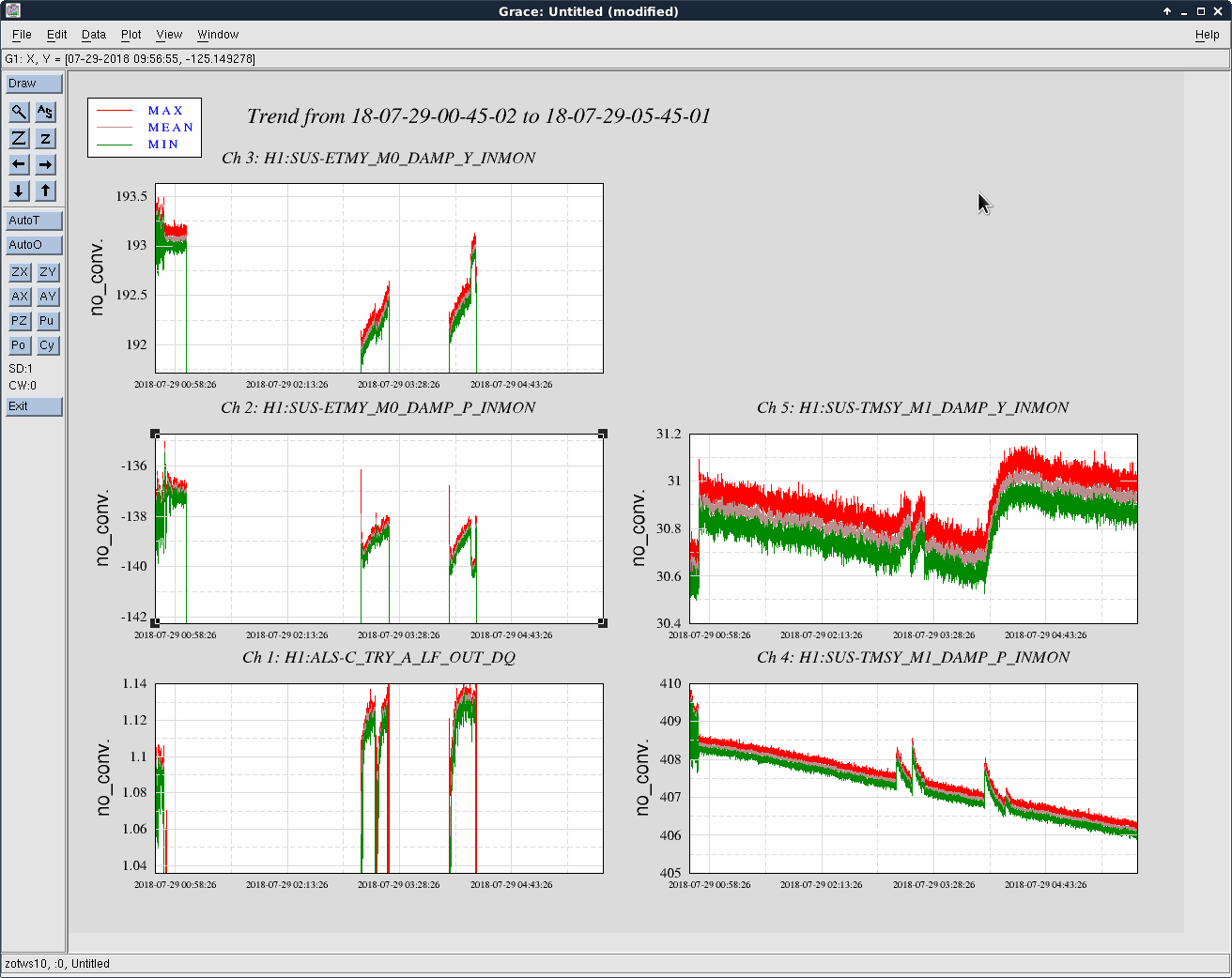
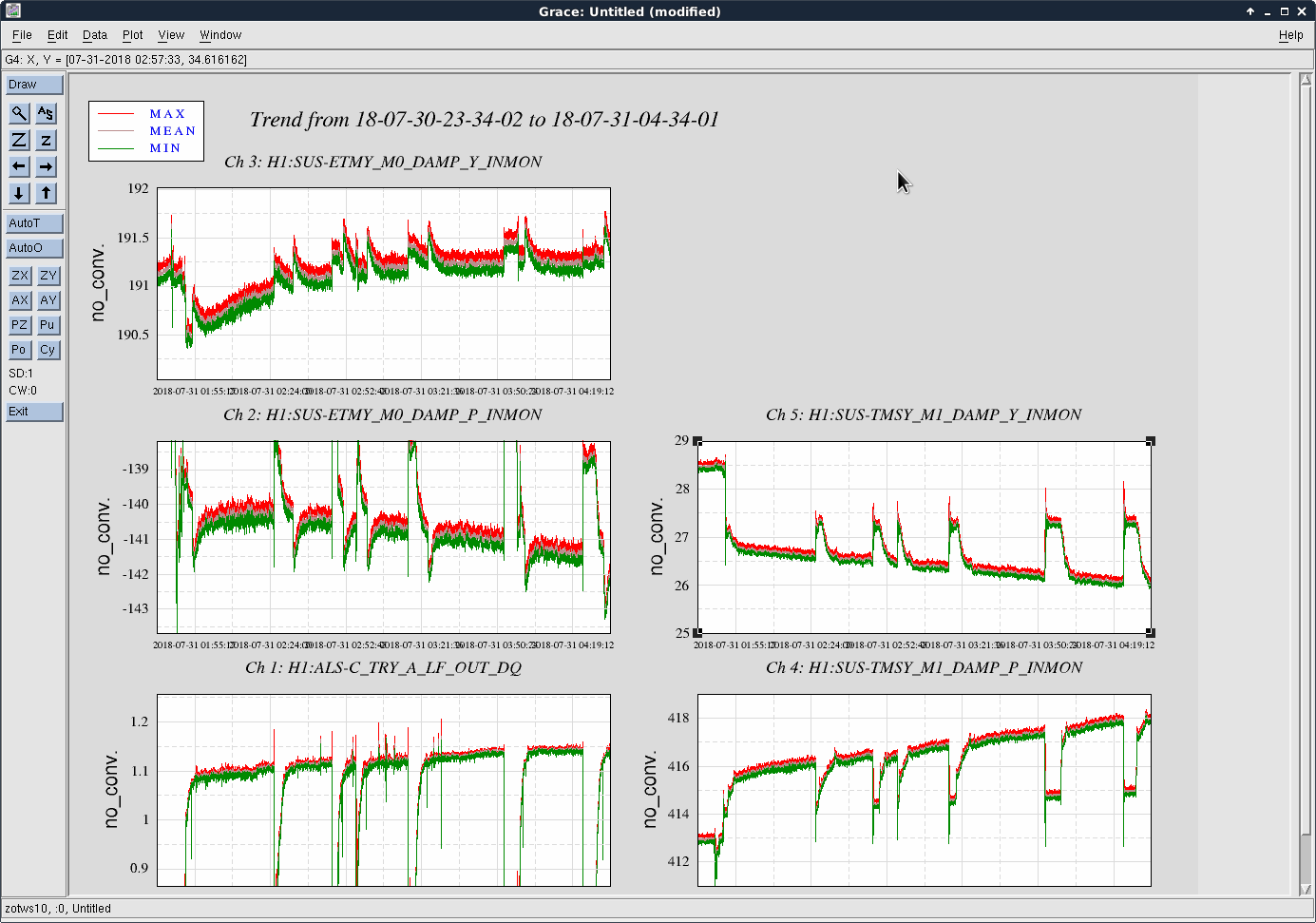
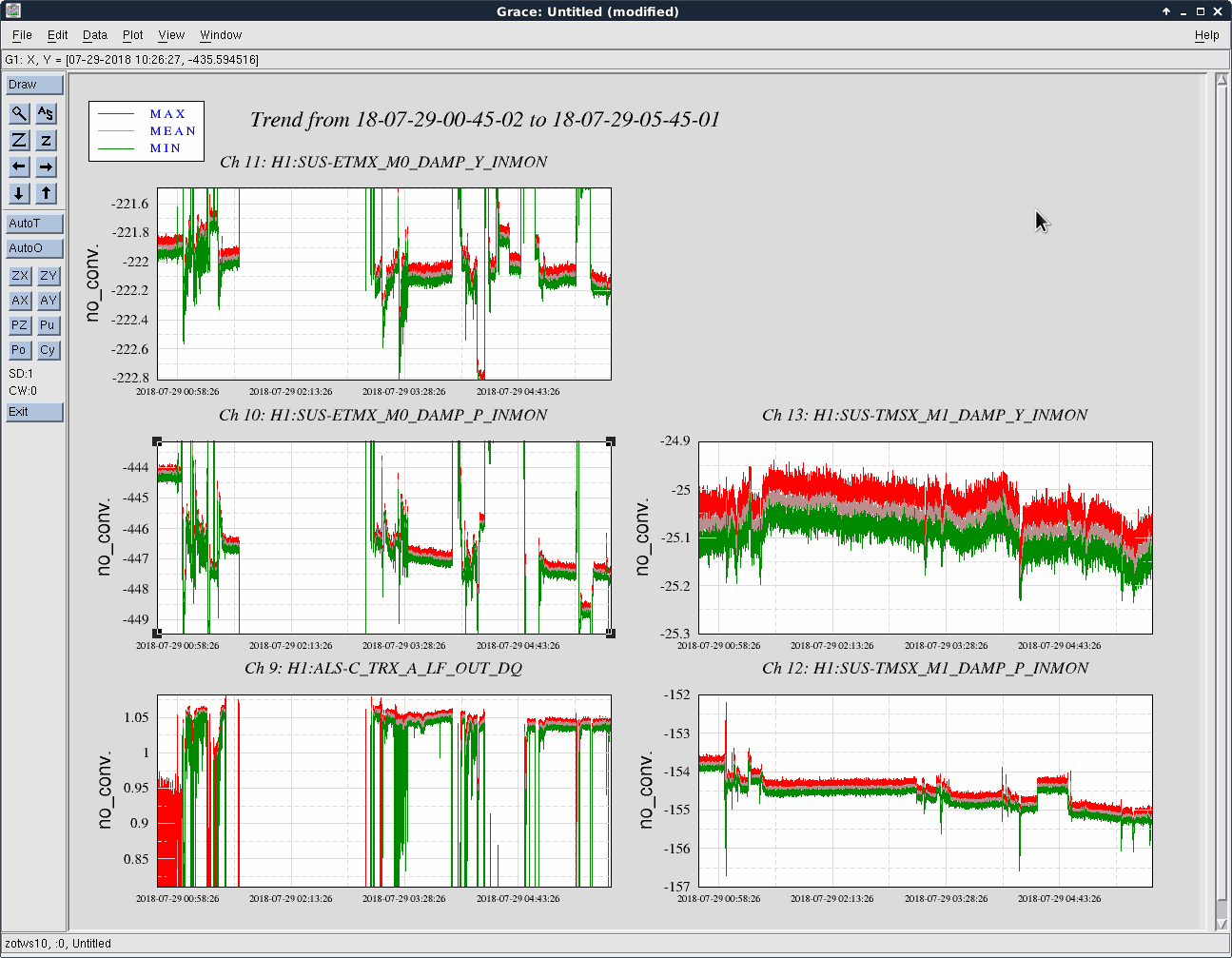
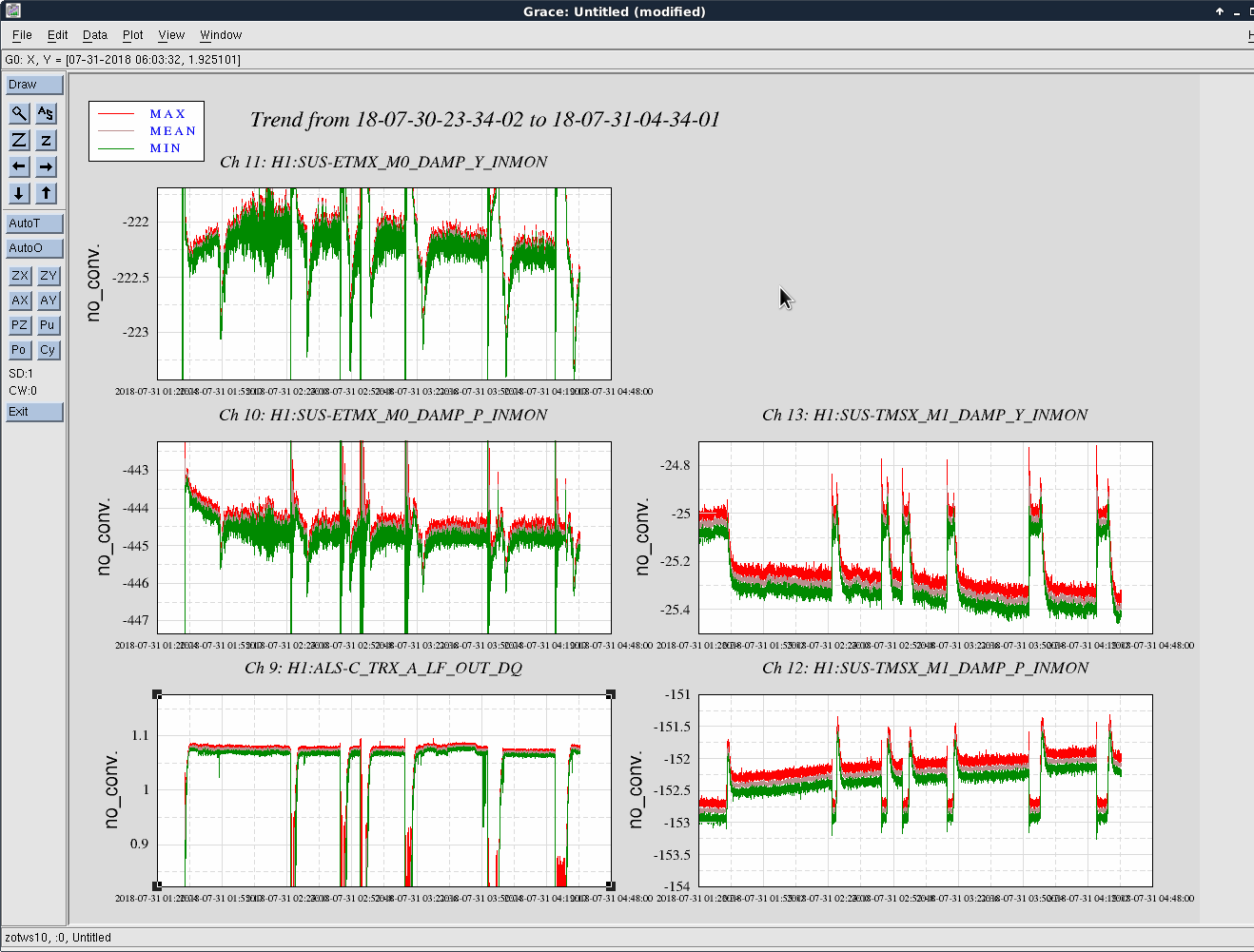
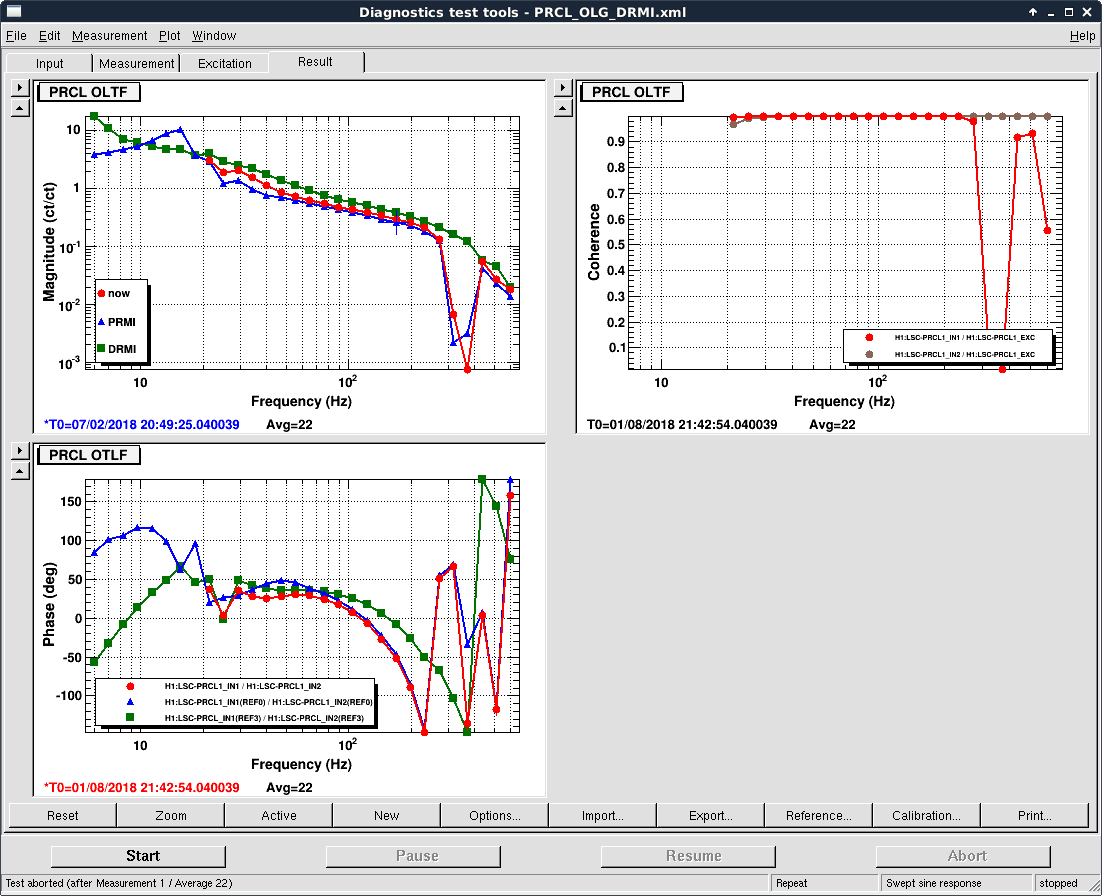
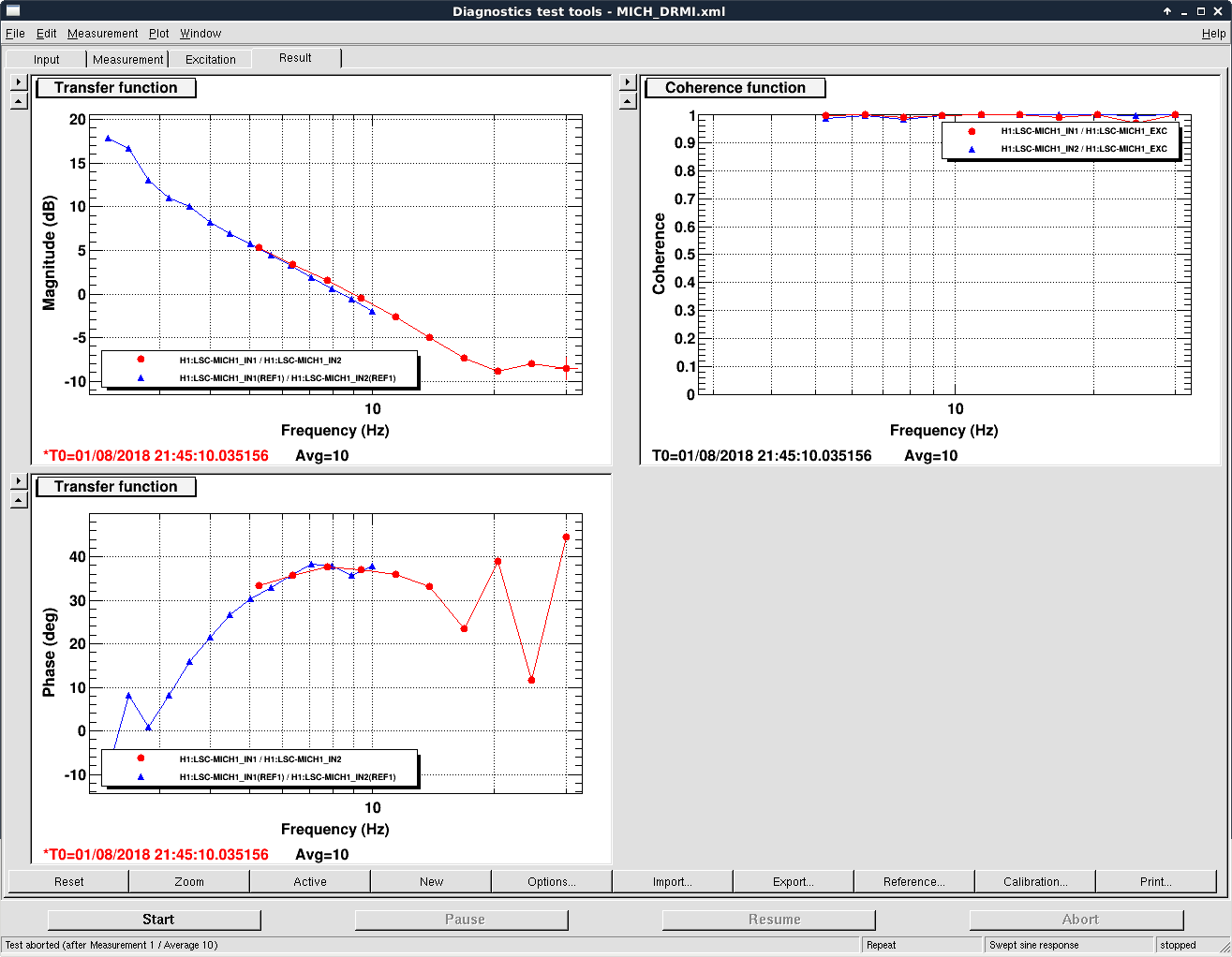
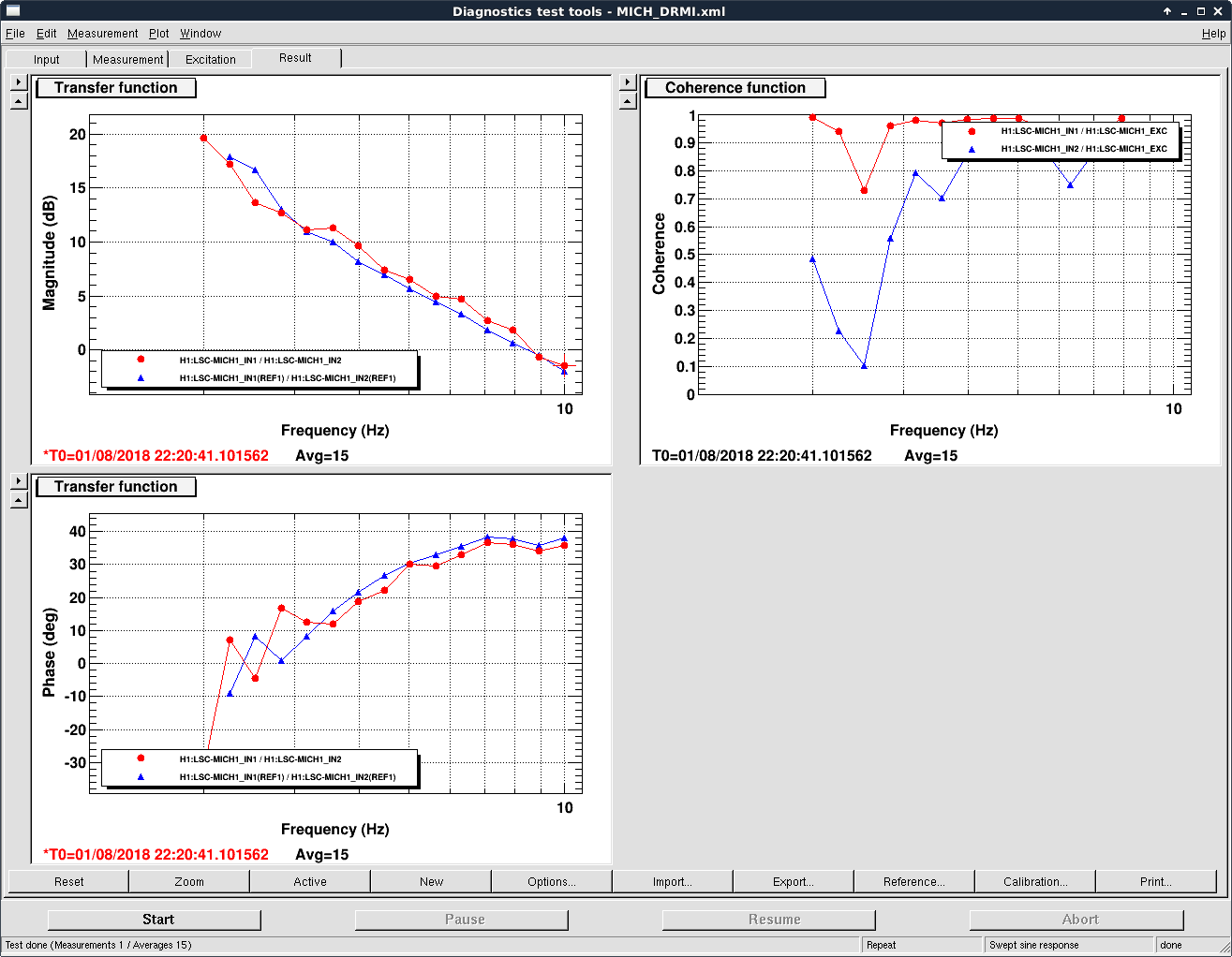
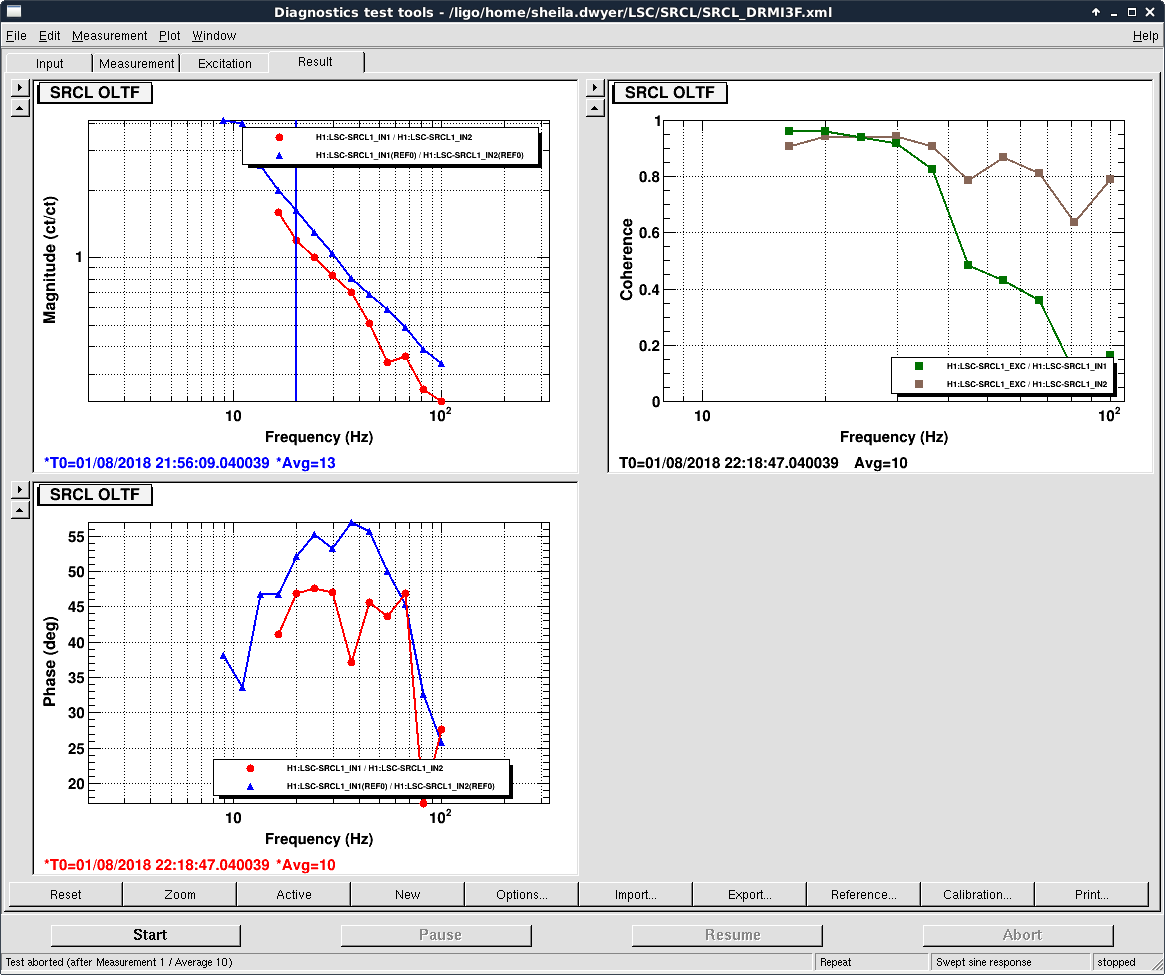
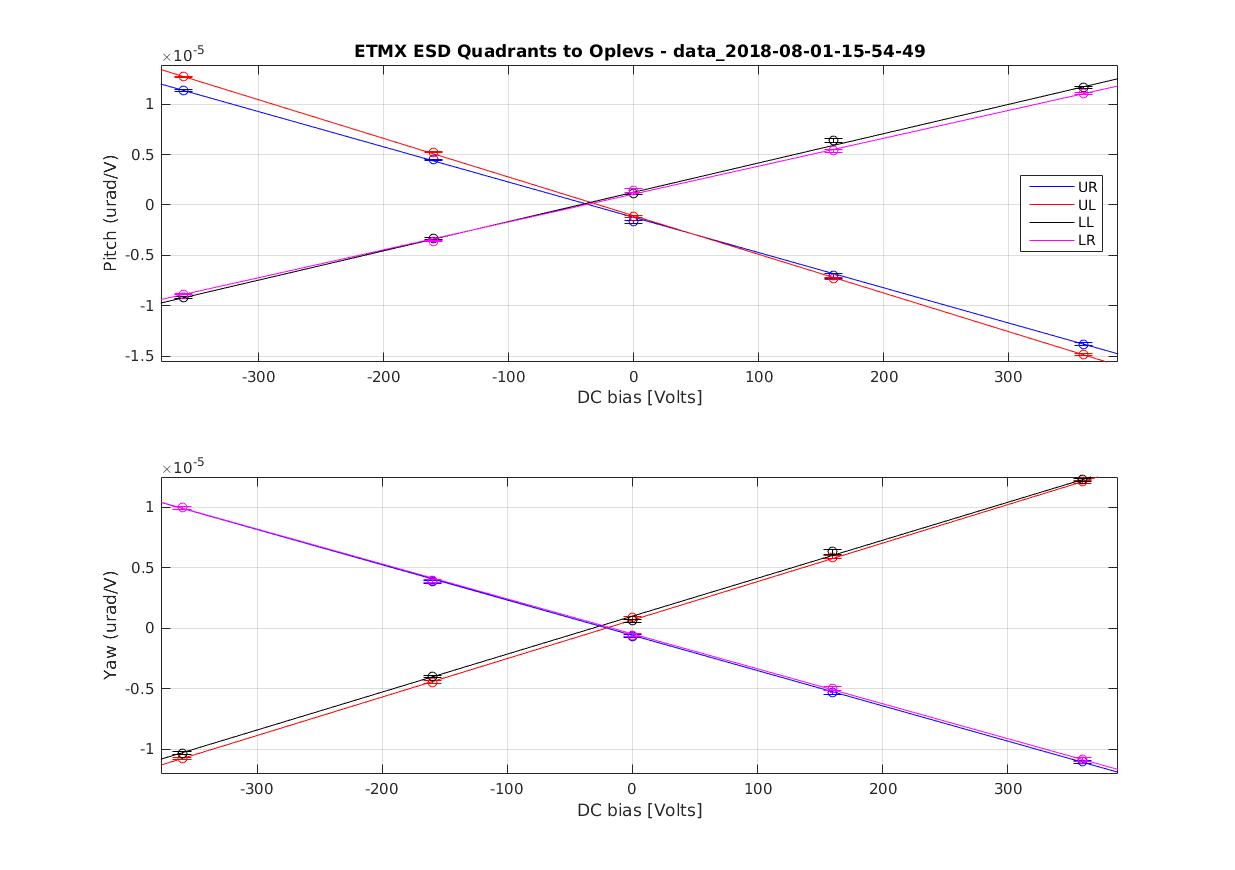
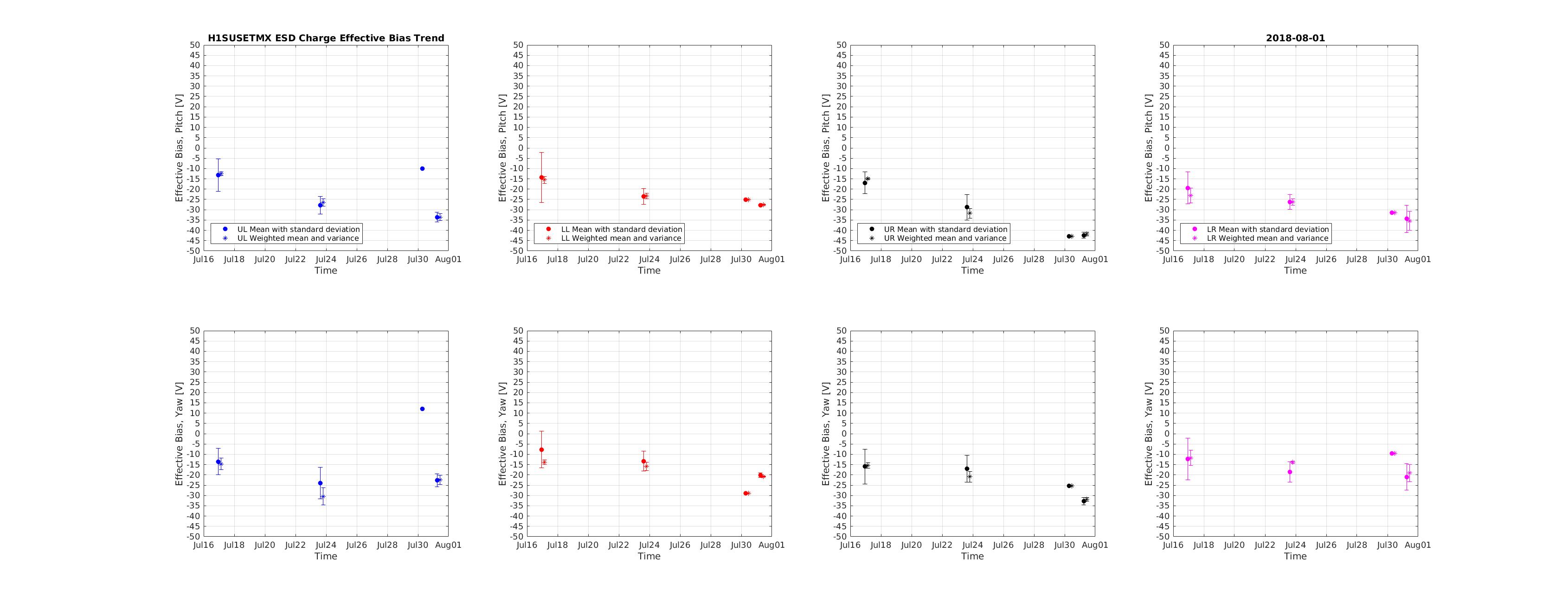
We kept losing our YARM alignment recently on the timescale of a day. It drifts so much that we need to realign the YARM by hand almost everyday.
To investigate this issue, we looked at the osem signals at two different but adjacent days with the arms locked in green.
The first and second plots showed the comparison between ETMY/TMSY at the two days, and the third and forth plots showed the similar things for X.
We see that the locking point of TMSY drifted by 5 urad in P, and 10 urad in Y. As a comparison, for TMSX the drift was 2 urad in P, and < 0.5 urad in Y. The TMSY seemed to be drift in Y significantly more than TMSX.
The drift in ETMX/Y seemed comparable at 2-3 urad level.
===================================
Also currently at 01:40:00, Aug 2nd UTC, we also have both arms locked in green. The top mass (M0) osem says that ETMY P = -154, Y = 189, TMSY P = 435, Y = 21. The pitch values were significantly different then the ones we have two days ago. For X, ETMX P = -448, Y = -222, TMSX P= -151, Y=-25, similar to what we had in the past days.