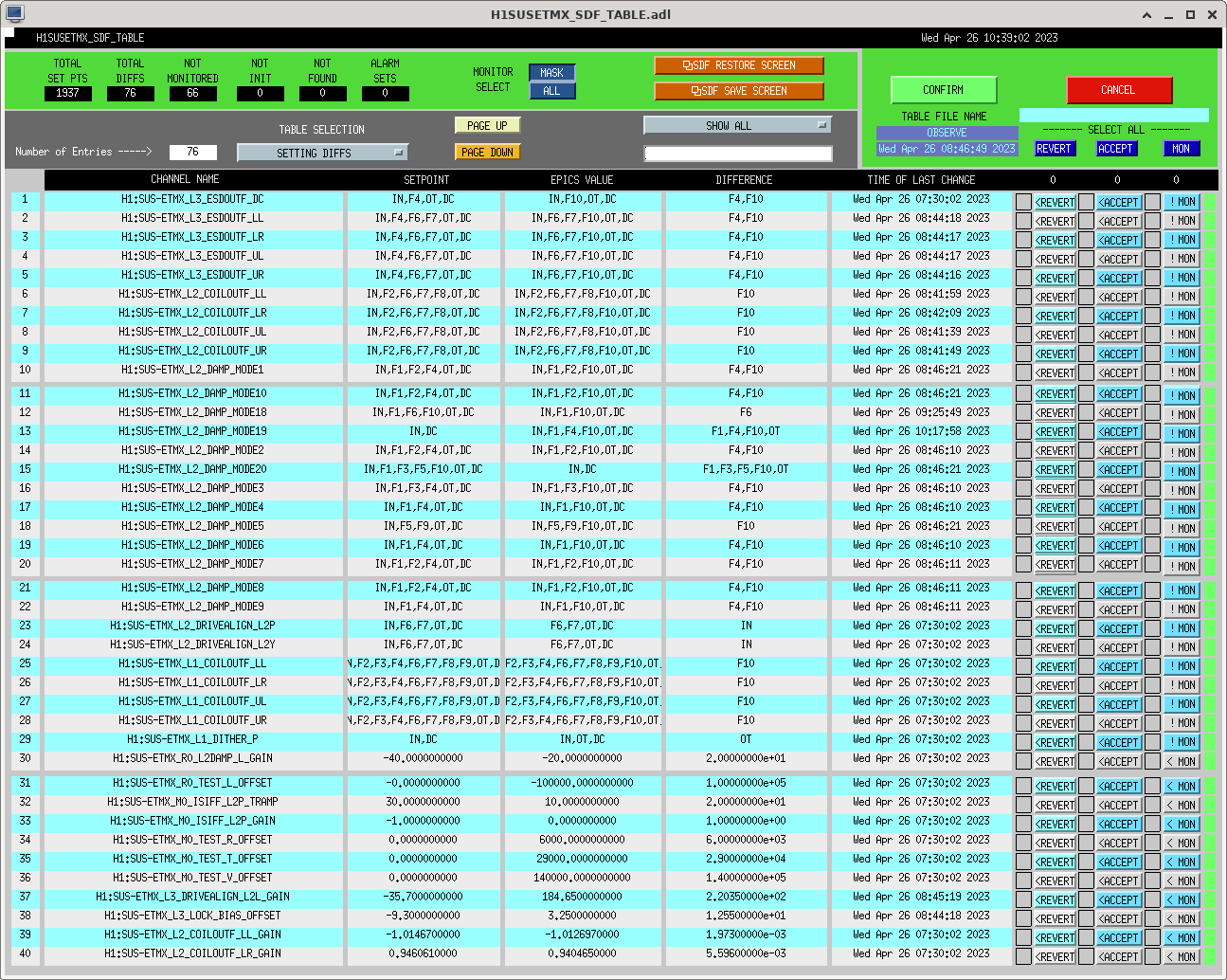
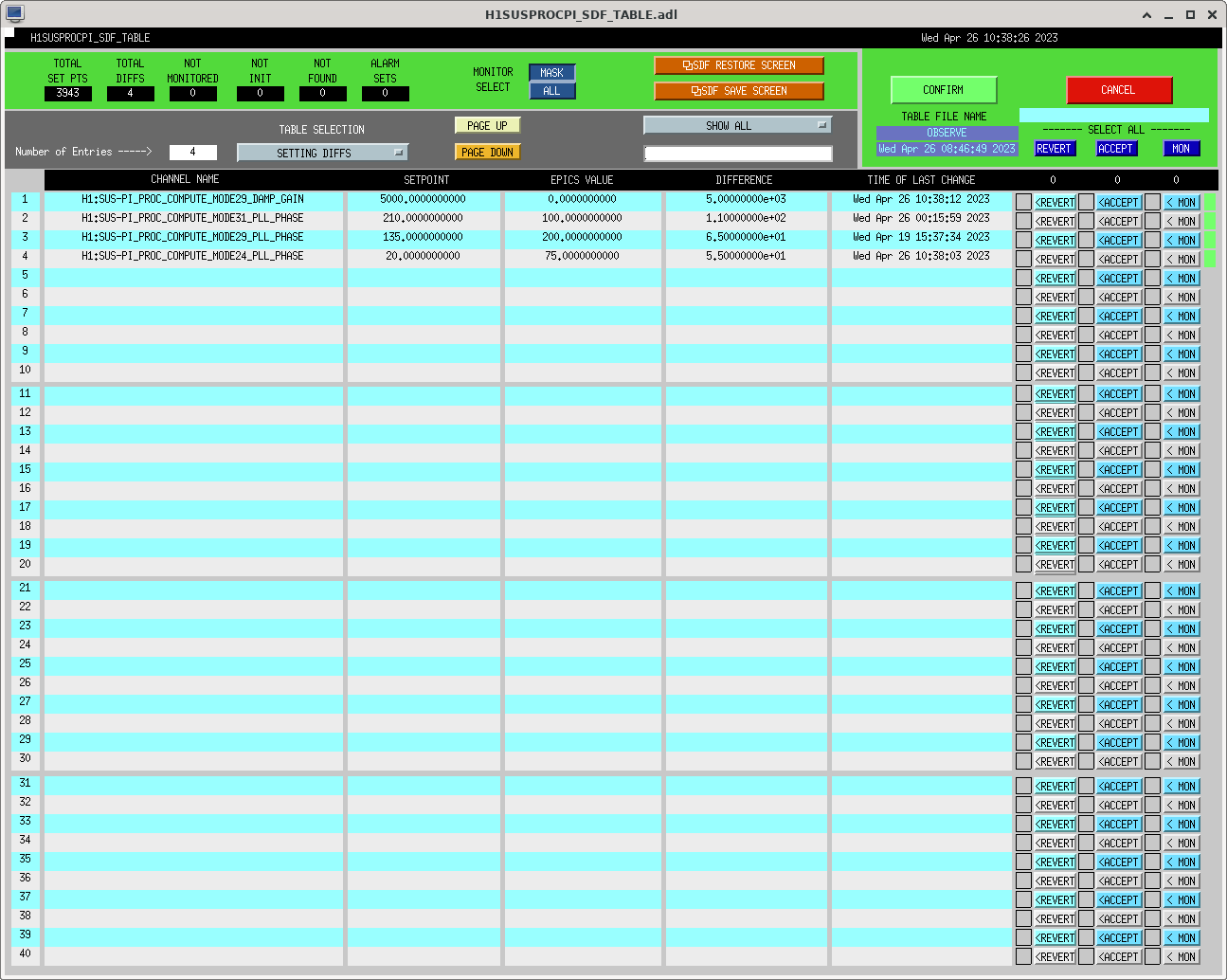
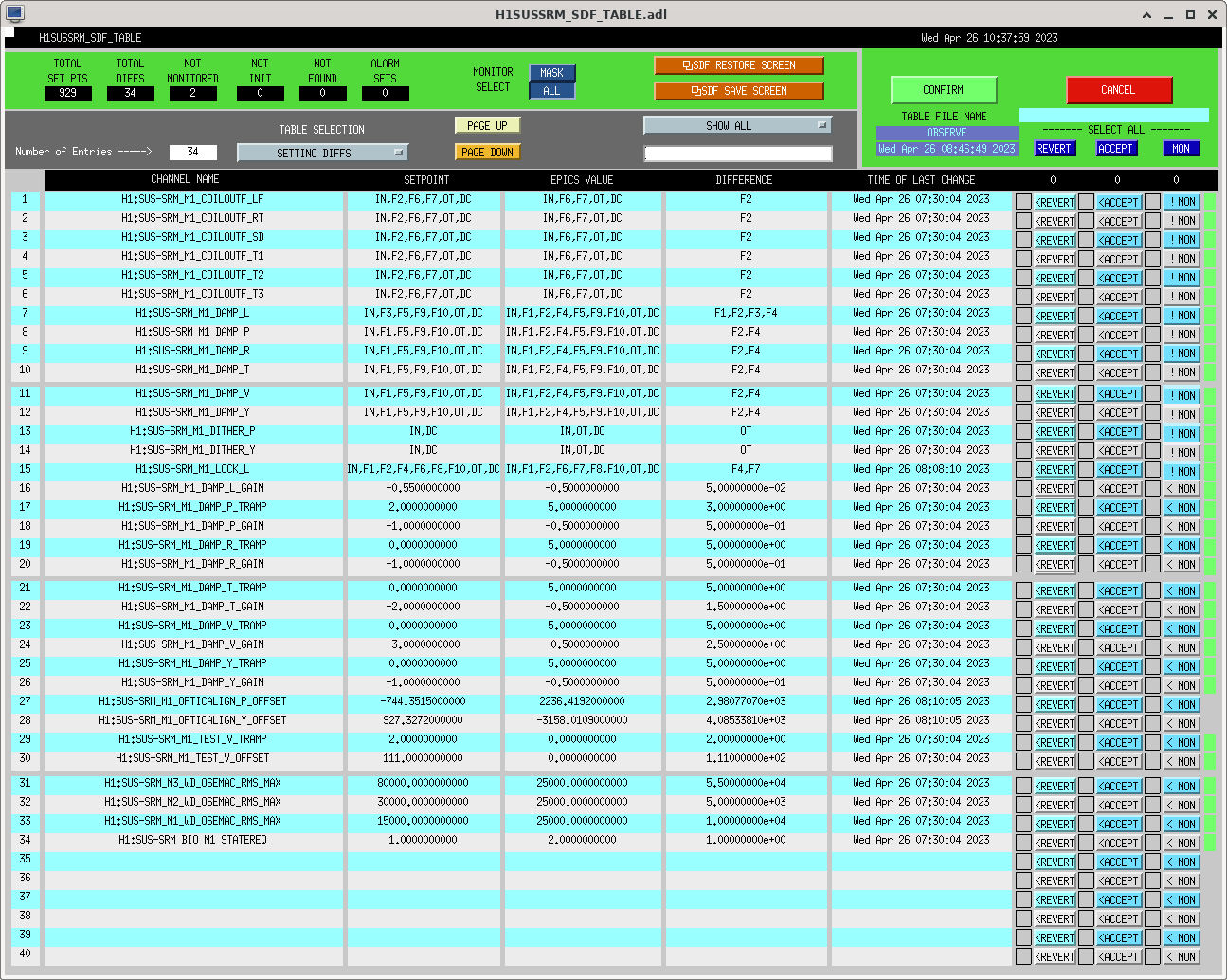
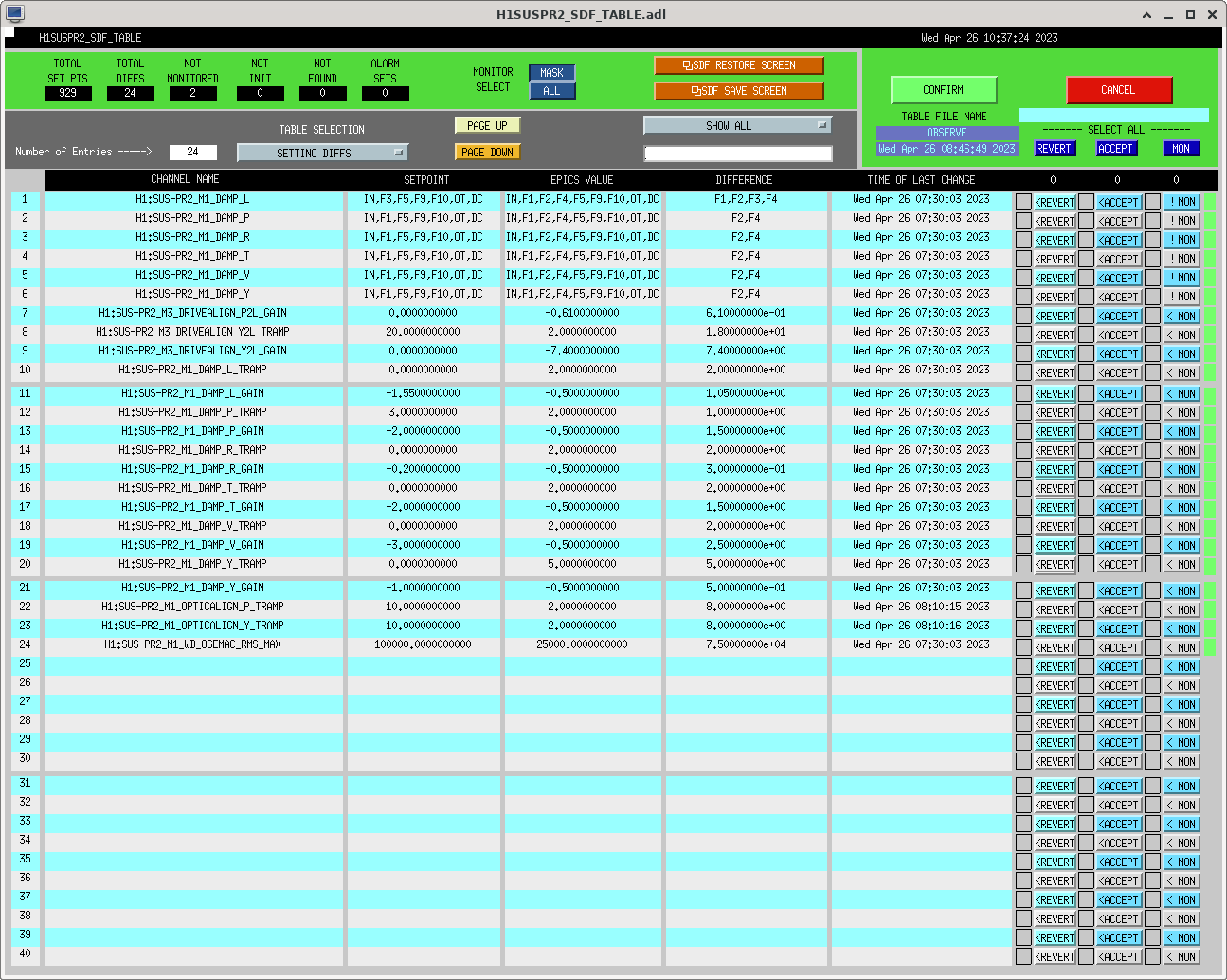
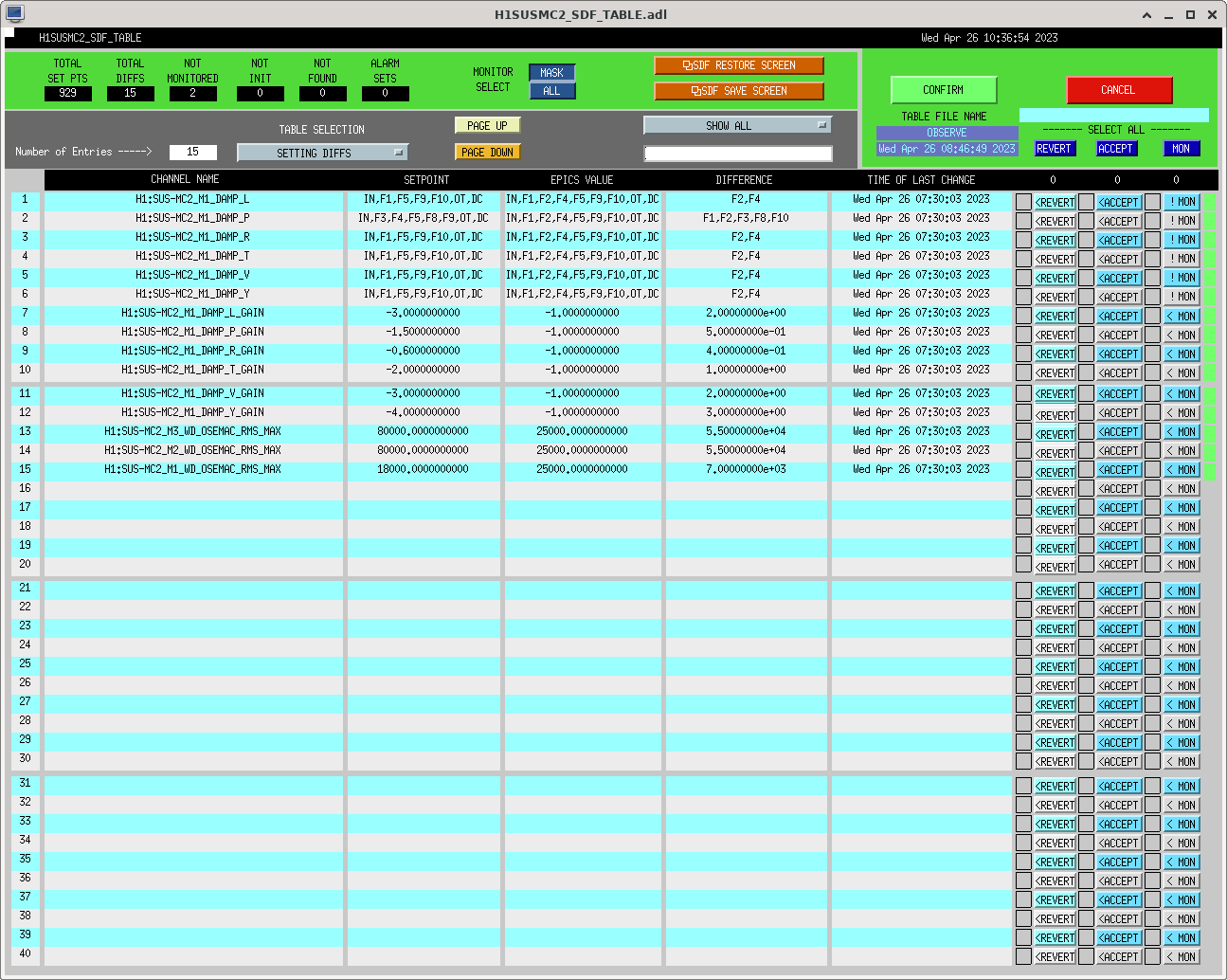
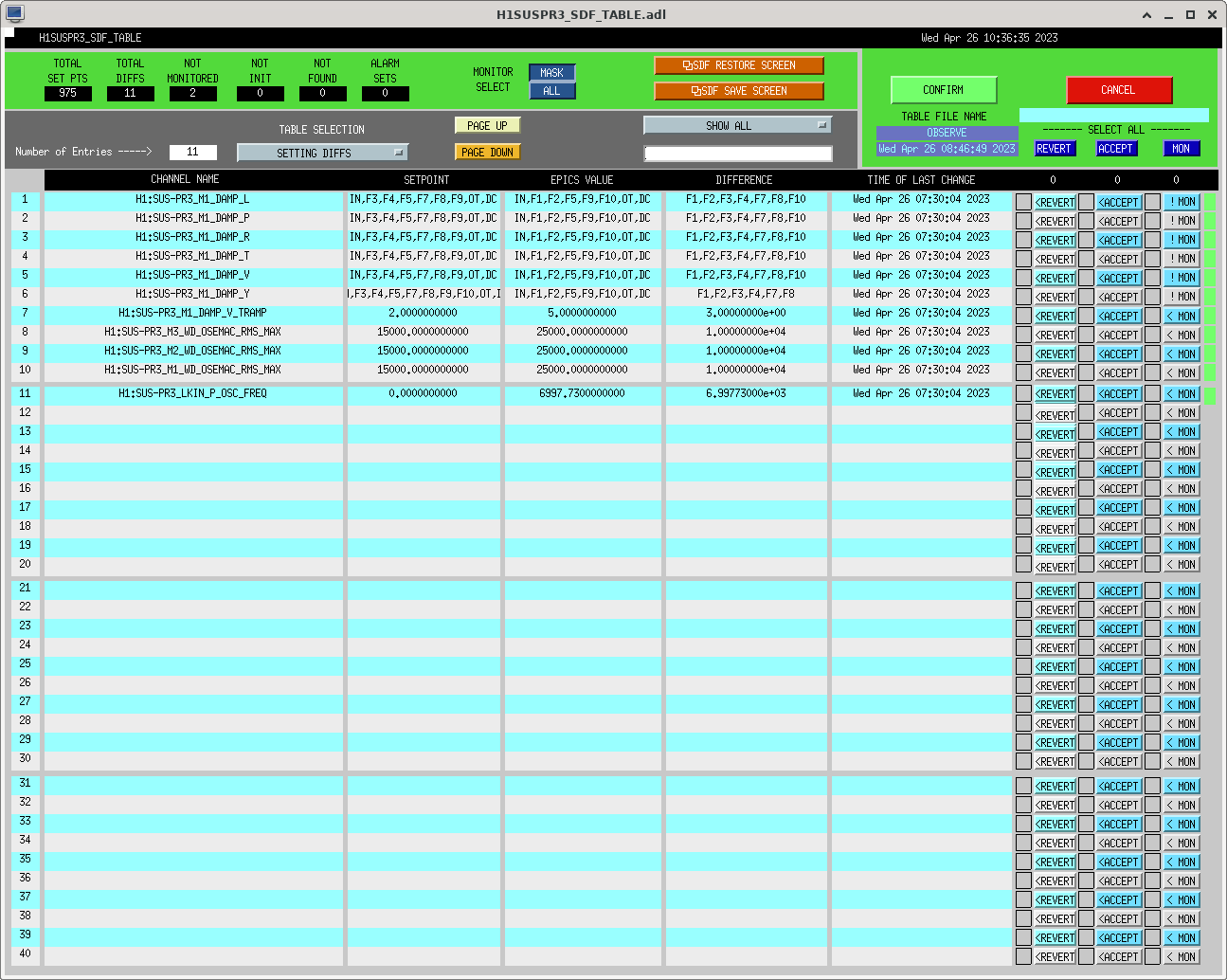
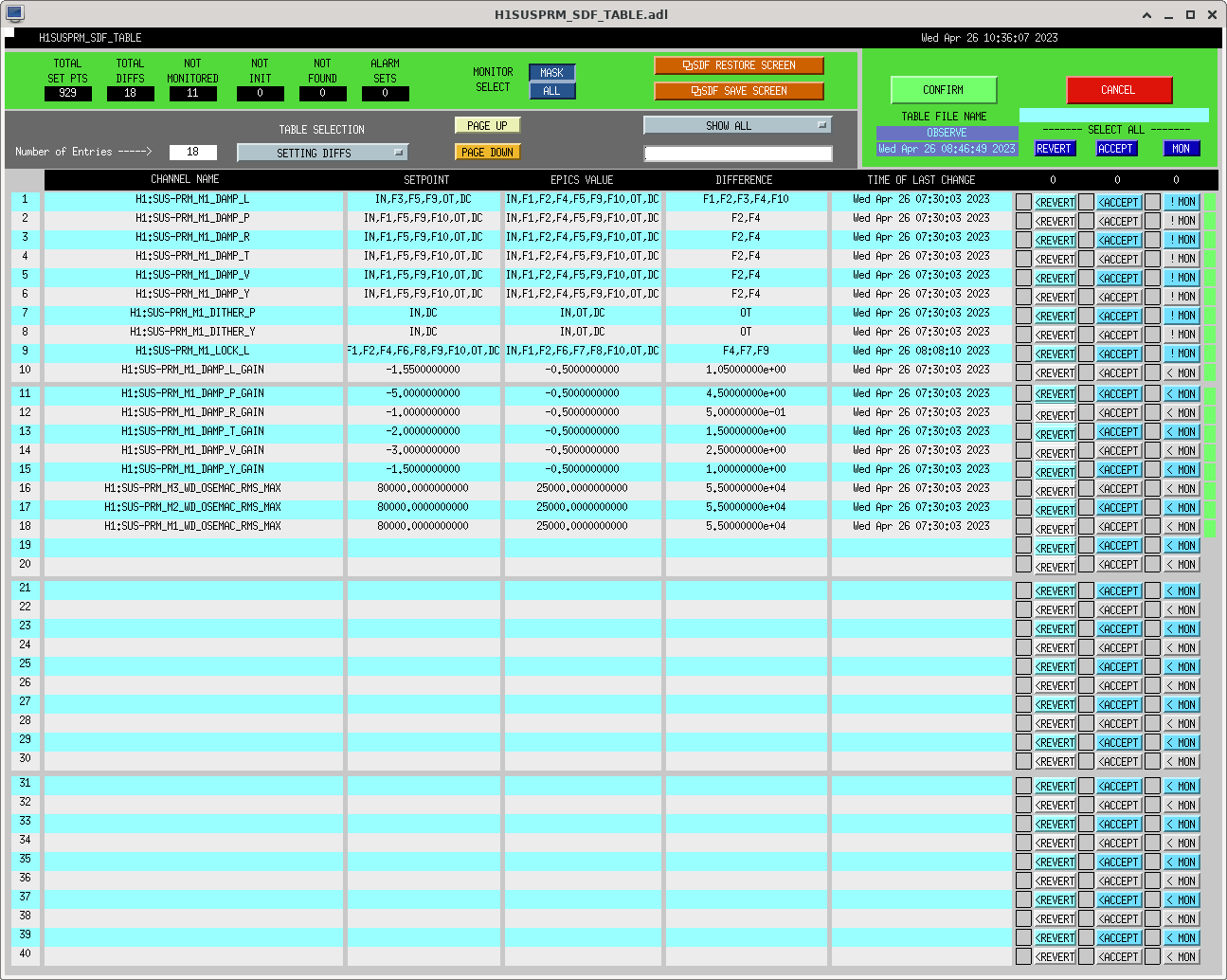
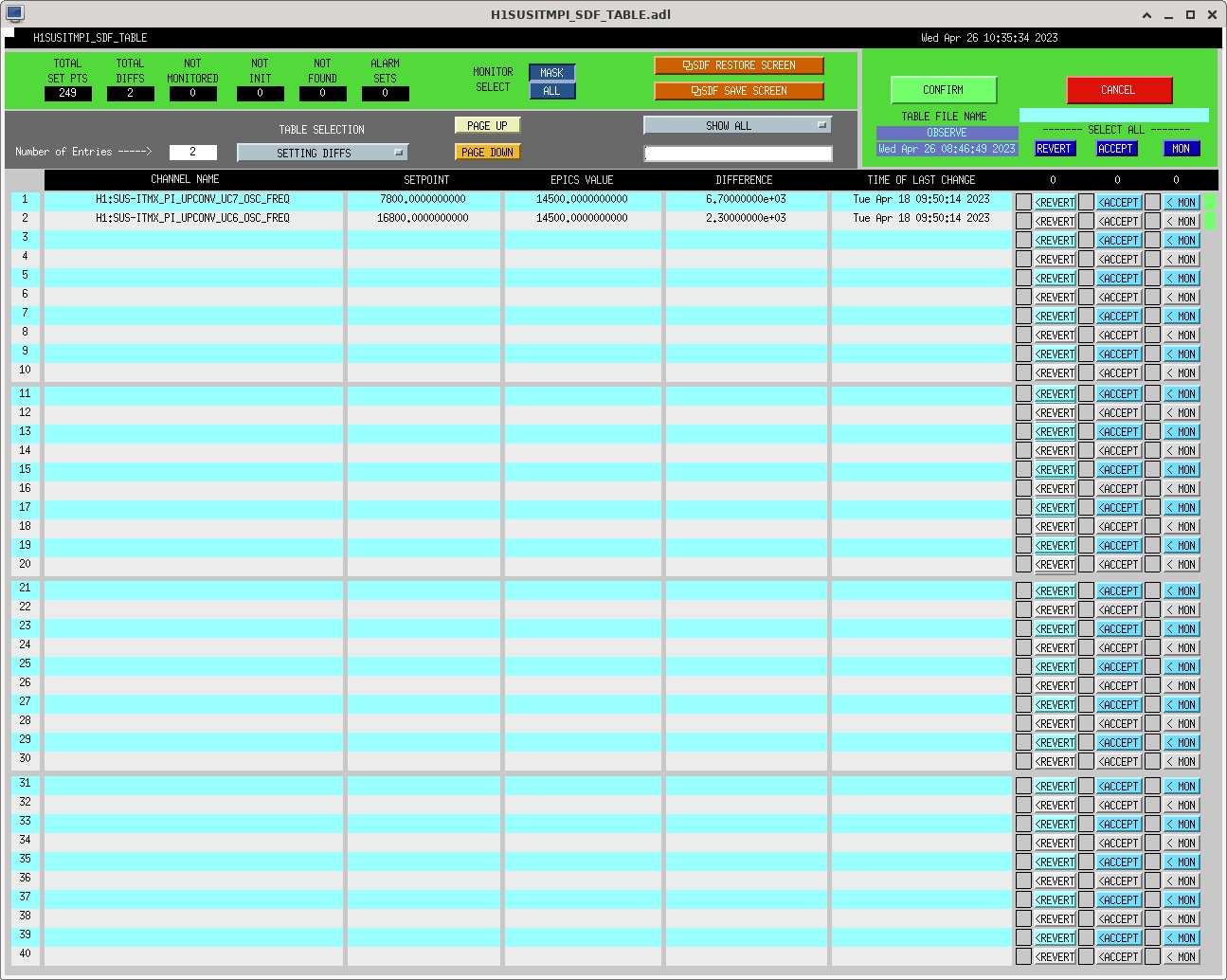
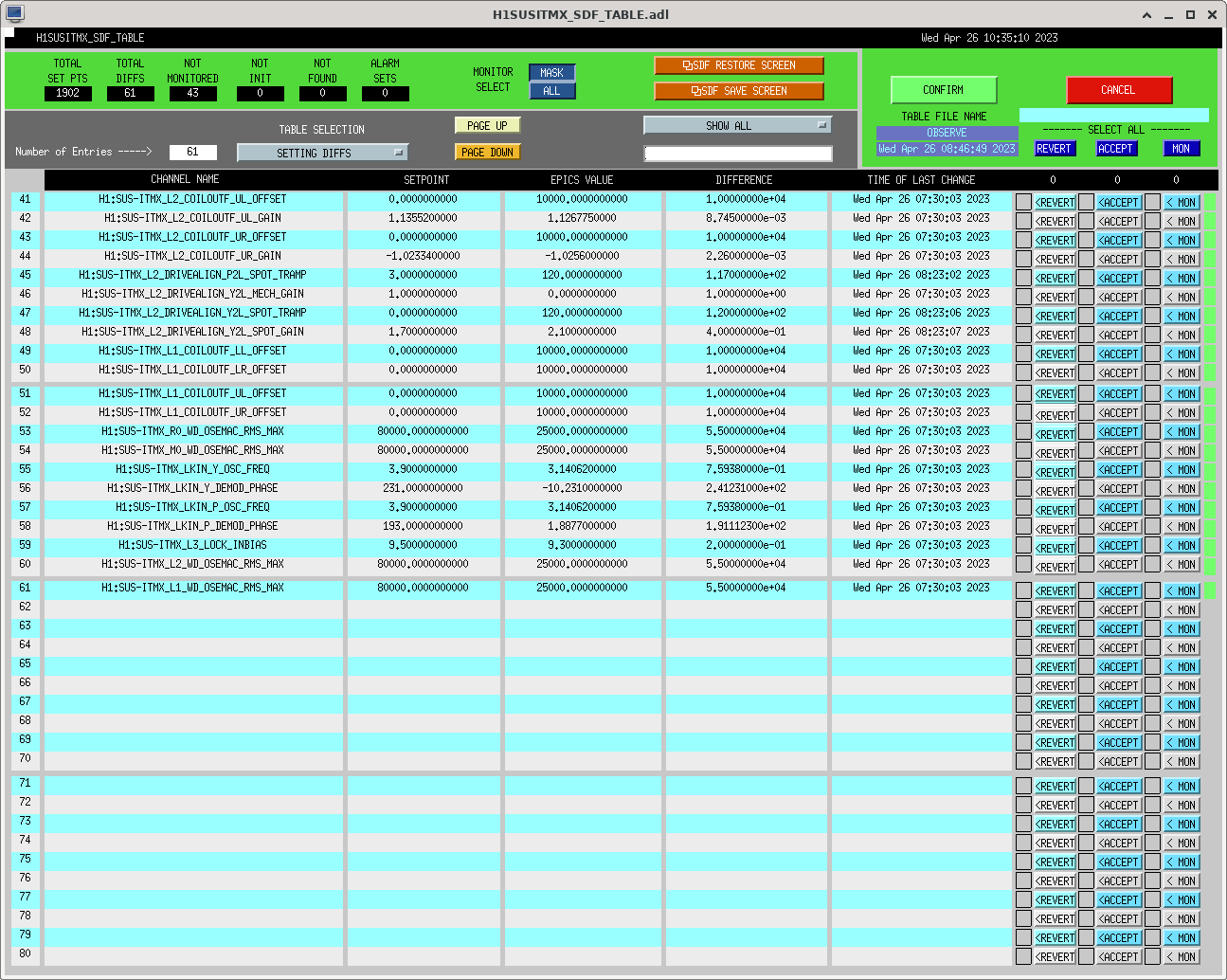
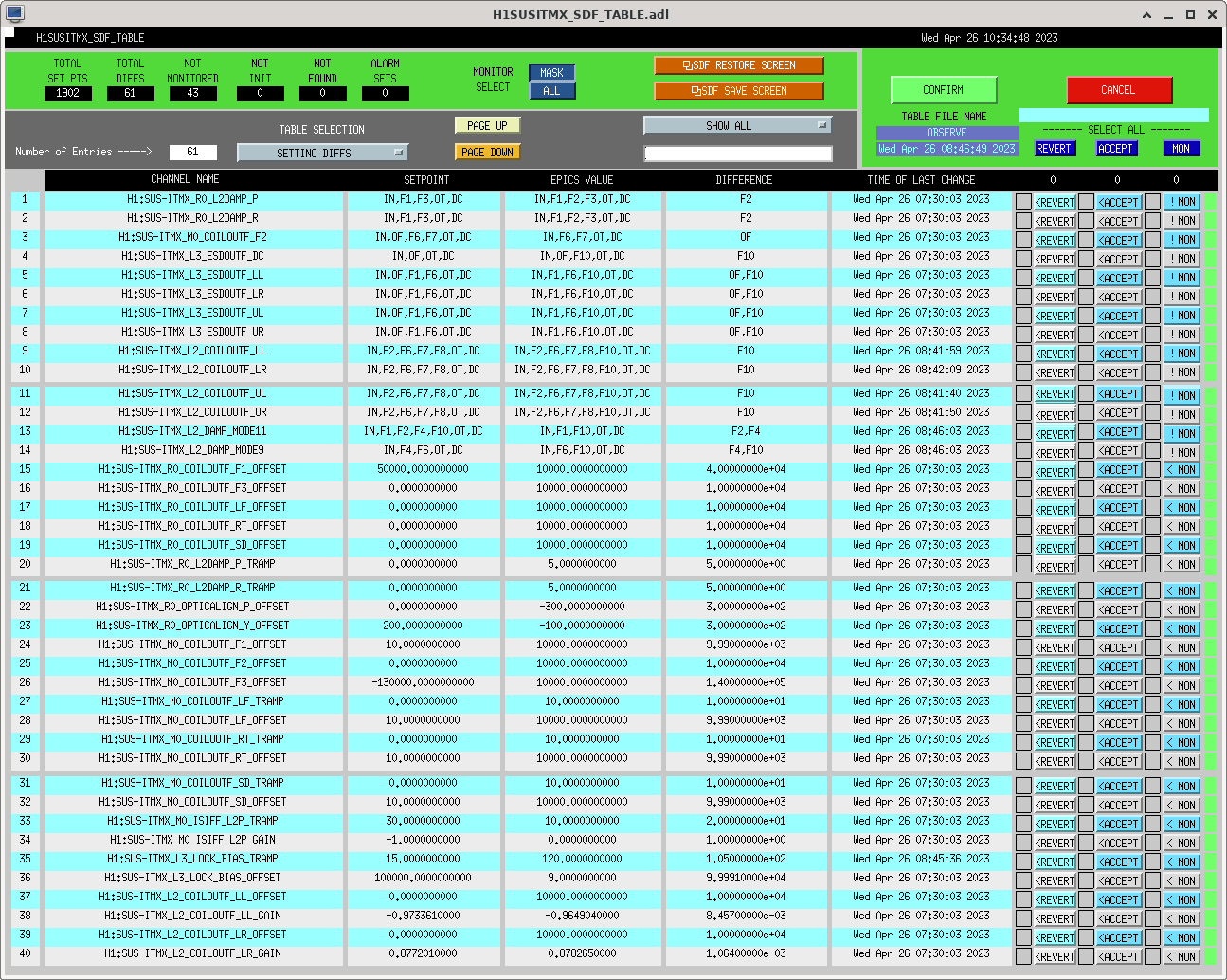
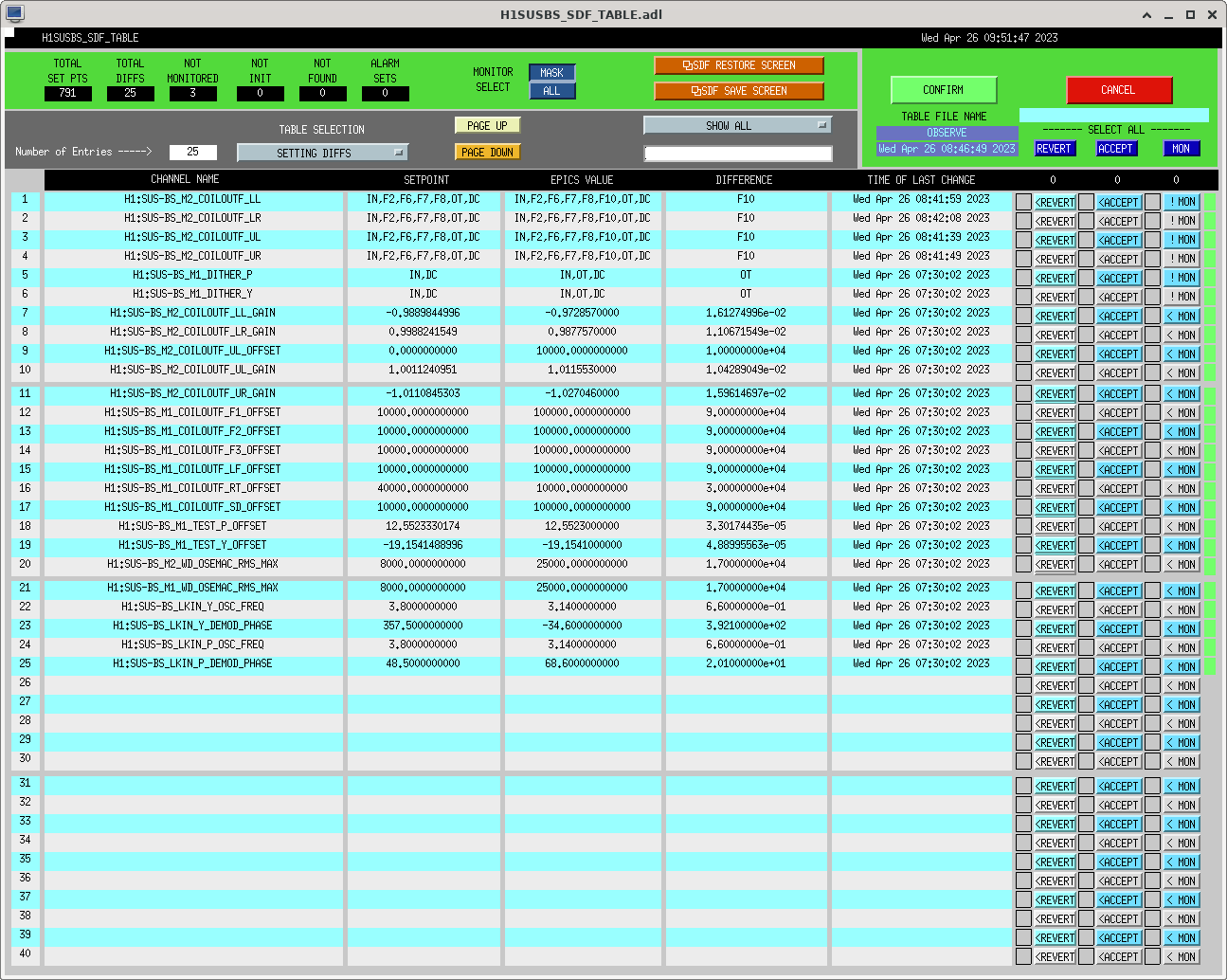
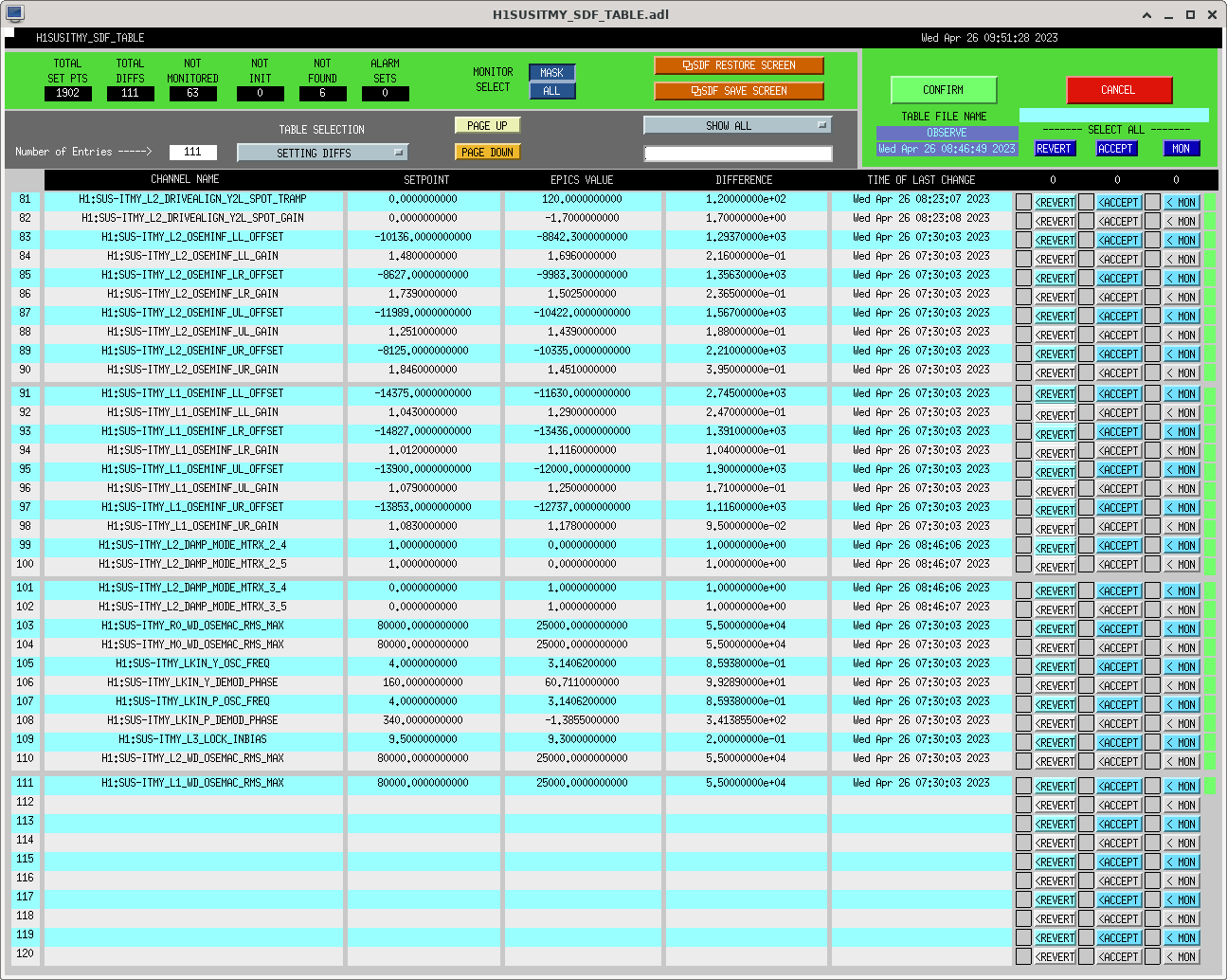
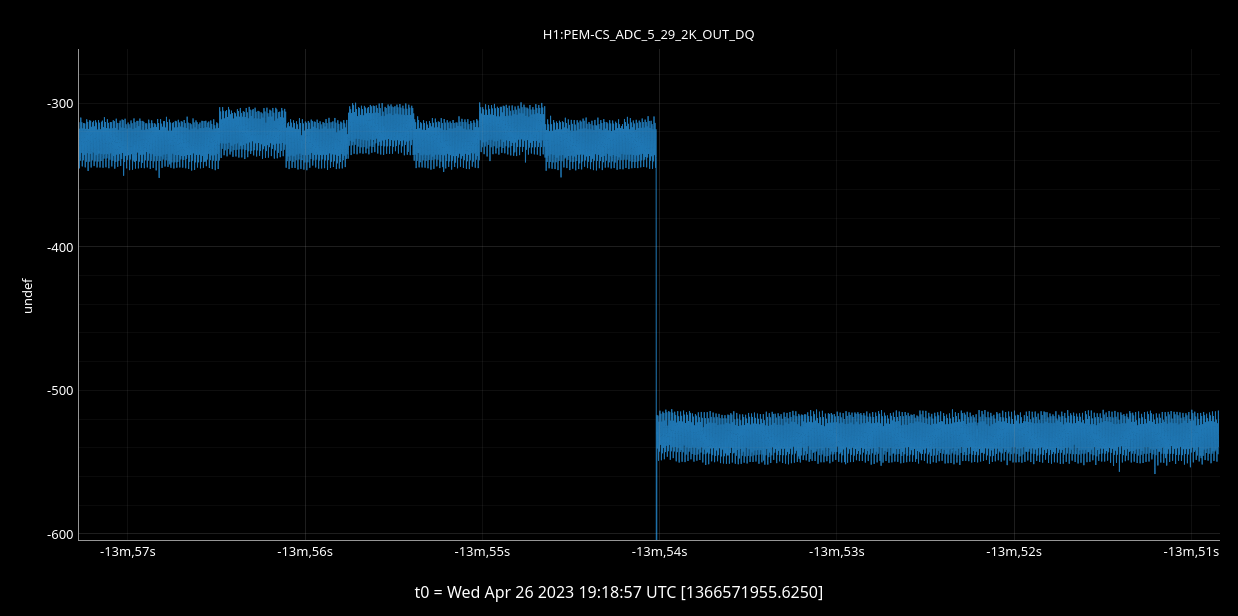
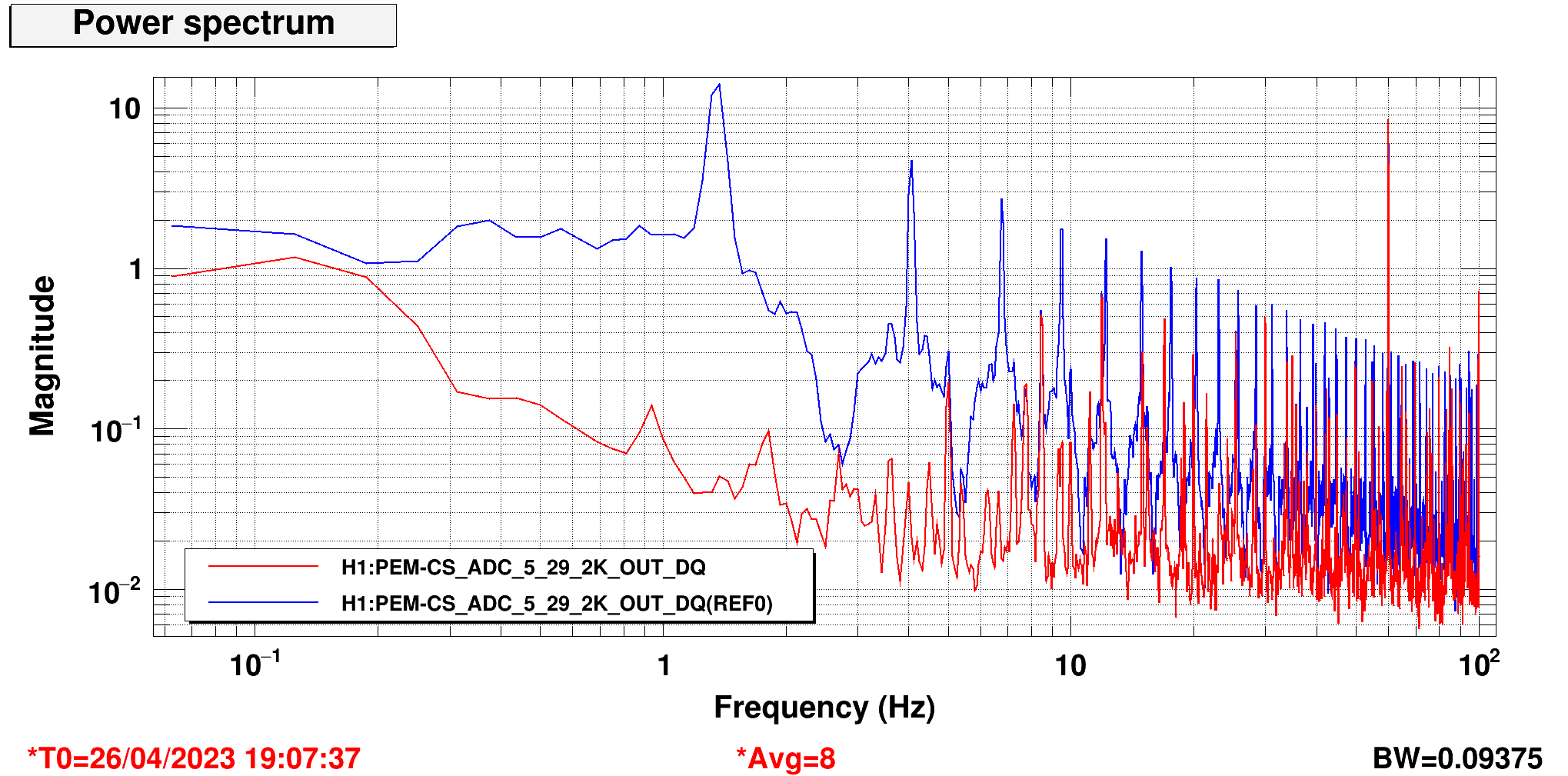
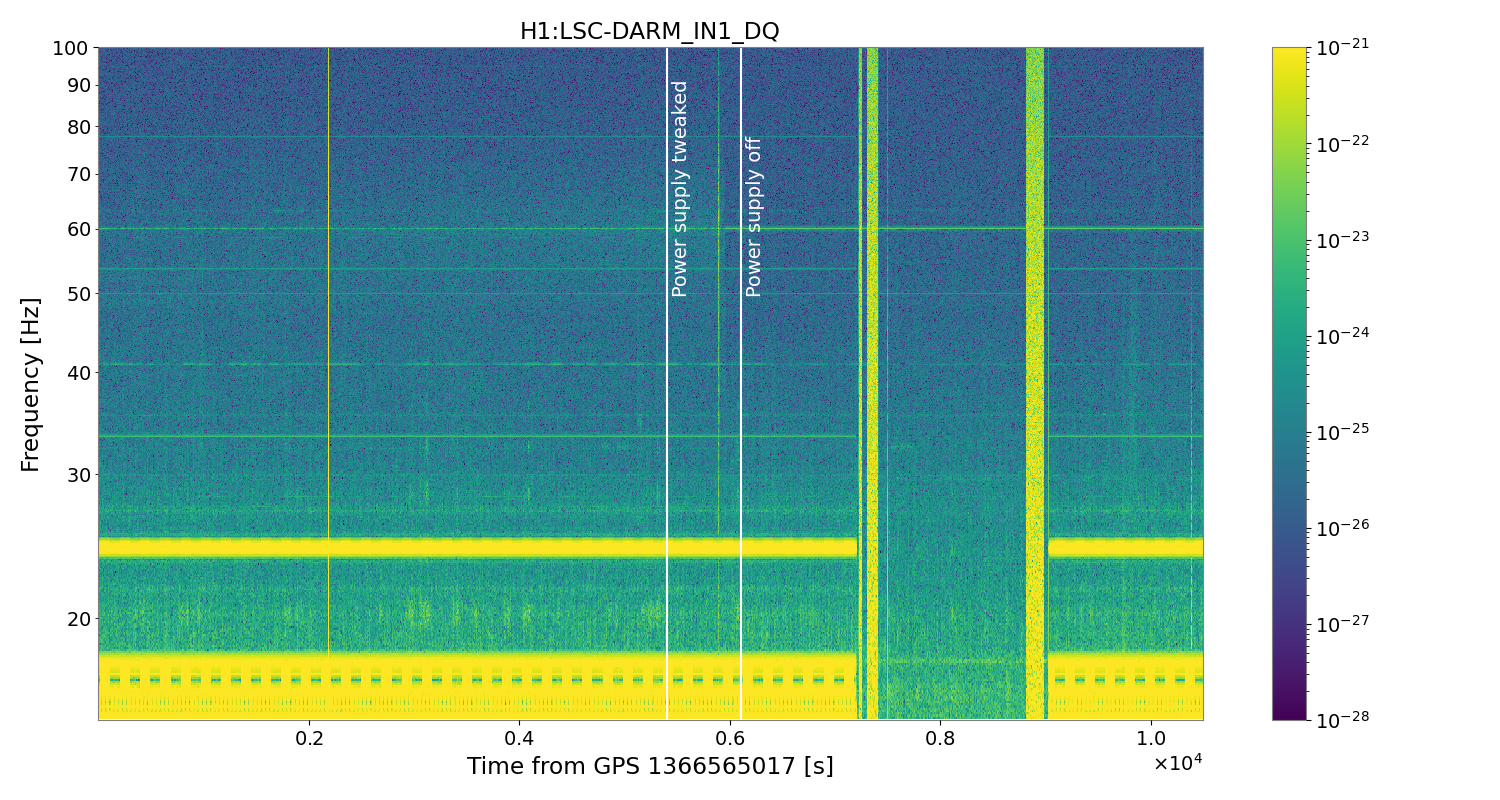
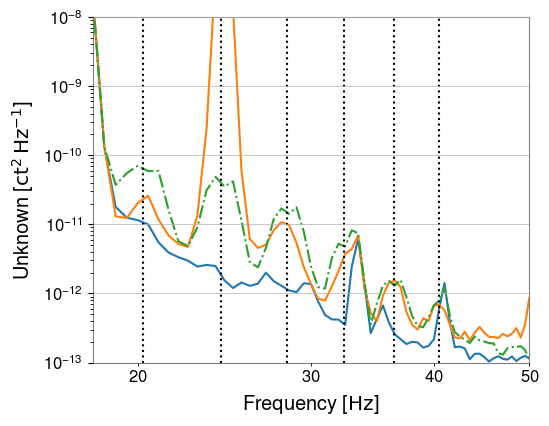
I had to make a temporary modification to DIAG_CRIT to ignore the ISI_ETMY_ST1_SC node. While we are doing the wind fence work, we pause this node to avoid it automatically putting out super sensor back in. The test in DIAG_CRIT watches all of the SC and BLND nodes ACTIVE channels (history of this addition - alog51606). Jim is working on another solution and then we can remove this modification. While I was in DIAG_CRIT I also updated the SQZ subordinate nodes.
As of right now we monitor 119 Guardian nodes to be OK. Current exclude list for IFO node is below. On top of the nodes in this list are the seismic nodes that end in SC (sensor correction) or BLND (blend) since these will change with earthquake mode, an approved changed in observing back in O3.
EXCLUDE_NODES = [
'BRSX_STAT',
'BRSY_STAT',
'DIAG_MAIN',
'H1_MANAGER', # This node should get taken out of this list after testing
'HIGH_FREQ_LINES',
'IFO_NOTIFY',
'IFO_UNDISTURBED',
'PEM_MAG_INJ',
'SEI_CONF',
'SEI_DIFF',
'SEI_ENV',
'SQZ_SHG',
'SQZ_OPO_LR',
'SQZ_CLF_LR',
'SQZ_LO_LR',
'SQZ_FC',
'SR3_CAGE_SERVO',
'SUS_CHARGE',
'TEST',
'VIOLIN_DAMPER',
]
A few notable nodes in this list are SUS_CHARGE and PEM_MAG_INJ. Both of these cannot ever be in an OK state without being overly hacky, but since they run excitations from models that are monitored, we will get taken out of Observing when they start.