I have moved a subset of guardian nodes to the new configuration on h1guardian1. This is to try to catch more of the segfaults we were seeing during the last upgrade attempt, that we have not been able to reproduce in testing.
The nodes should function normally on the new system, but given what we saw before we expect to see segfaults with a mean time to failure of about 100 hours. I will be baby sitting the nodes on the new setup, and will restart them as soon as they crash.
The nodes that have been moved to the new system are all the SUS and SEI nodes in the input chambers, BS, and the arms. No nodes from HAM4, HAM5, or HAM6 were moved. Full list of nodes now running on h1guardian1:
jameson.rollins@opsws12:~ 0$ ssh guardian@h1guardian1 list HPI_BS HPI_ETMX HPI_ETMY HPI_HAM1 HPI_HAM2 HPI_HAM3 HPI_ITMX HPI_ITMY ISI_BS_ST1 ISI_BS_ST1_BLND ISI_BS_ST1_SC ISI_BS_ST2 ISI_BS_ST2_BLND ISI_BS_ST2_SC ISI_ETMX_ST1 ISI_ETMX_ST1_BLND ISI_ETMX_ST1_SC ISI_ETMX_ST2 ISI_ETMX_ST2_BLND ISI_ETMX_ST2_SC ISI_ETMY_ST1 ISI_ETMY_ST1_BLND ISI_ETMY_ST1_SC ISI_ETMY_ST2 ISI_ETMY_ST2_BLND ISI_ETMY_ST2_SC ISI_HAM2 ISI_HAM2_SC ISI_HAM3 ISI_HAM3_SC ISI_ITMX_ST1 ISI_ITMX_ST1_BLND ISI_ITMX_ST1_SC ISI_ITMX_ST2 ISI_ITMX_ST2_BLND ISI_ITMX_ST2_SC ISI_ITMY_ST1 ISI_ITMY_ST1_BLND ISI_ITMY_ST1_SC ISI_ITMY_ST2 ISI_ITMY_ST2_BLND ISI_ITMY_ST2_SC SEI_BS SEI_ETMX SEI_ETMY SEI_HAM2 SEI_HAM3 SEI_ITMX SEI_ITMY SUS_BS SUS_ETMX SUS_ETMY SUS_IM1 SUS_IM2 SUS_IM3 SUS_IM4 SUS_ITMX SUS_ITMY SUS_MC1 SUS_MC2 SUS_MC3 SUS_PR2 SUS_PR3 SUS_PRM SUS_RM1 SUS_RM2 SUS_TMSX SUS_TMSY jameson.rollins@opsws12:~ 0$
guardctrl for nodes on h1guardian1
NOTE: Until the new system has been put fully into production, "guardctrl" interaction with these nodes on h1guardian1 is a bit different. To start/stop the nodes, or get status or view the logs, you will need to send the appropriate guardctrl command to guardian@h1guardian1 over ssh, e.g.:
jameson.rollins@opsws12:~ 0$ ssh guardian@h1guardian1 status SUS_BS
● guardian@SUS_BS.service - Advanced LIGO Guardian service: SUS_BS
Loaded: loaded (/usr/lib/systemd/user/guardian@.service; enabled; vendor preset: enabled)
Drop-In: /home/guardian/.config/systemd/user/guardian@.service.d
└─timeout.conf
Active: active (running) since Sun 2018-04-08 14:48:47 PDT; 1h 53min ago
Main PID: 24724 (guardian SUS_BS)
CGroup: /user.slice/user-1010.slice/user@1010.service/guardian.slice/guardian@SUS_BS.service
├─24724 guardian SUS_BS /opt/rtcds/userapps/release/sus/common/guardian/SUS_BS.py
└─24745 guardian-worker SUS_BS /opt/rtcds/userapps/release/sus/common/guardian/SUS_BS.py
Apr 08 14:48:50 h1guardian1 guardian[24724]: SUS_BS executing state: ALIGNED (100)
Apr 08 14:48:50 h1guardian1 guardian[24724]: SUS_BS [ALIGNED.enter]
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS REQUEST: ALIGNED
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS calculating path: ALIGNED->ALIGNED
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS same state request redirect
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS REDIRECT requested, timeout in 1.000 seconds
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS REDIRECT caught
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS [ALIGNED.redirect]
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS executing state: ALIGNED (100)
Apr 08 16:01:45 h1guardian1 guardian[24724]: SUS_BS [ALIGNED.enter]
jameson.rollins@opsws12:~ 0$
Problems encountered during move
A couple of the SEI systems did not come back up to the same states they were in before the move. This caused a trip on ETMY HPI, and ETMX ISI_ST1. I eventually recovered everything back to the states they were in at the beginning of the day.
The main problem I've been having is with the ISI_*_SC nodes. They all are supposed to be in the SC_OFF state, but a couple of the nodes are cycling between TURNING_OFF_SC and SC_OFF. For instance, ISI_ITMY_ST2_SC is showing the following:
2018-04-09_00:00:39.728236Z ISI_ITMY_ST2_SC new target: SC_OFF
2018-04-09_00:00:39.729272Z ISI_ITMY_ST2_SC executing state: TURNING_OFF_SC (-14)
2018-04-09_00:00:39.729667Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.enter]
2018-04-09_00:00:39.730468Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.main] timer['ramping gains'] = 5
2018-04-09_00:00:39.790070Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.run] USERMSG 0: Waiting for gains to ramp
2018-04-09_00:00:44.730863Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.run] timer['ramping gains'] done
2018-04-09_00:00:44.863962Z ISI_ITMY_ST2_SC EDGE: TURNING_OFF_SC->SC_OFF
2018-04-09_00:00:44.864457Z ISI_ITMY_ST2_SC calculating path: SC_OFF->SC_OFF
2018-04-09_00:00:44.865347Z ISI_ITMY_ST2_SC executing state: SC_OFF (10)
2018-04-09_00:00:44.865730Z ISI_ITMY_ST2_SC [SC_OFF.enter]
2018-04-09_00:00:44.866689Z ISI_ITMY_ST2_SC [SC_OFF.main] SENSCOR_Y_IIRHP FMs:[4] is not in the correct configuration
2018-04-09_00:00:44.866988Z ISI_ITMY_ST2_SC [SC_OFF.main] USERMSG 0: SENSCOR_Y_IIRHP FMs:[4] is not in the correct configuration
2018-04-09_00:00:44.927099Z ISI_ITMY_ST2_SC JUMP target: TURNING_OFF_SC
2018-04-09_00:00:44.927619Z ISI_ITMY_ST2_SC [SC_OFF.exit]
2018-04-09_00:00:44.989053Z ISI_ITMY_ST2_SC JUMP: SC_OFF->TURNING_OFF_SC
2018-04-09_00:00:44.989577Z ISI_ITMY_ST2_SC calculating path: TURNING_OFF_SC->SC_OFF
2018-04-09_00:00:44.989968Z ISI_ITMY_ST2_SC new target: SC_OFF
2018-04-09_00:00:44.991117Z ISI_ITMY_ST2_SC executing state: TURNING_OFF_SC (-14)
2018-04-09_00:00:44.991513Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.enter]
2018-04-09_00:00:44.993546Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.main] timer['ramping gains'] = 5
2018-04-09_00:00:45.053773Z ISI_ITMY_ST2_SC [TURNING_OFF_SC.run] USERMSG 0: Waiting for gains to ramp
Note that the problem seems to be that it's failing a check for the SENSCOR filter banks being in the correct state once SC_OFF has been achieved. Here are the nodes that are having problems, and the messages they're throwing:
ISI_HAM2_SC [SC_OFF.main] SENSCOR_GND_STS_Y_FIR FMs:[1] is not in the correct configuration ISI_HAM3_SC [SC_OFF.main] SENSCOR_GND_STS_Y_FIR FMs:[1] is not in the correct configuration ISI_BS_ST2_SC [SC_OFF.main] SENSCOR_Y_IIRHP FMs:[4] is not in the correct configuration ISI_BS_ST1_SC [SC_OFF.main] SENSCOR_GND_STS_Y_WNR FMs:[6] is not in the correct configuration ISI_ITMX_ST2_SC [SC_OFF.main] SENSCOR_Y_IIRHP FMs:[4] is not in the correct configuration ISI_ITMY_ST2_SC [SC_OFF.main] SENSCOR_Y_IIRHP FMs:[4] is not in the correct configuration ISI_ETMY_ST1_SC [SC_OFF.main] SENSCOR_GND_STS_Y_WNR FMs:[6] is not in the correct configuration ISI_ETMY_ST1_SC [SC_OFF.main] SENSCOR_GND_STS_Y_WNR FMs:[6] is not in the correct configuration
I've tried to track down where exactly the problem is coming from, but haven't been able to figure it out yet. It looks like the expected configuration just does not match with how they're currently set. I will need to consult with the SEI folks tomorrow to sort this out. In the mean time, I'm leaving all of the above nodes paused.
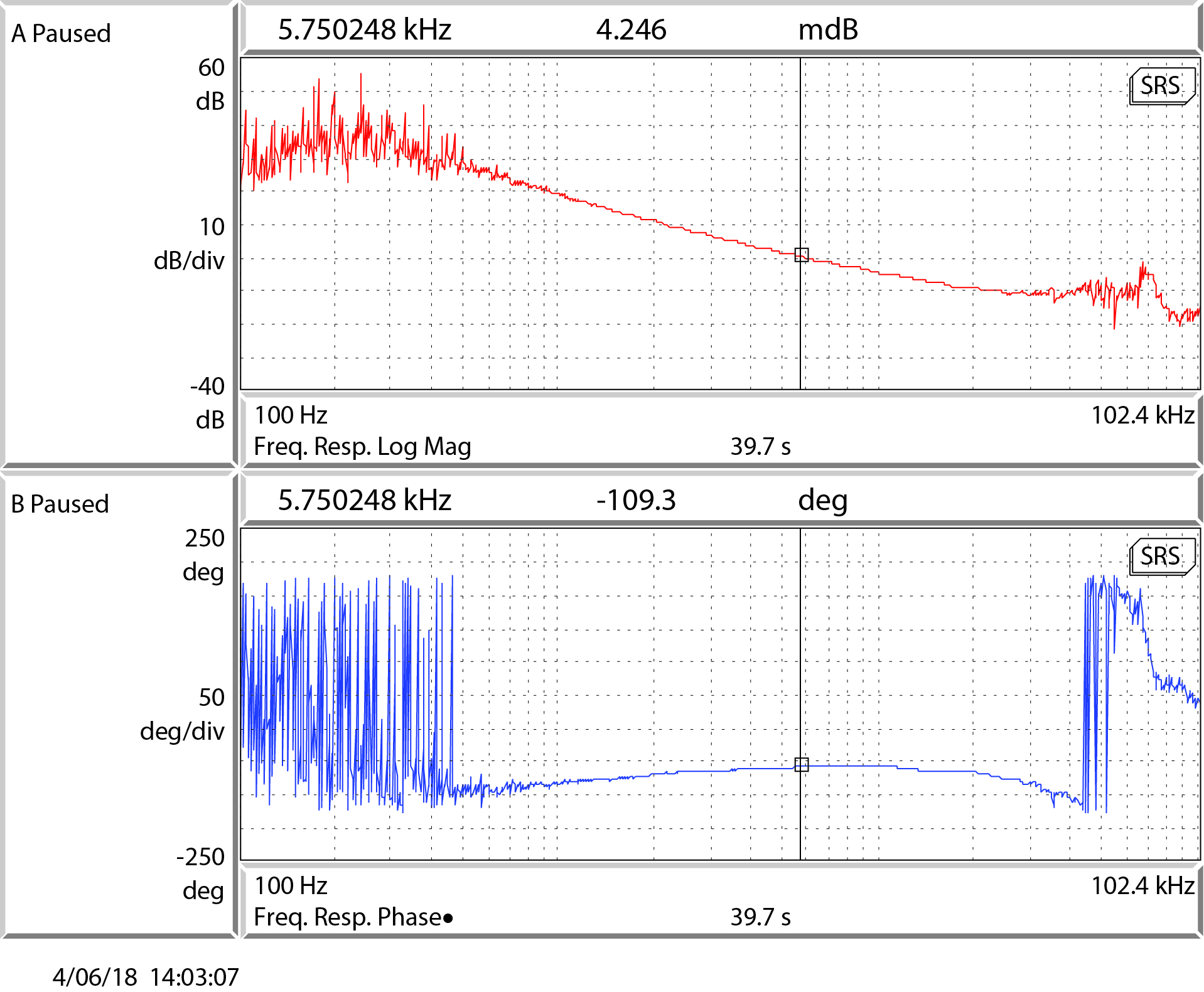
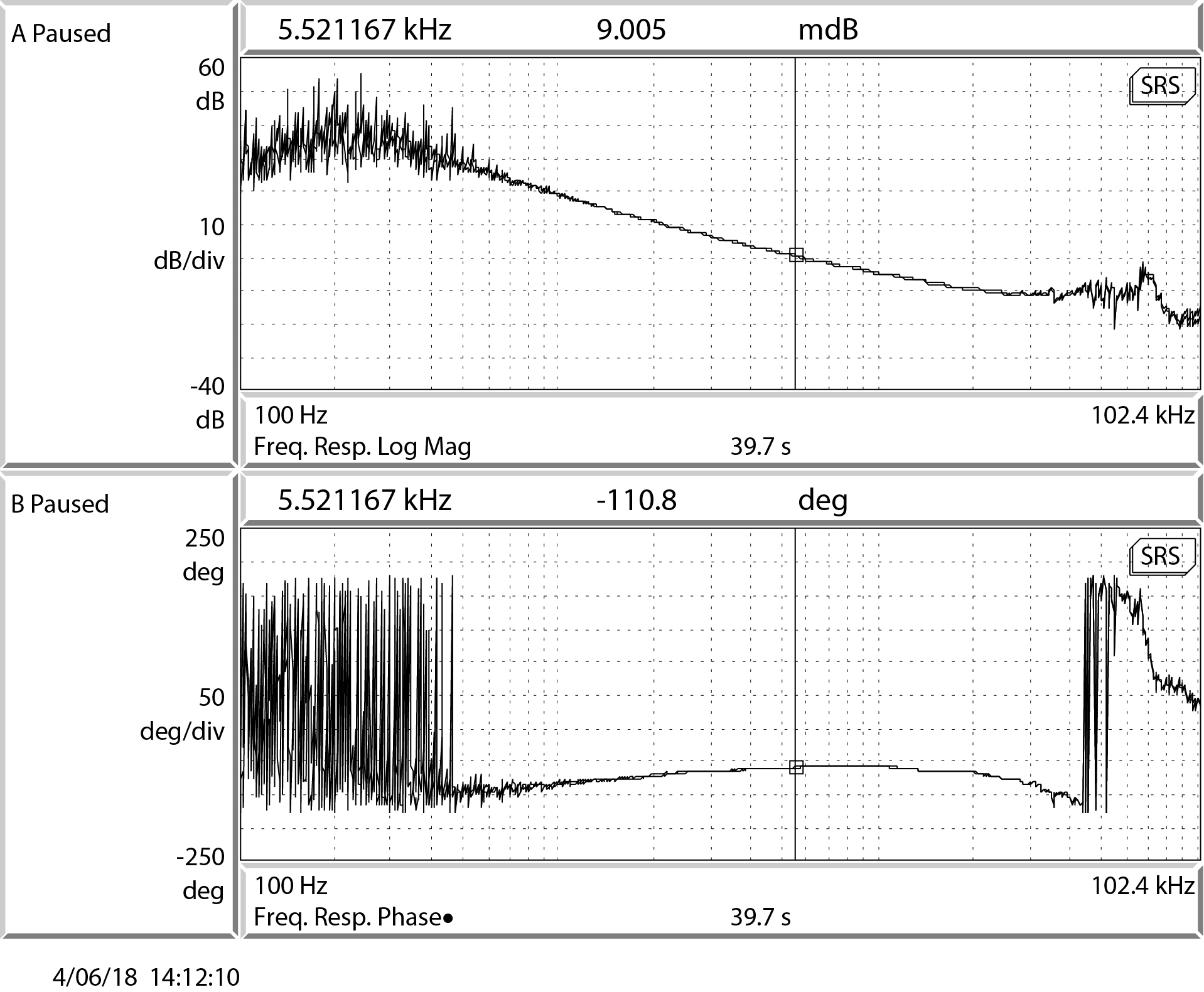
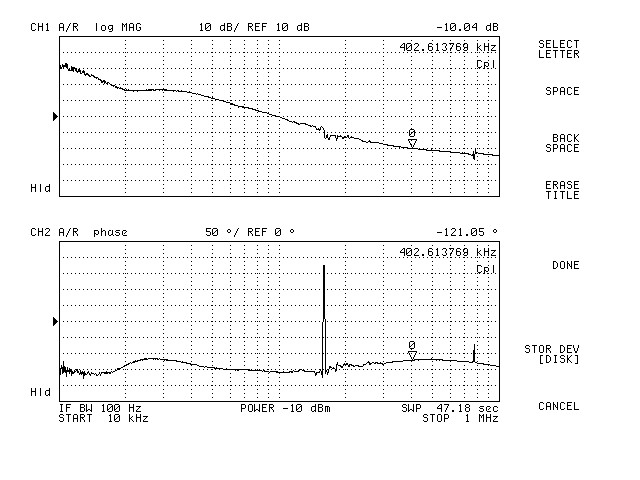
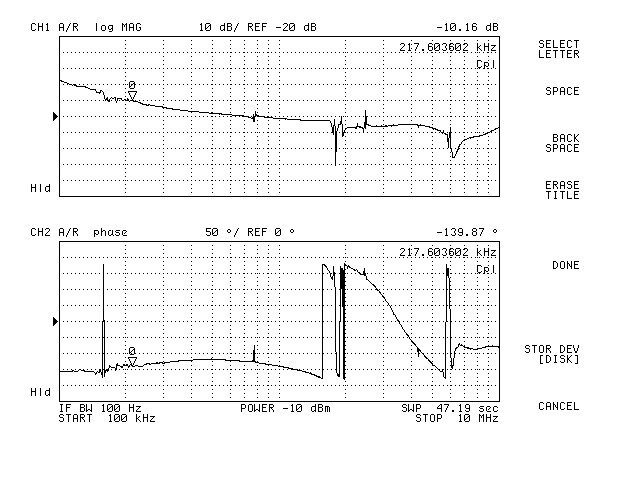





















{kind=link}
A note on the SC nodes:
Since these new SC nodes are still in a bit of a testing phase, I don't think all of the filters that will be used are in the configuration file. One way we could get around this, until the config file is set exactly how the SEI wants it, is to remove the check temporarily. I'm hesitant to remove it entirely, but that might be best since it doesn't allow for any testing of new filters.
As of 7:50 am this morning (after I restarted 5 nodes last night):
Including the five nodes I restarted last night, that's 23 seg faults out of 68 nodes in roughly 18 hours = 6 hour MTTF. That's higher than it was previously. I'm reverting all nodes back to h1guardian0.
All nodes have been reverted back to h1guardian0