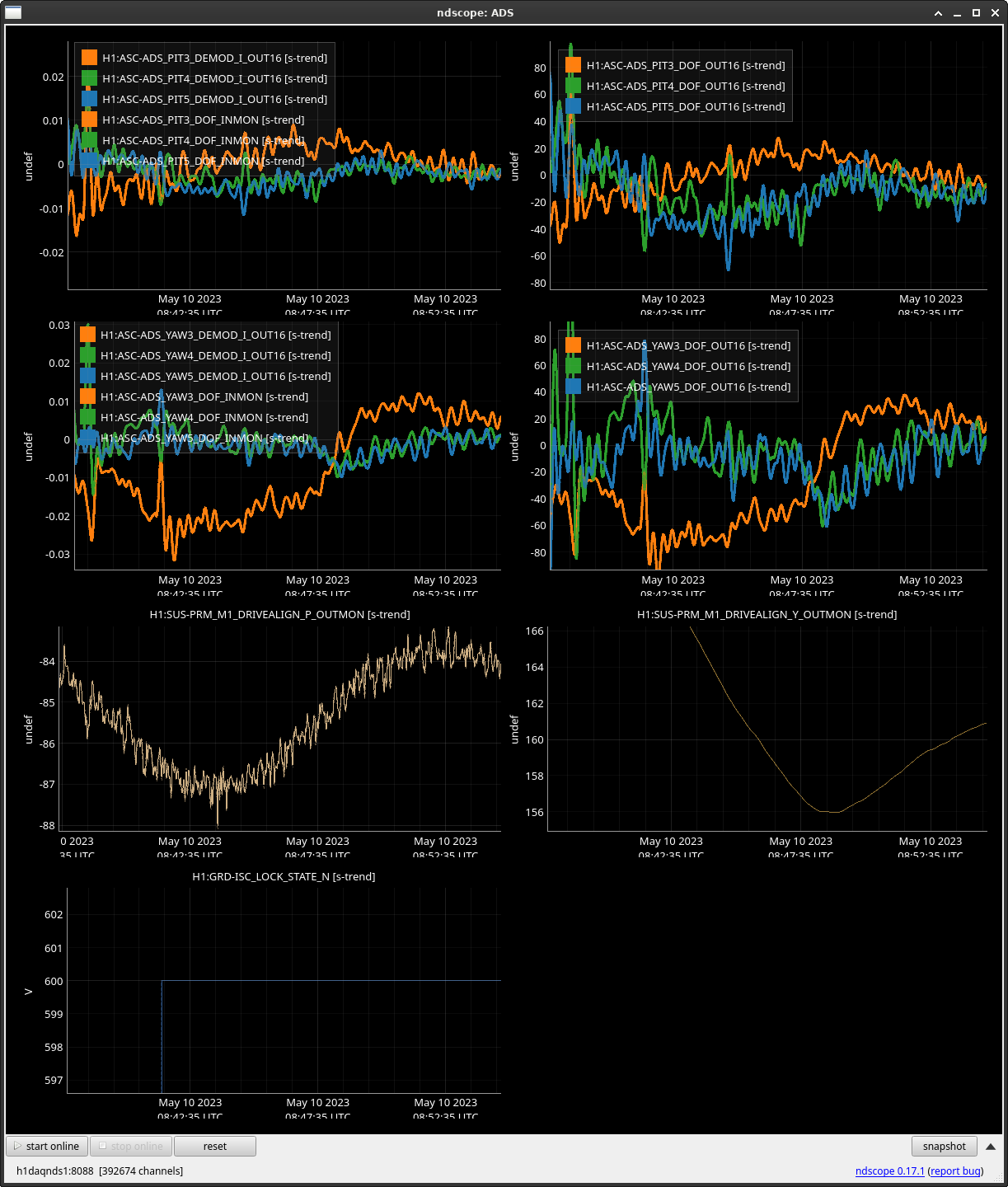
This alog is a follow up to a previous log showing that in every acquisition of NLN, particularly about 7/8 mintues in, the ADS will suddenly drift and signals (most prominent in ADS YAW 3) will start to diverge, and prevent us from going into OBSERVING for ~15 minutes per lock. The magnitude of this drift varies depending on each lock acqusition, but this has been a consistent issue for a while now. With the help of Ryan C and Ibrahim, here are our updates findings/what we looked into.
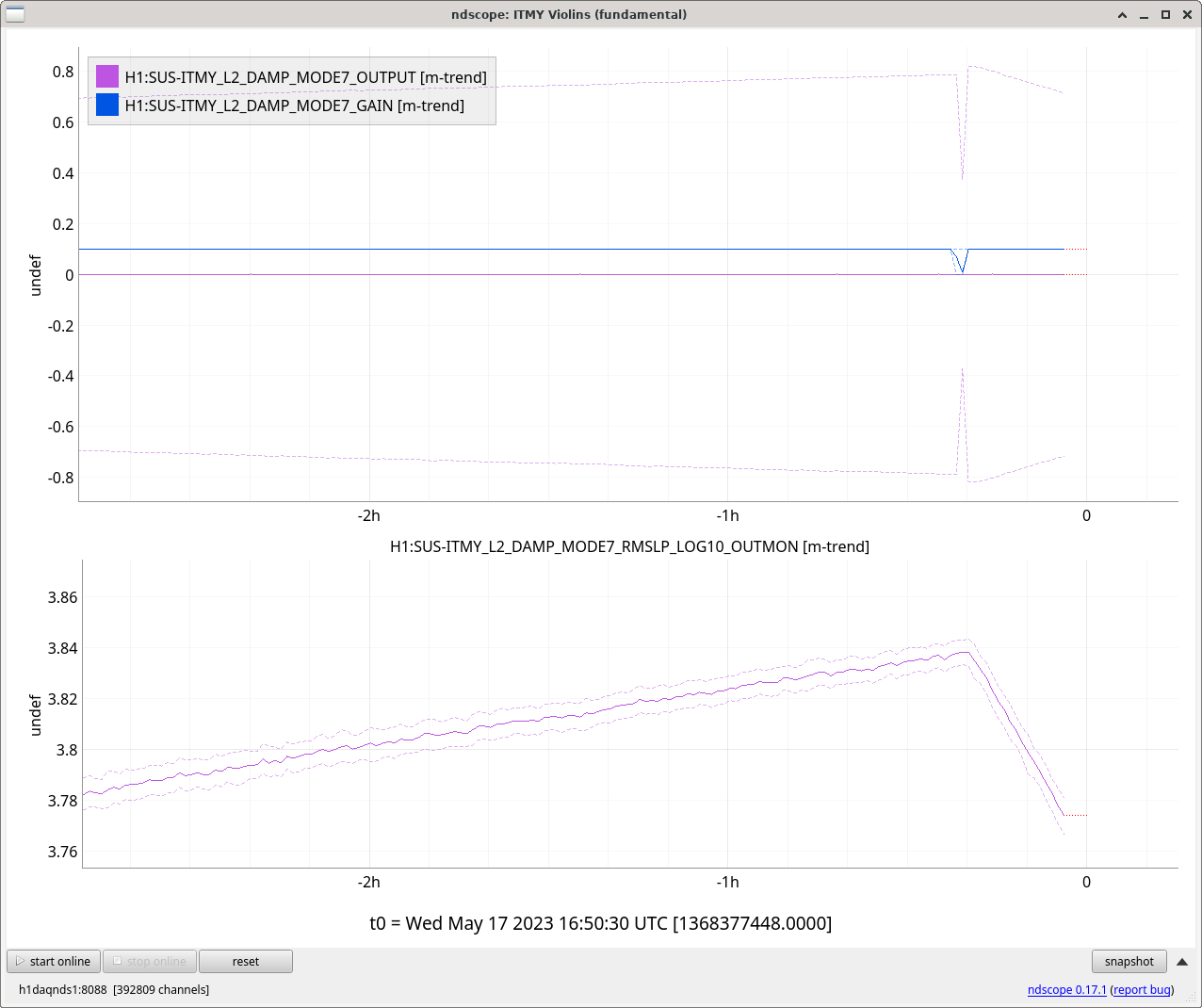
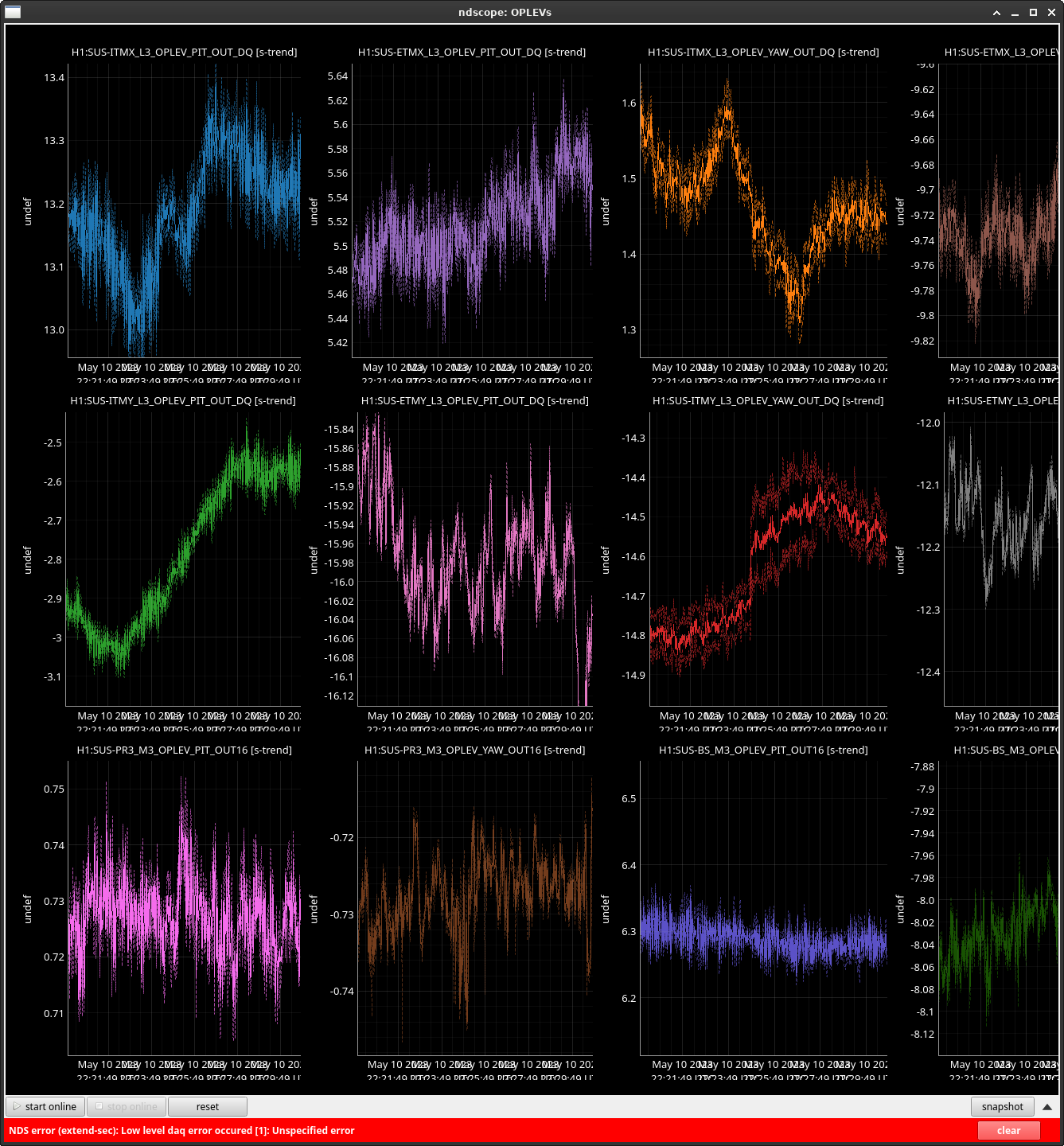
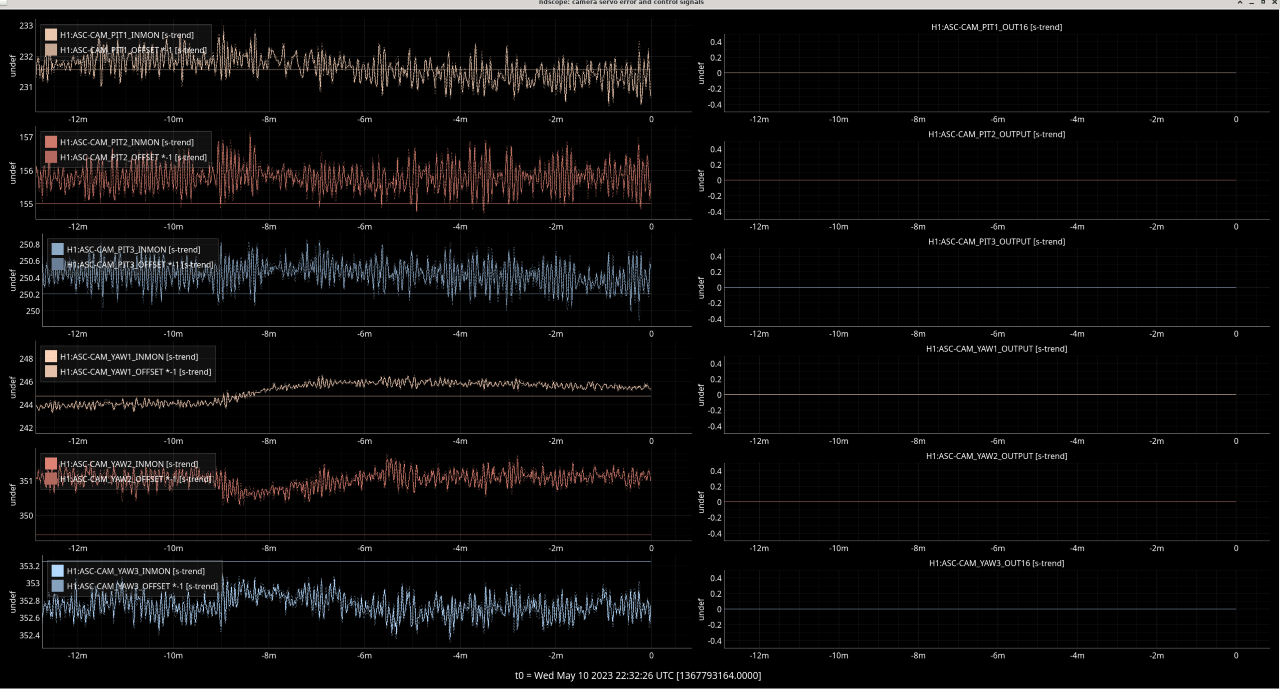
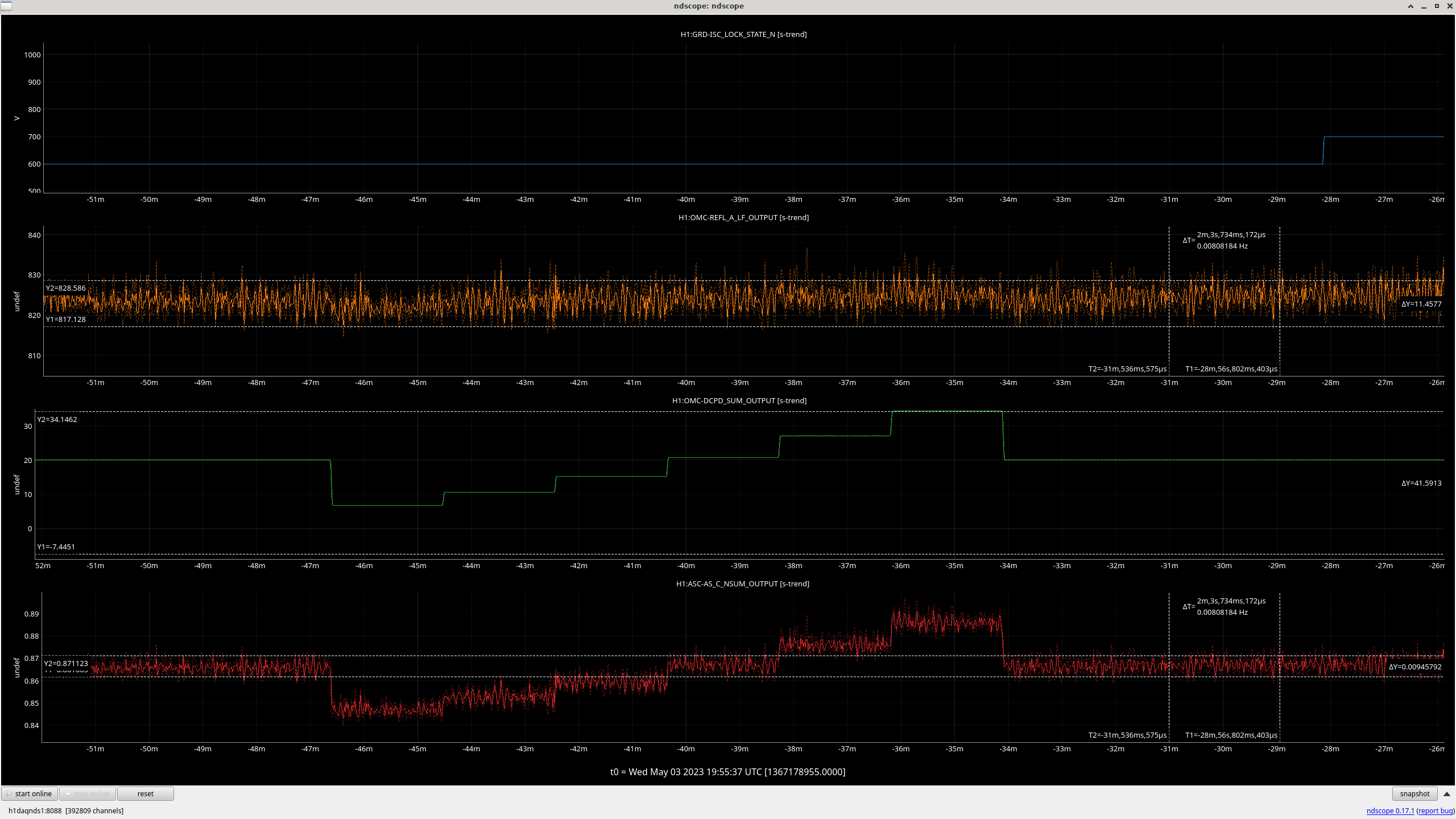
We decided to watch a "live" version of this drift when we acquired NLN and decided to trend a myriad of channels of anything we thought could be worth looking into namely: all oplevs (with the exception of SR3) - screenshot attached - (sorry for x axis looking terrible I couldn't get the scale right), ASC CAMERA SERVO/ERROR signals - screenshot attached, PRM/IM4 witness sensors (based off our findings from the previous log, we were curious how much these suspensions were moving, spoiler - not a whole lot), LSC PRC1, and ASC PRC 2. When reviewing all of these channels when an ADS kick occurred, most checked out ok, but I have attached the CAMERA SERVO error signals as that did move a bit, but not by much.
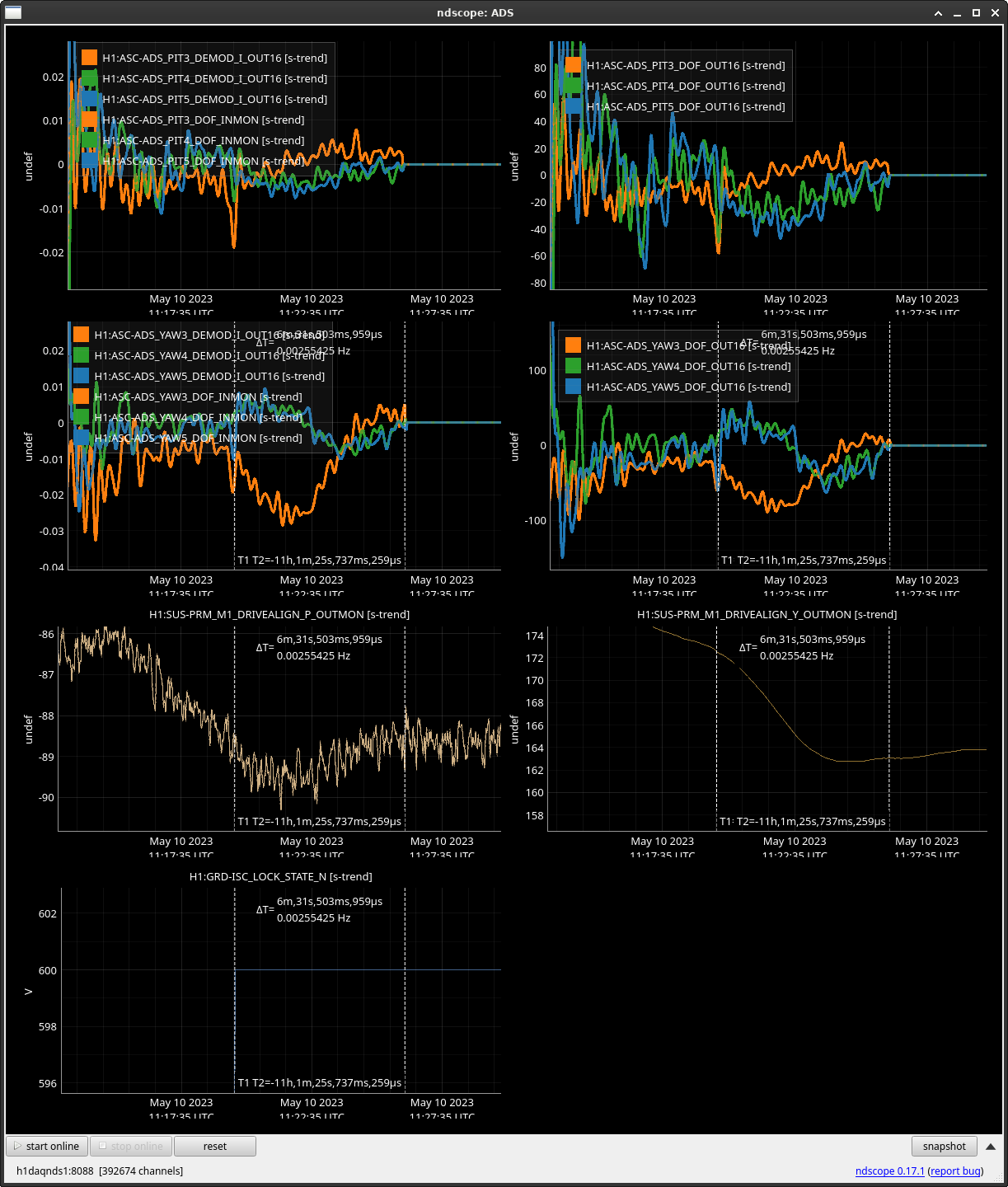
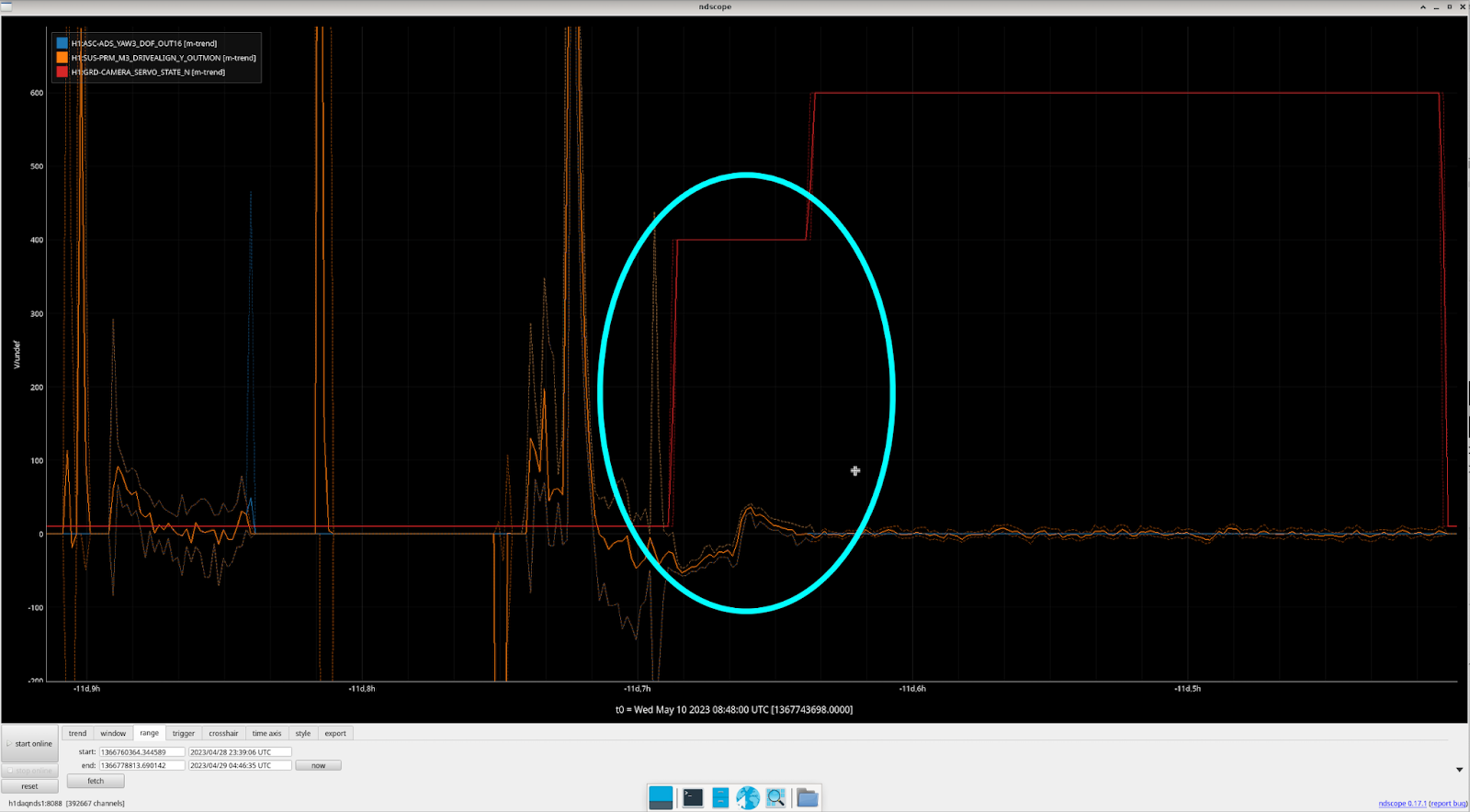
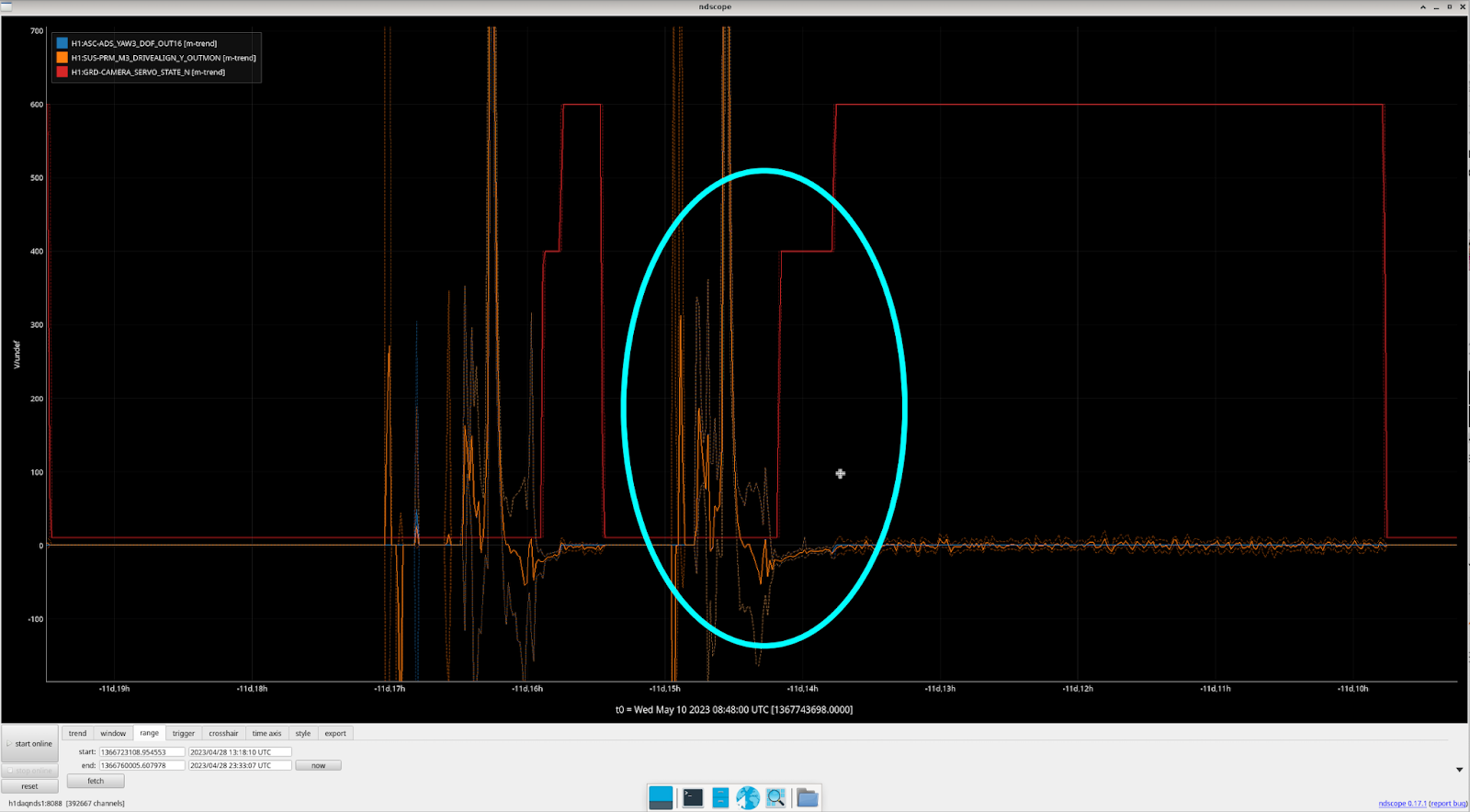
We then looked directly in the PRM suspension and tried to find any clues, and it turns out we found something interesting. We found that the PRM DRIVE ALIGN M1/M3 stages behave in the exact same fashion as the ADS drift (ss 1 / 2). Is this expected? Might be, since we know that ADS YAW 3 feeds directly into PRM. But we thought it was worth noting here.
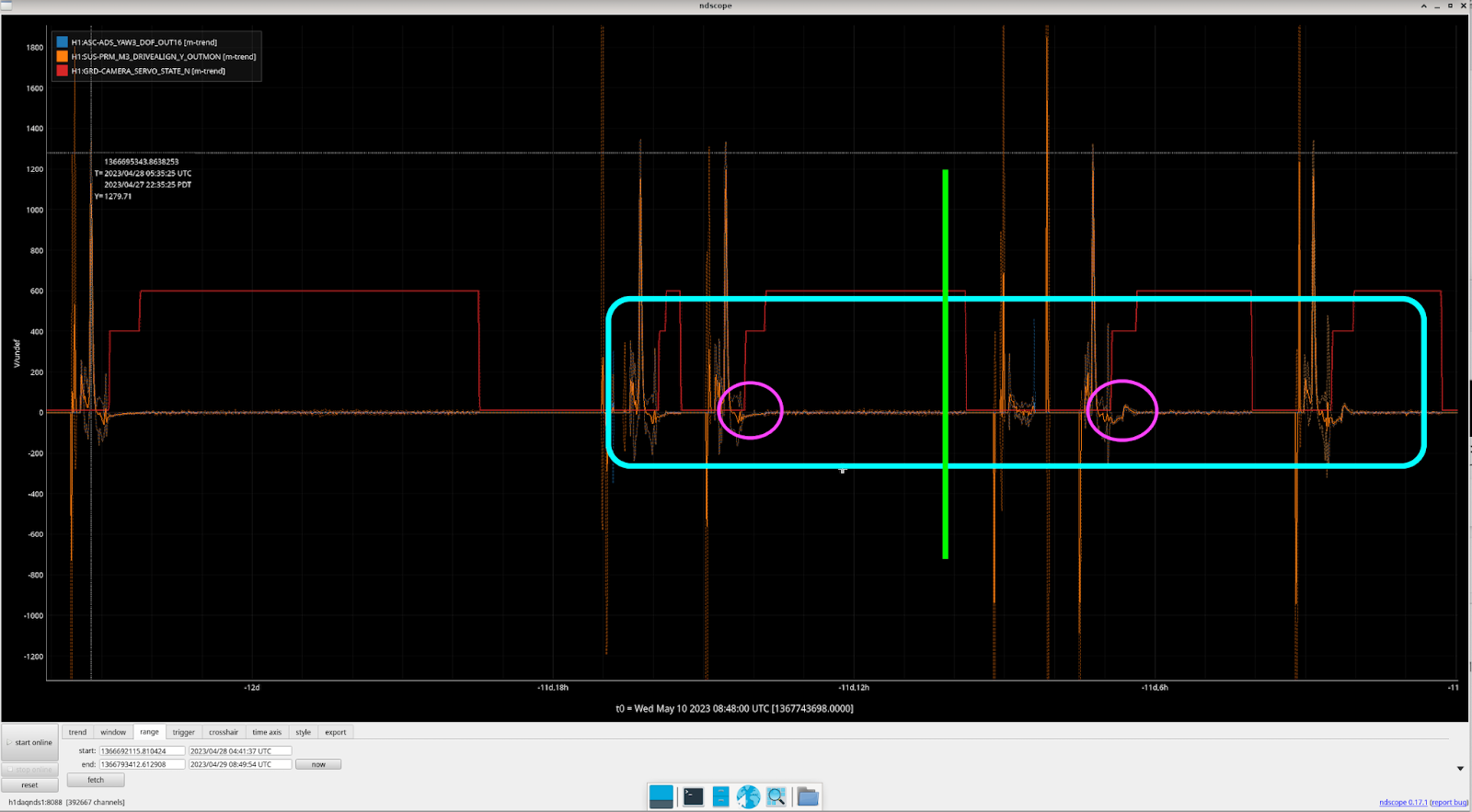
In addition, we found something regarding the CAMERA_SERVO guardian. When the CAMERA_SERVO guardian is in state 400 - TURN_CAMERA_SERVO_ON, the issue seems to be most apparent (screenshot). This coincides with the CAMERA guardian and to us makes sense since in that state, many of the ADS settings are changed. However, there does sometimes appear to be some movement (a "dip") before the CAMERA_SERVO guardian actually gets to this state (which can be seen here). If this "dip" feature is causing the drift that we've been seeing it might not be the CAMERA_SERVO guardian since these dips happens when the guardian is in DOWN and not doing any actuation. But, it could be entirely possible that this dip feature is just a red herring too and is a biproduct of the ADS converging. But maybe worth looking into.
So when did this problem start? After trending back a couple weeks and looking at every NLN acquisition, we found that this issue started around April 28th. From the image, you can see that on the lock acquisitions before the 28th, things were mostly quiet and there were no kicks/dips on the drive align signal. But afterwards, it becomes apparent that something has changed. After doing some alog digging around this time, I saw that there was a change to the ADS gains - alog here, acutal changes can be seen here (the change was made on 4/28, but was not committed to svn until 5/6). Though, I'm not entirely convinced this is the culprit, but it might be worth to see what the ADS signals would look like at a NLN lock if we reverted these gain values.
With all this in mind, we plan to take some next steps into narrowing down the issue, by looking more into the CAMERA_SERVO guardian code, figuring out why the kick happens specifically 8 minutes into a lock, and finding other correlated signals that we might have missed (though after seeing what we saw for the better part of the past week, I'm leaning towards the issue being related to the CAMERA guardian). Stay tuned!




















{kind=link}