TITLE: 10/29 Eve Shift: 2330-0500 UTC (1630-2200 PST), all times posted in UTC
STATE of H1: Observing at 148Mpc
INCOMING OPERATOR: Ibrahim
SHIFT SUMMARY:
Observing at 151 Mpc and have been Locked for 4.5 hours. Relocking today after maintenance was a bit strange, with two locklosses right after passing through CLOSE_BEAM_DIVERTERS. After the second attempt ended in a lockloss, during our third relocking attempt, we got stuck in PREP_DC_READOUT_TRANSITION for a bit until we discovered that the changes to the OMC whitening gain changes that had been happening as we lost lock hadn't been reverted (87813). We fixed that and continued to LASER_NOISE_SUPPRESSION, where we sat for a longer amount of time than it would have normally taken us to get up to where we lost lock the last two times. While waiting, we encountered the 1 Hz ringup again (seen during the previous two locking attempts as well), and turned on the hi asc gains to combat it. We eventually stepped up to ADS_TO_CAMERAS, then were able to turn off the hi asc gains without it ringing up again. We stepped one-by-one through the net few guardian states, waiting for a lockloss, which ended up not happening! Everything looked good so we went into Observing.
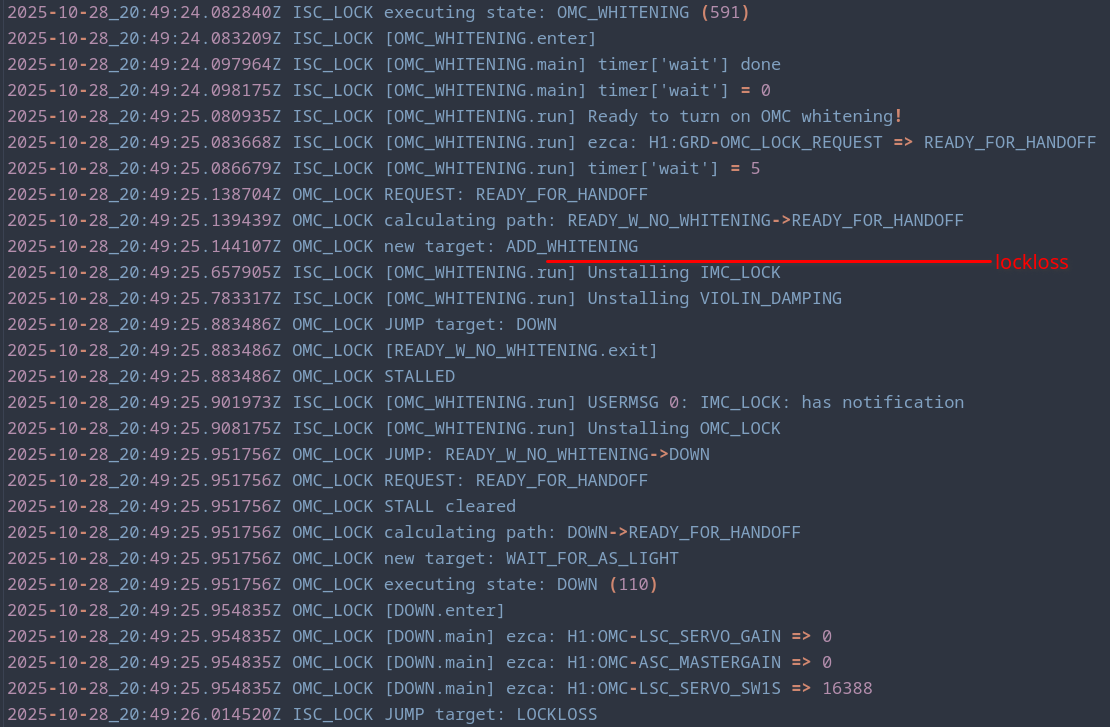
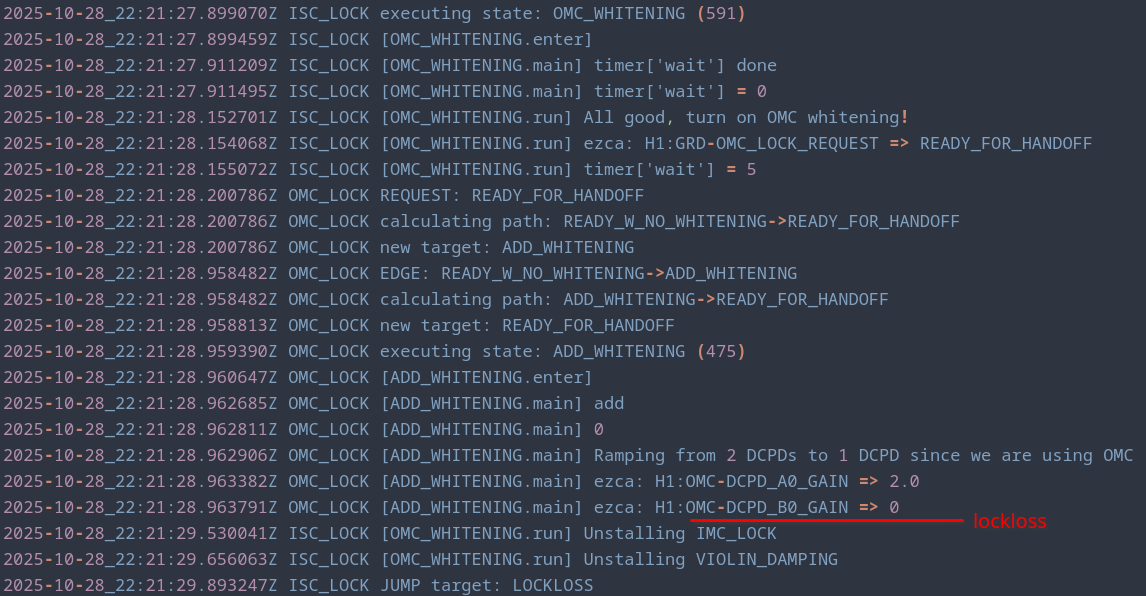
We don't know what was causing those two locklosses, but at the very least I looked through the logs and found that they didn't happen at the same spot in the locking sequence, so that rules out anything from OMC_WHITENING (and obviously CLOSE_BEAM_DIVERTERS) (first lockloss log, second lockloss log).
LOG:
23:30UTC Attempting relock #3 after maintenance day
- Paused in LASER_NOISE_SUPPRESSION
- Turned on hi gains because of 1Hz ringup
- Turned off hi gains
- 1 Hz started ringing up, turned hi gains back on
- Stepped to ADS_TO_CAMERAS
- Once ADS_TO_CAMERAS was done, turned hi gains off to see if we still had the ringup
- Stepped through the rest of the states one at a time, no locklosses
00:28 NOMINAL_LOW_NOISE
00:29 Observing