J. Oberling, E. Merilh, M. Heintze
A frustrating day with little progress. We started this morning finishing up the setup for the beam caustic measurement. We installed an iris to block the ASE from the FE, installed a pump light filter to block any 808nm pump light, and installed an 95% output coupler to dump most of the FE beam into a beam dump. This done, we began the measurement. It was immediately apparent that the 200mm lens installed in L15 was too much for the Wincam, so we swapped that with a 300mm lens. We then noticed that we had a very nice LG01 mode instead of the TEM00 mode we expect. This is very strange, as we would not be able to lock the PMC with the mode out of the FE being that bad, and we had the PMC lock yesterday. We noticed the beam clipping on the bottom of PBS02 (which could be causing the mode issue), and upon relocking the PMC found that now only 13W was incident on it. Something in the alignment clearly shifted. Our first suspect was AMP_PBS01 not looking very secure in its mount, so we removed it, mounted it better and reinstalled it. We then spent the rest of the day realigning AMP_PBS01 to the PMC. At the end of this alignment we now have 25.7W incident on the PMC, with 3.6W reflected and 22.1W transmitted. The beam is still slightly clipping on PBS02, so apparently the new pick-off has changed the launch angle out of the FE; since the beam still hits mirror M33, we will fix this by shaving a few mm off of a couple of spare mounts and re-mount WP02 and PBS02 to this new beam line. The FE was left running with PMC locked over the weekend to see if our alignment shifts again; if so, then we have another issue to hunt down before proceeding with the beam caustic measurement.




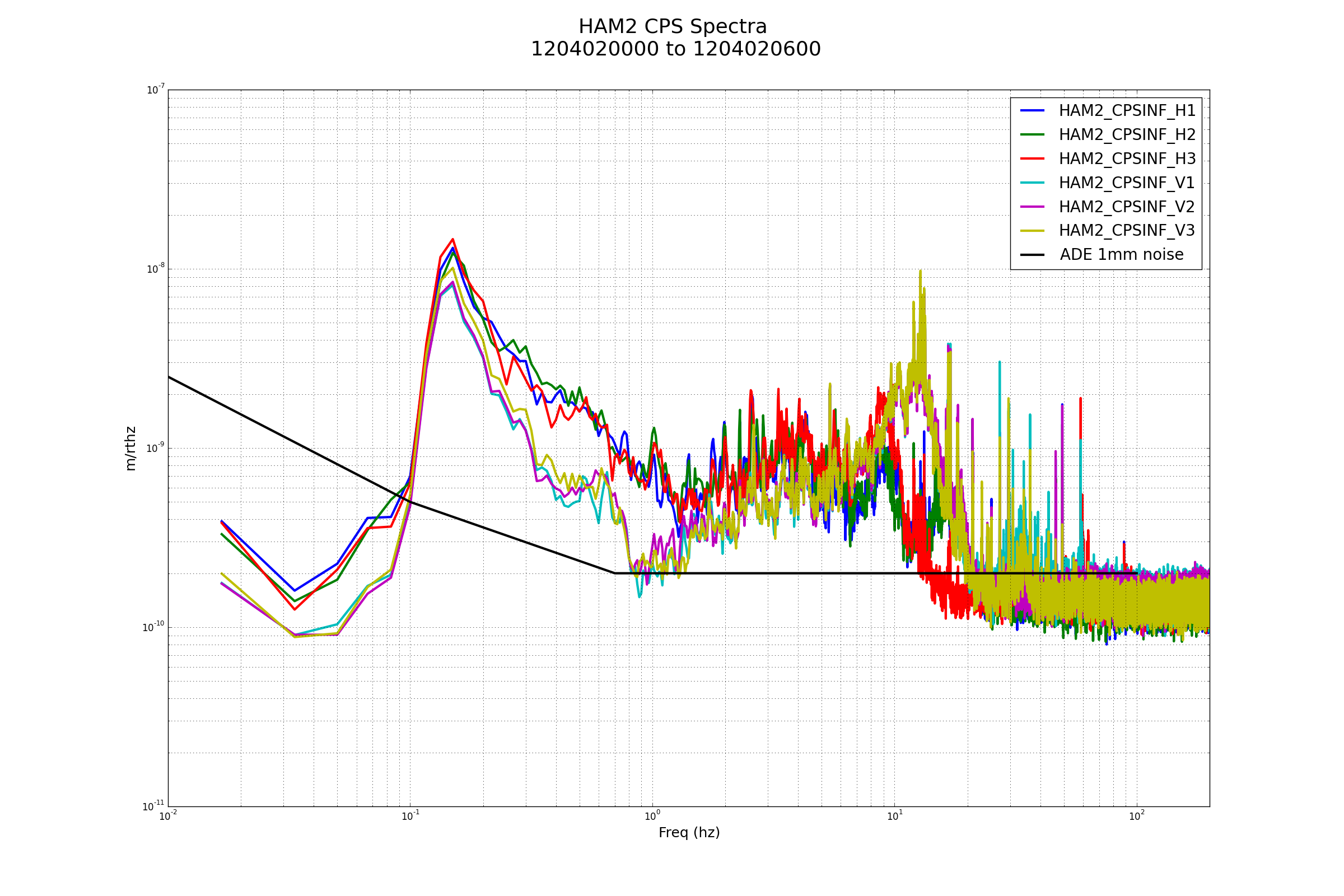
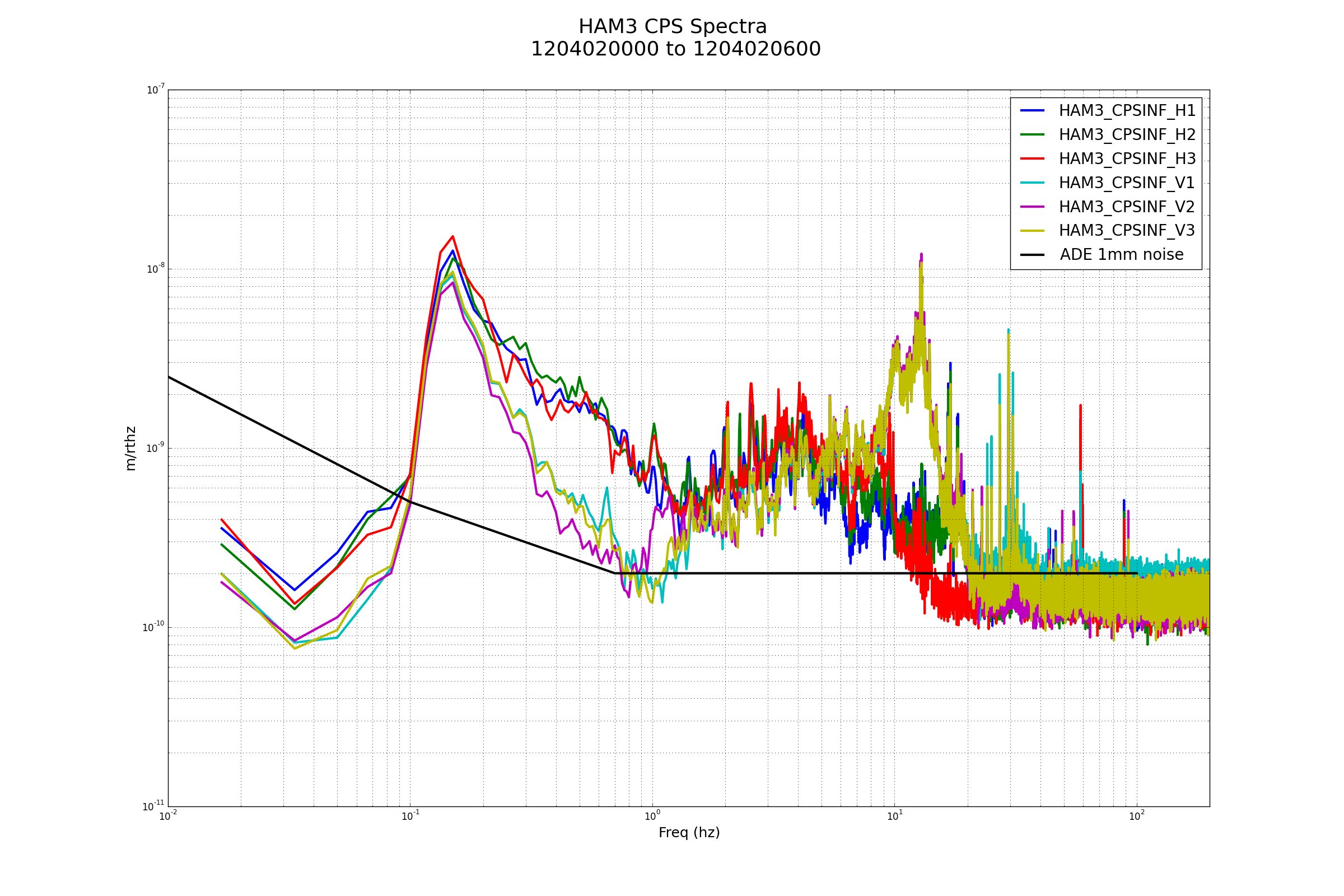
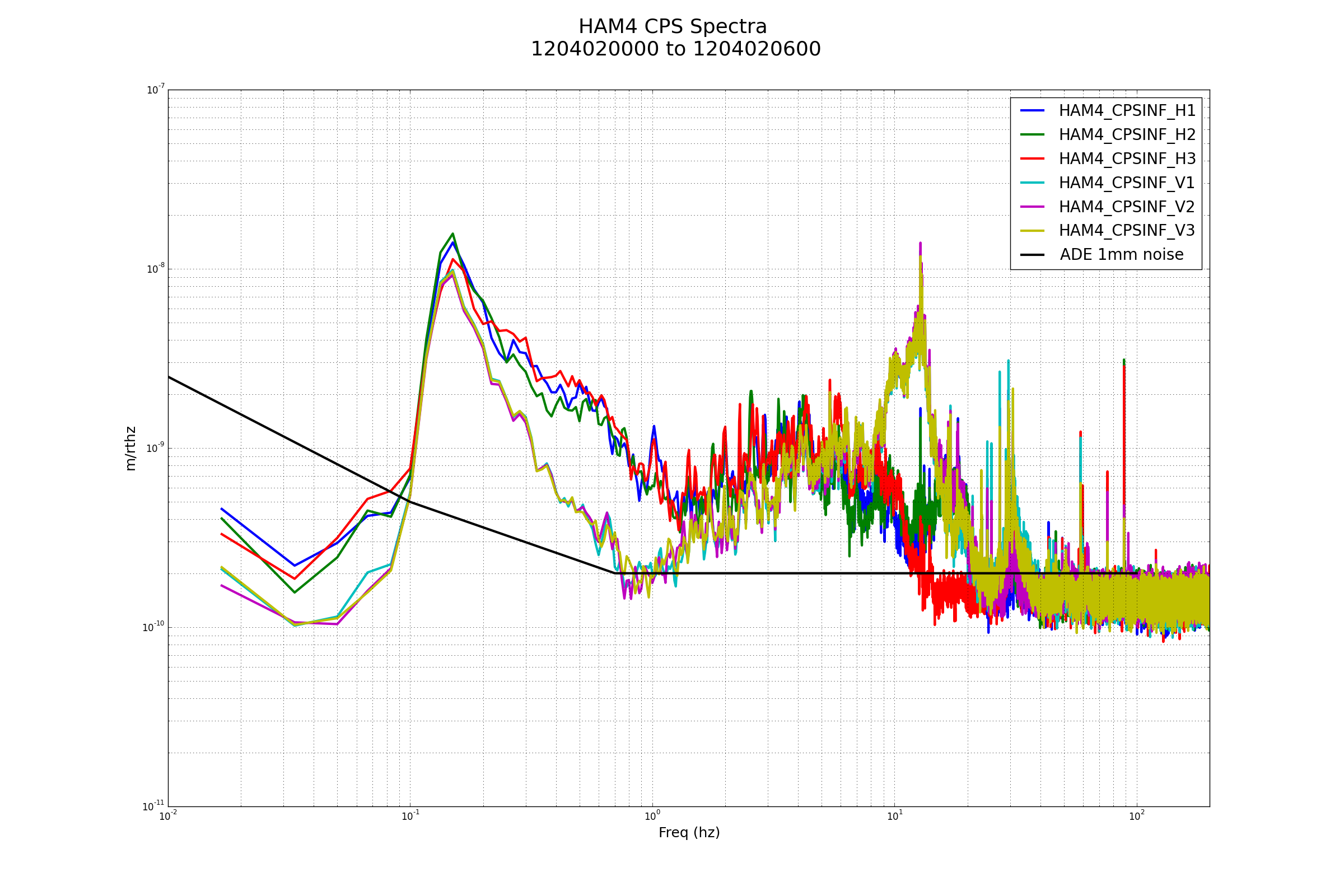
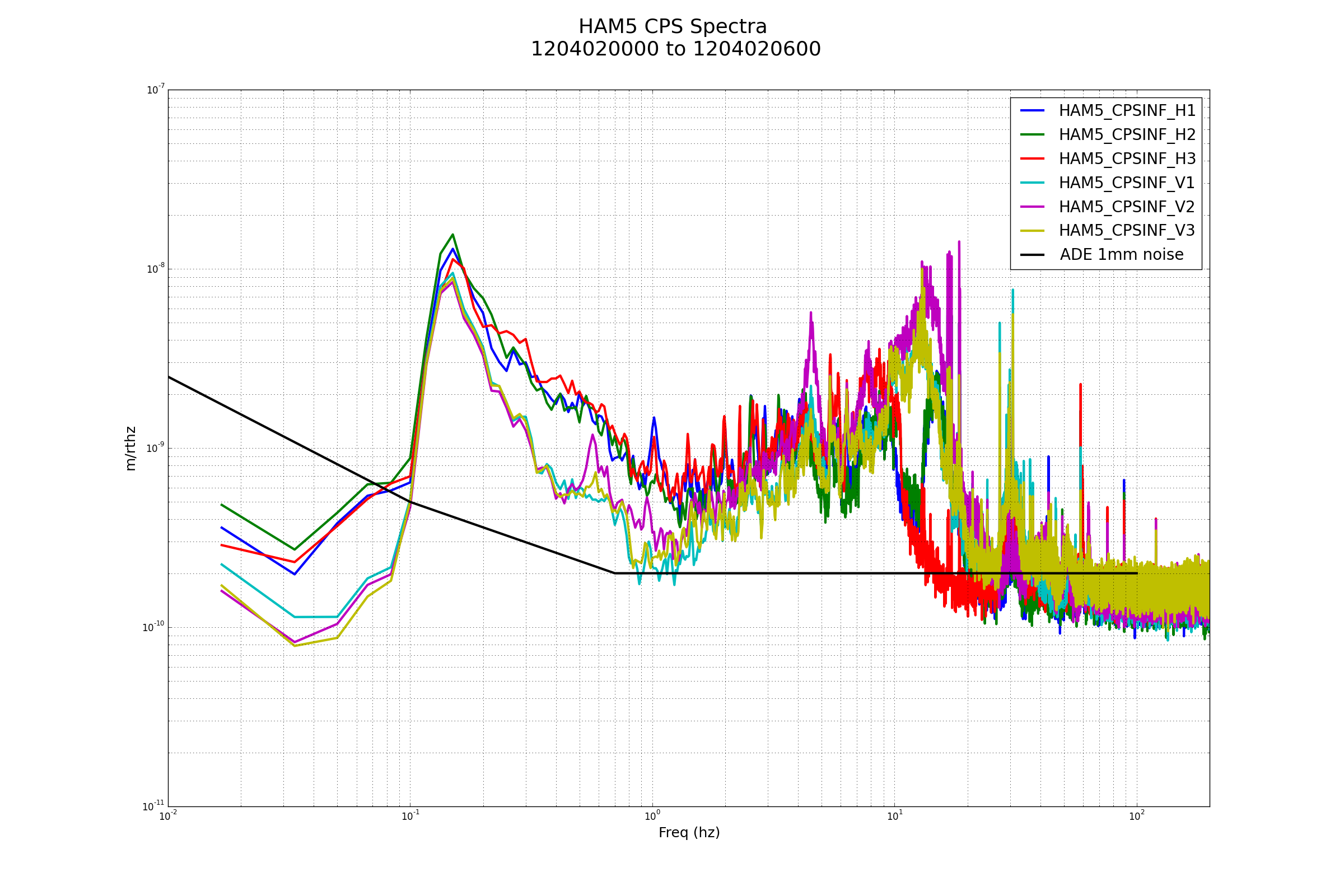
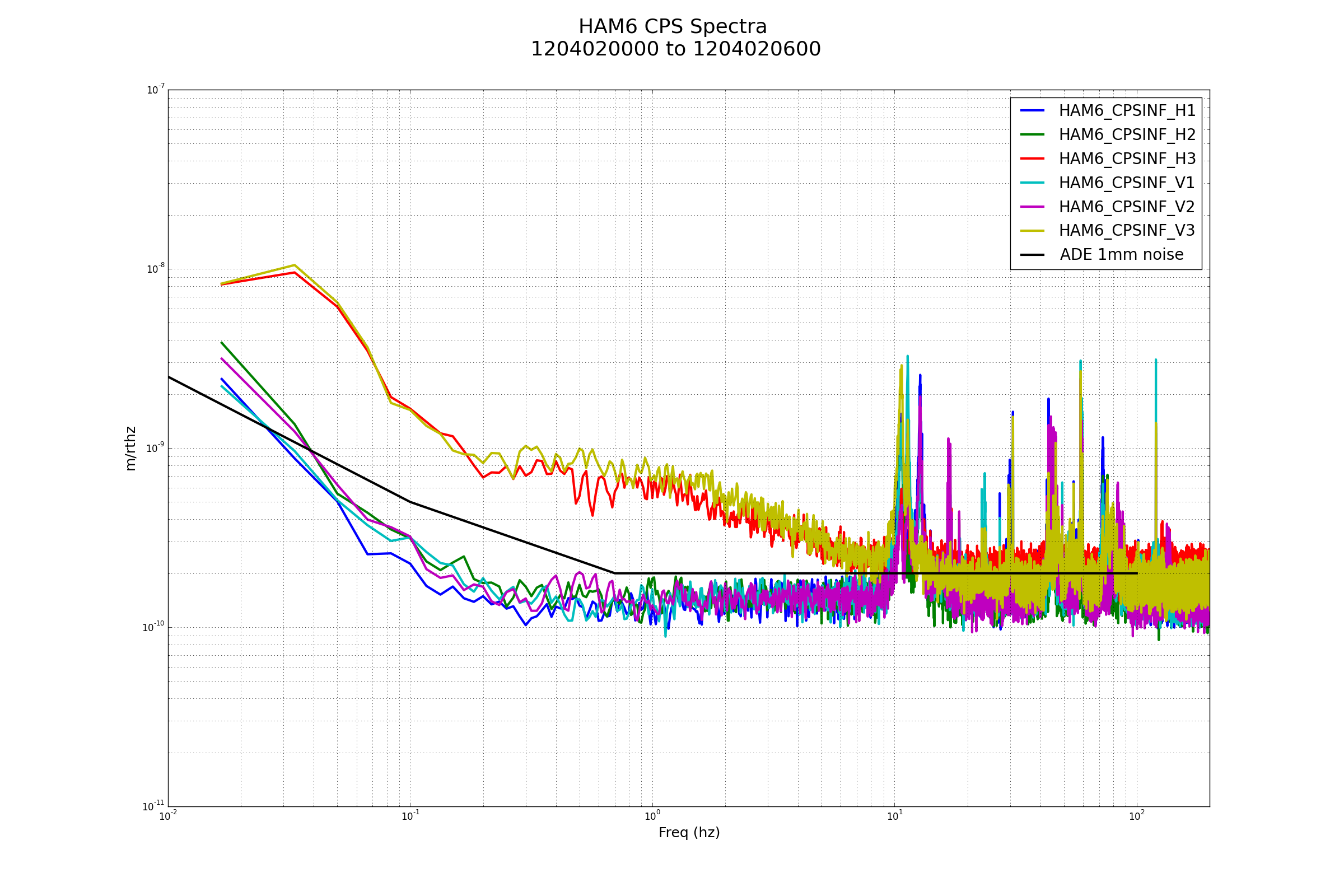
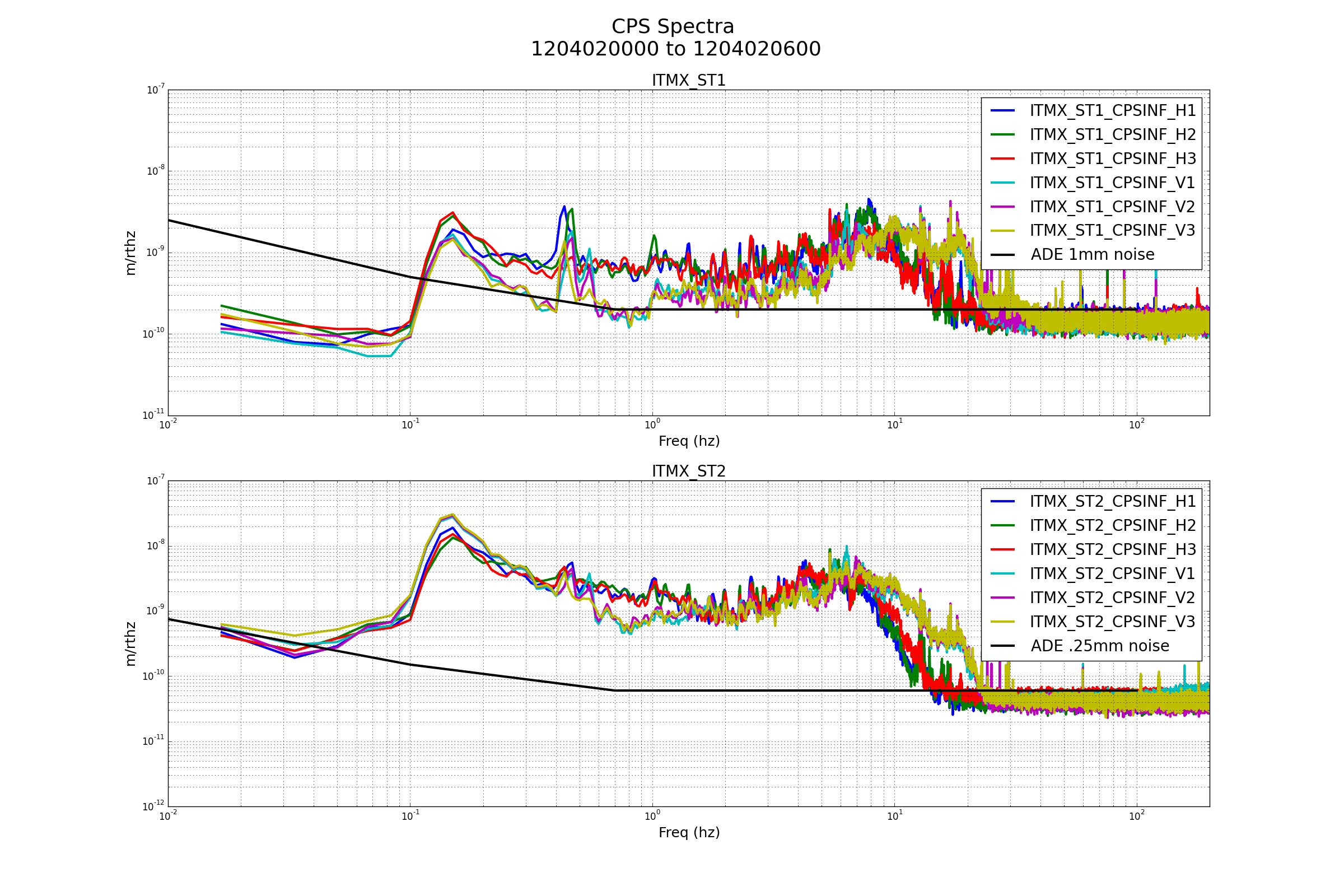
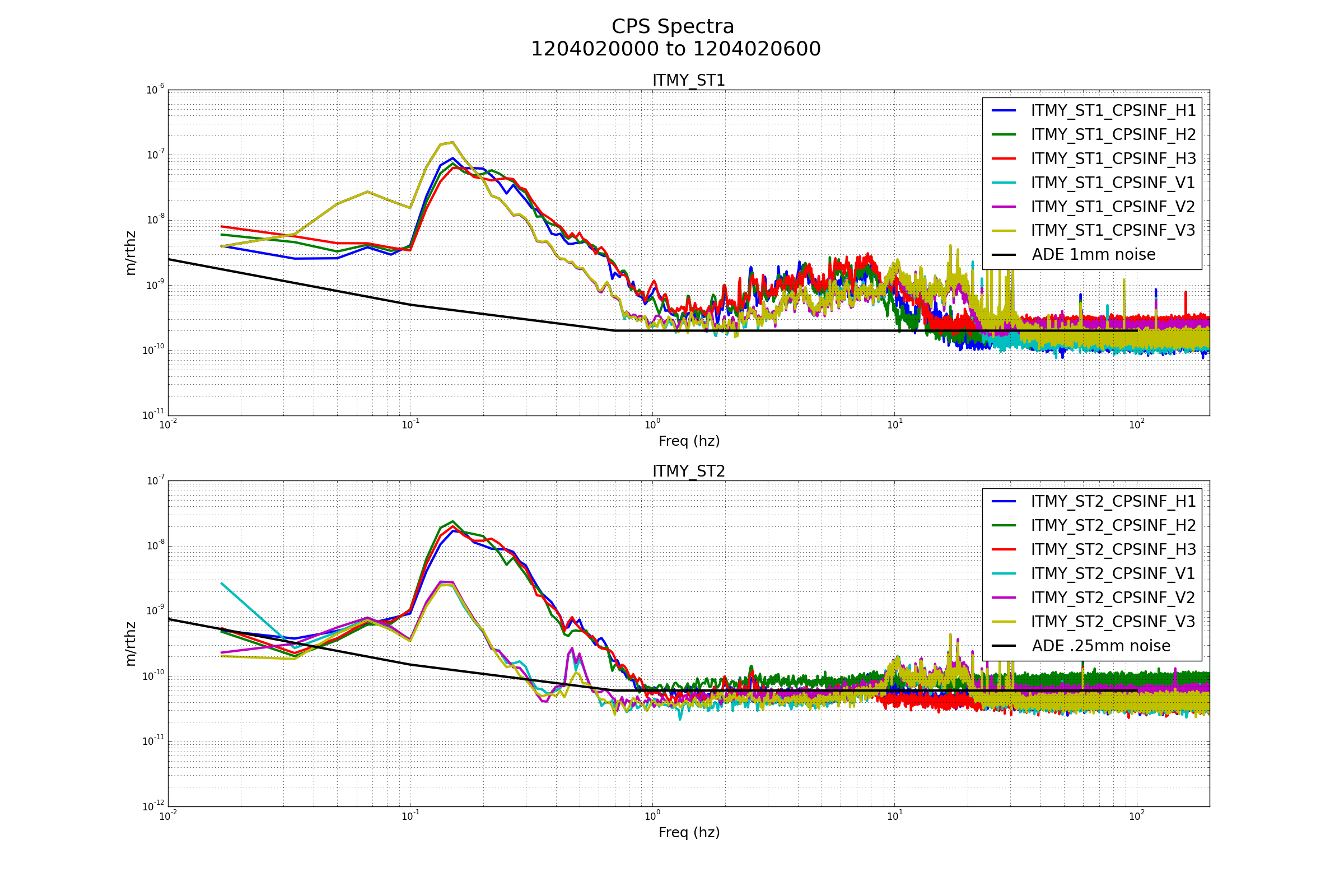
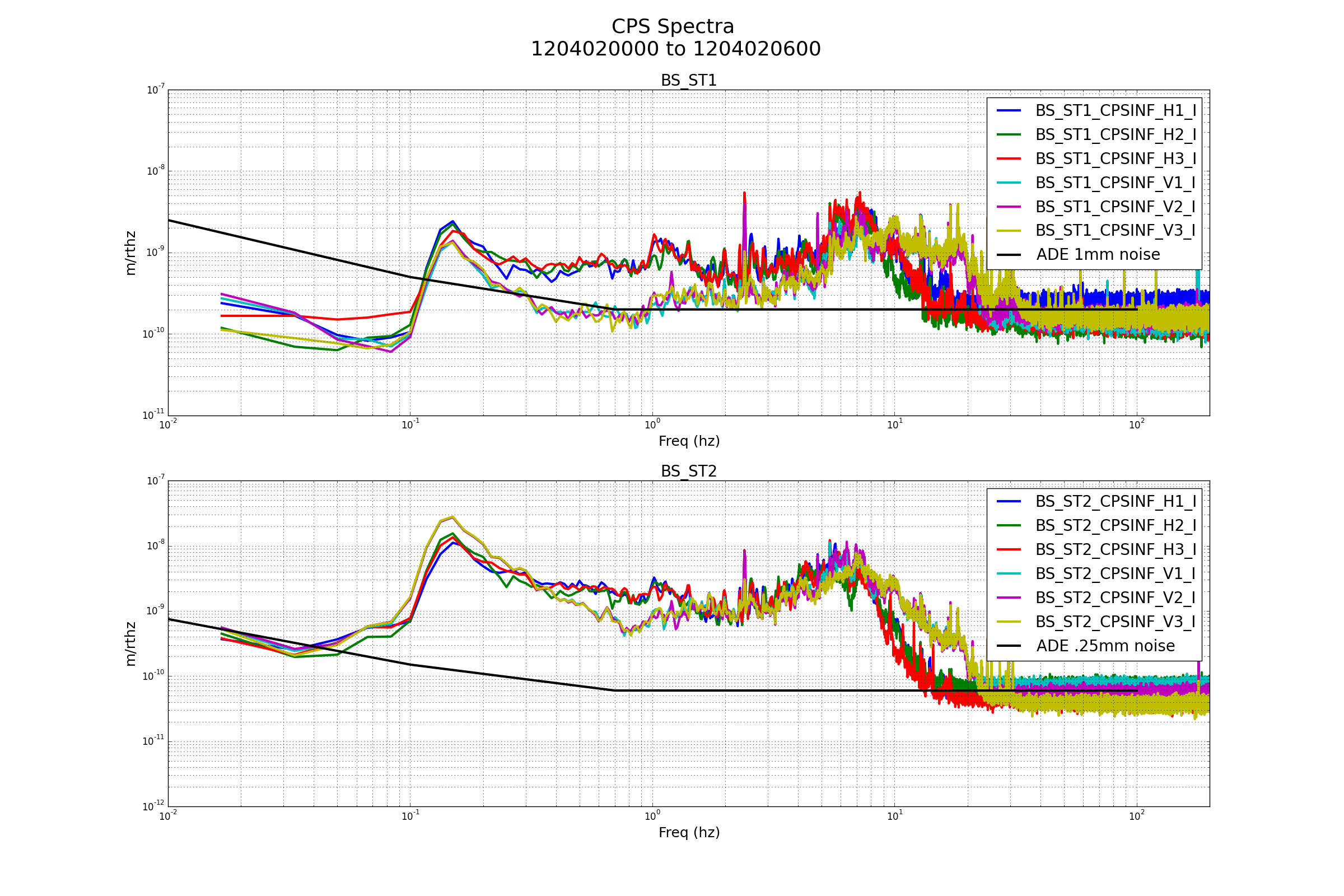

{kind=link}
05:05 Local time
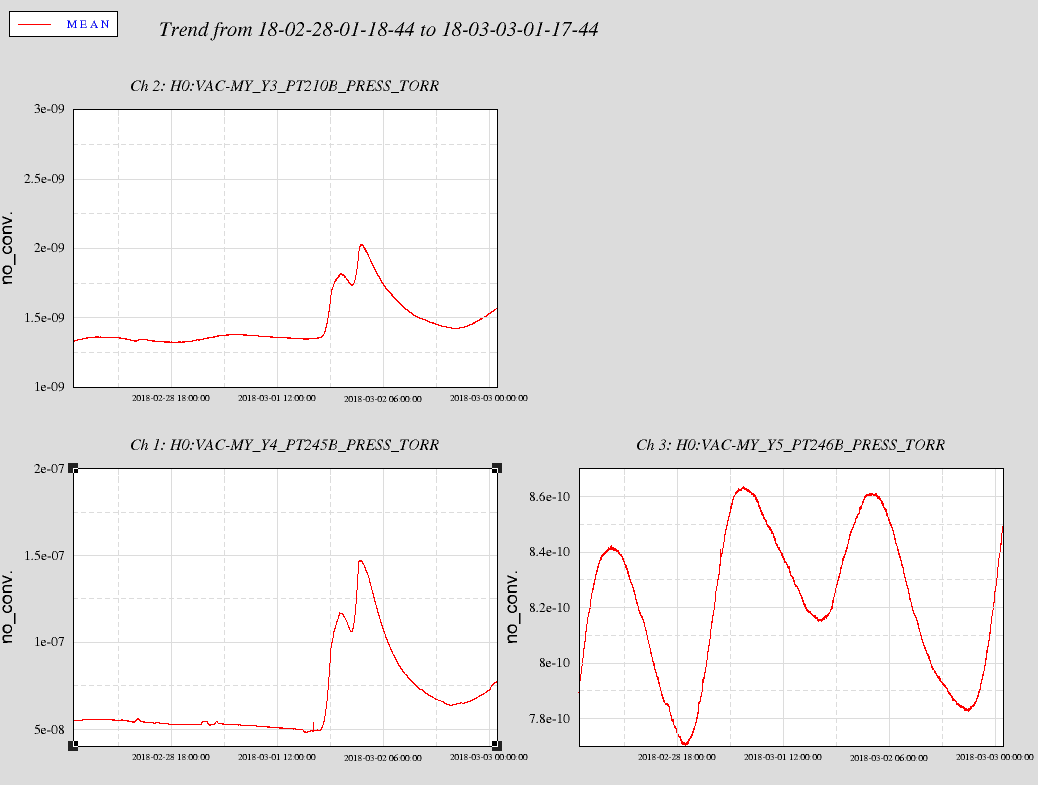
PT246B = 9.31 x 10-10 Torr.
PT245B = 9.97 x 10-07 Torr.
PT210B = 9.54 x 10-09 Torr.
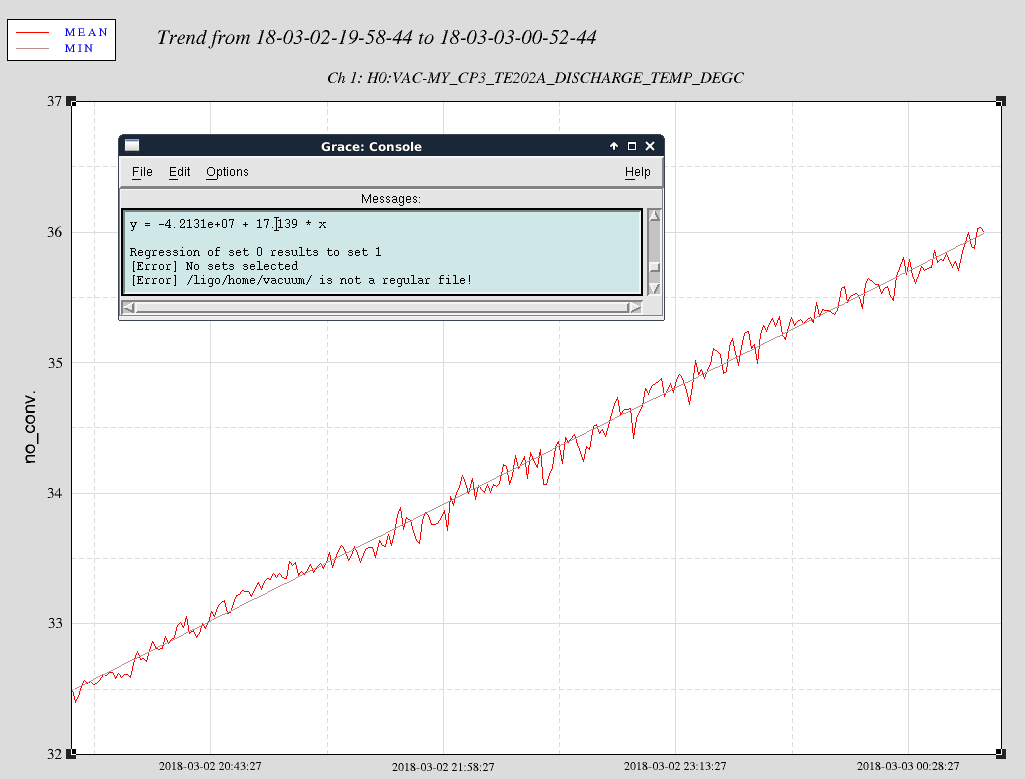
TC3 = 45.4 oC
TC4 = 63.6 oC