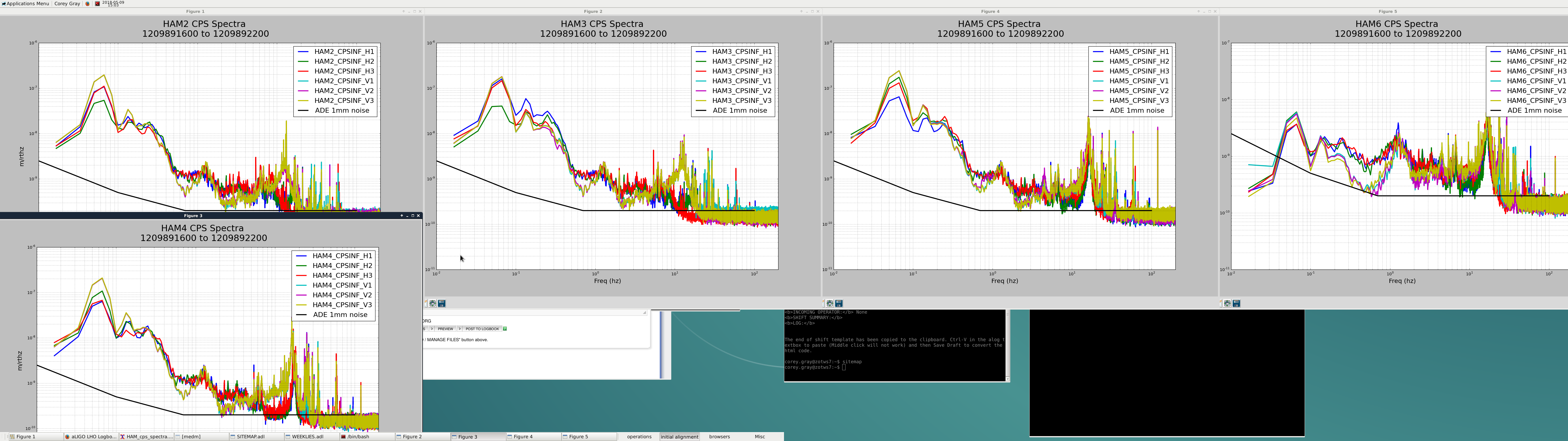
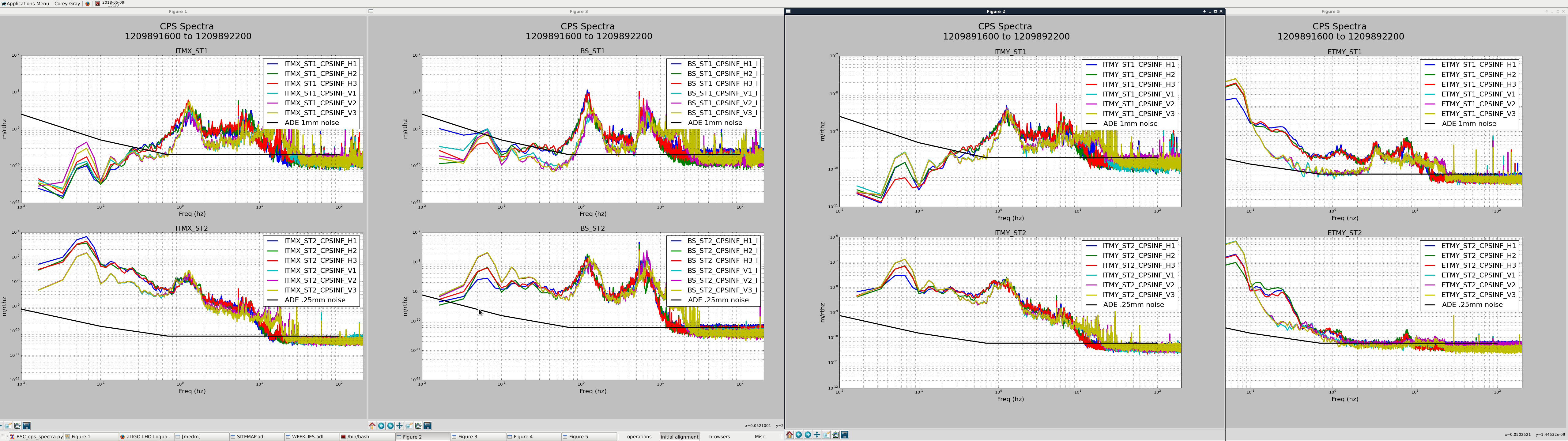
[TJ, Jamie]
minor guardian upgrade
A minor version upgrade of guardian (1.2.1) was installed on the primary guardian host (h1guardian1) today. Changes in this version:
- disallow INIT as initial request state
- fix date search in guardctrl log
- reduce log spew during connection errors
- clarify cas server processing in main daemon loop
The guardian host, h1guardian1, was rebooted (see below) so all nodes are now running this new version.
The new version is available for the workstations as well, but has not been deployed yet.
code archiving re-enabled
Code archiving has been re-enabled for all guardian nodes. This is the feature that commits all system user code into a git repo (in /ligo/cds/lho/h1/guardian/archive) upon node start or LOAD. The ownership for the archives were changed to be owned by the 'guardian' user (uid 1010). This will protect the archive from accidental overwrite by users in the controls group.
The way to access the archives is via 'guardutil', i.e.:
$ guardutil archive-clone SUS_ETMX
profiling guardian machine reboots
TJ and I performed a couple of full reboots of h1guardian1 to see how things come up after reboot.
Before re-enabling the code archives, the reboot process was relatively smooth and nodes came up fairly quickly and with very few issues. The oddest issue, was that SUS_ETMY showed the following odd exception, that did NOT go away with a LOAD, but did go away after a node restart:
2018-05-08_20:44:44.859908Z SUS_ETMY [INIT.main] next state: ALIGNED
2018-05-08_20:44:45.027281Z Traceback (most recent call last):
2018-05-08_20:44:45.027281Z File "_ctypes/callbacks.c", line 315, in 'calling callback function'
2018-05-08_20:44:45.031773Z File "/usr/lib/python2.7/dist-packages/epics/ca.py", line 583, in _onConnectionEvent
2018-05-08_20:44:45.050185Z if int(ichid) == int(args.chid):
2018-05-08_20:44:45.050185Z TypeError: int() argument must be a string or a number, not 'NoneType'
2018-05-08_20:44:47.094551Z SUS_ETMY W: Traceback (most recent call last):
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/guardian/worker.py", line 464, in run
2018-05-08_20:44:47.094551Z retval = statefunc()
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/guardian/state.py", line 246, in __call__
2018-05-08_20:44:47.094551Z main_return = self.func.__call__(state_obj, *args, **kwargs)
2018-05-08_20:44:47.094551Z File "/opt/rtcds/userapps/release/sus/h1/guardian/SUS.py", line 355, in run
2018-05-08_20:44:47.094551Z if is_aligning():
2018-05-08_20:44:47.094551Z File "/opt/rtcds/userapps/release/sus/h1/guardian/SUS.py", line 132, in is_aligning
2018-05-08_20:44:47.094551Z if ezca.is_offset_ramping(chan):
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/ezca/ezca.py", line 519, in is_offset_ramping
2018-05-08_20:44:47.094551Z return LIGOFilter(sfm_name, self).is_offset_ramping()
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/ezca/ligofilter.py", line 556, in is_offset_ramping
2018-05-08_20:44:47.094551Z return self._offset_ramp.is_ramping()
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/ezca/ramp.py", line 62, in is_ramping
2018-05-08_20:44:47.094551Z return self.__current_ramp_status()
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/ezca/ramp.py", line 31, in __current_ramp_status
2018-05-08_20:44:47.094551Z return self.__is_ramping(self.rampmon_pv.get())
2018-05-08_20:44:47.094551Z File "/usr/lib/python2.7/dist-packages/ezca/ligofilter.py", line 217, in is_ramping
2018-05-08_20:44:47.094551Z return bool(int(value) & const.READONLY_MASKS[_RAMP_TYPE].bit_mask)
2018-05-08_20:44:47.094551Z TypeError: int() argument must be a string or a number, not 'NoneType'
2018-05-08_20:44:47.094551Z SUS_ETMY [INIT.run] USERMSG 0: USER CODE ERROR (see log)
After re-enabling the code archives, we ran in to issues with startup timeouts. With the code archives enabled, each node hits the code archive (which is mounted via NFS at /ligo) at launch. When h1guardian1 is rebooted, that's 120 nodes all hitting the NFS mount simultaneously. This slowed down access considerably, and caused the startup process for many nodes to hit the systemd startup timeouts that are now in place. More than half the nodes were terminated during startup because they failed to check in in a timely manner while accessing their archive.
The solution we put in place was to just extend the startup timeout to 3 minutes, from 3 seconds. On successive reboot all nodes eventually came up and none were terminated because of startup timeout. Here's the systemd drop-in that configured the timeout:
# /home/guardian/.config/systemd/user/guardian@.service.d/timeout.conf
[Service]
TimeoutStartSec=3min
WatchdogSec=5s
There were only two nodes that had problems on the last reboot (after the timeout increase was put in place), and they both failed because of what appeared to be an EPICS port bind timeout:
2018-05-08_22:59:48.654796Z Starting Advanced LIGO Guardian service: SQZ_CLF...
2018-05-08_23:00:28.914421Z SQZ_CLF Guardian v1.2.1
2018-05-08_23:00:28.914421Z CAS: listen() error Address already in use
2018-05-08_23:00:28.914421Z terminate called after throwing an instance of 'int'
2018-05-08_23:00:30.378973Z guardian@SQZ_CLF.service: Main process exited, code=dumped, status=6/ABRT
2018-05-08_23:00:30.379381Z Failed to start Advanced LIGO Guardian service: SQZ_CLF.
2018-05-08_23:00:30.379414Z guardian@SQZ_CLF.service: Unit entered failed state.
2018-05-08_23:00:30.379421Z guardian@SQZ_CLF.service: Failed with result 'core-dump'.
This is not a failure we've noticed before, so unclear why it came about now. The problem was cleared after a node restart.
It might be nice to add a randomized node startup delay at boot, so that all the nodes aren't all fighting for resource all at the exact same time. It's easy enough to add a randomized delay at startup, by using e.g. StartExecPre= to execute a script that just sleeps for a random amount of time. But It's not clear how to do that at boot only, so that it doesn't affect normal node restarts.