jeffrey.bartlett@LIGO.ORG - posted 16:08, Thursday 13 April 2017 (35534)
Ops Day Shift Summary
Ops Shift Log: 04/13/2017, Day Shift 15:00 – 23:00 (08:00 - 16:00) Time - UTC (PT)
State of H1: Locked at NLN
Intent Bit: Commissioning
Support: Sheila,
Incoming Operator: Travis
Shift Summary: Run A2L check script. Yaw is up to 0.8, Pitch is below the reference. LLO being down; ran the A2L repair script. Both Pitch and Yaw are below the reference.
Per Keita - Take the IFO to Commissioning while LLO is down.
After relocking from commissioning Lockloss, A2L YAW was up to 0.9. Ran the A2L repair script.
Back into Commissioning while LLO is down. Robert, Jenne, & Vaishali working on the IOT table. Will come out when LLO comes back up.
Activity Log: Time - UTC (PT)
15:00 (08:00) Take over from Nutsinee
15:54 (08:54) Drop out of Observing to run A2L repair script
16:05 (09:05) Back into Observing
16:44 (09:44) Christina – Going to Mid-X
17:05 (10:05) Drop out of Observing while LLO is down for commissioning
17:08 (10:08) Robert – Going into the LVEA for commissioning work
17:15 (10:15) Lockloss – Commissioning and small earthquake
18:00 (11:00) Bubba – Going to End-Y to look for engine hoist
18:05 (11:05) Karen – Cleaning in the Optics Lab
18:33 (11:33) Bubba – Back from End-Y
18:35 (11:35) Relocked at NLN
18:36 (11:36) Karen – Out of the Optics Lab
18:40 (11:40) Robert – Going into the LVEA for
18:50 (11:50) Robert – Out of the LVEA
18:50 (11:50) Damp PI Mode-28
18:51 (11:51) Ran A2L script due to elevated Yaw mode
19:04 (12:04) Back in Observing
20:50 (13:50) Bubba & Dick – Going into the Optics Lab to look at the cleanrooms
21:11 (14:11) Set Intent Bit to Commissioning – aLOG #35528
21:15 (14:15) Dick & Bubba – Out of the Optics Lab
22:30 (15:30) Robert, Jenne, & Vaishali – In the LVEA for commissioning
23:00 (16:00) Turn over to Travis

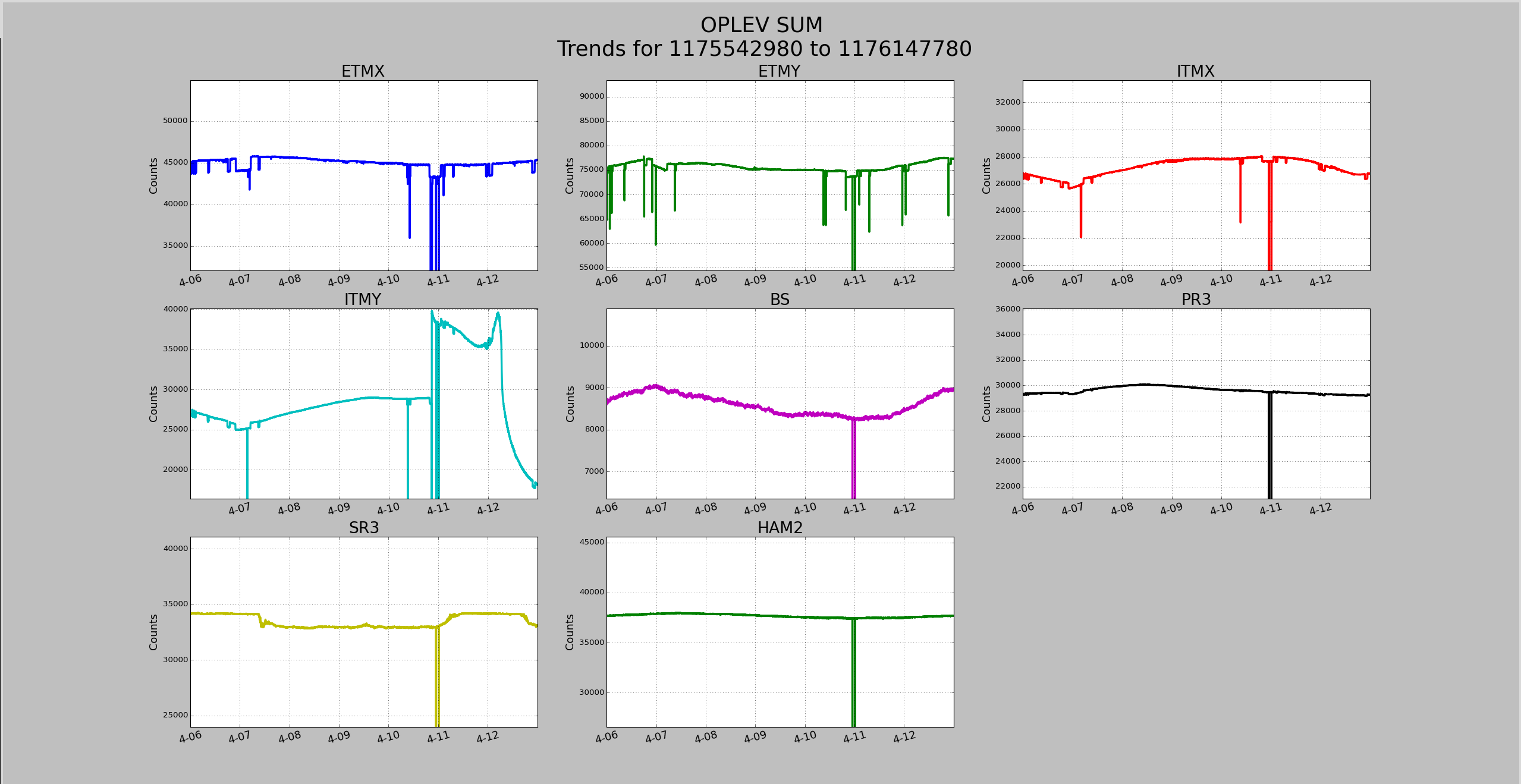
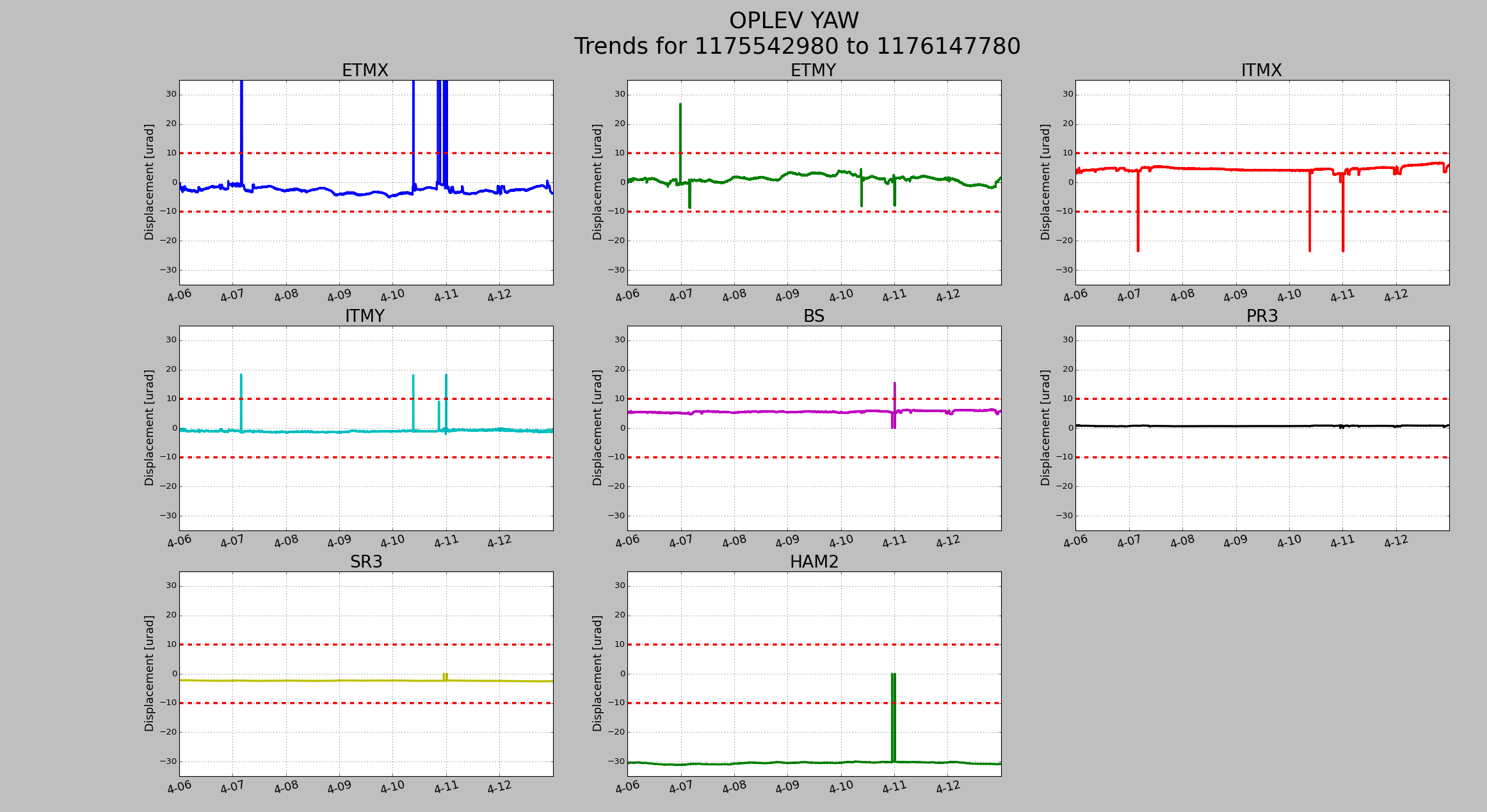
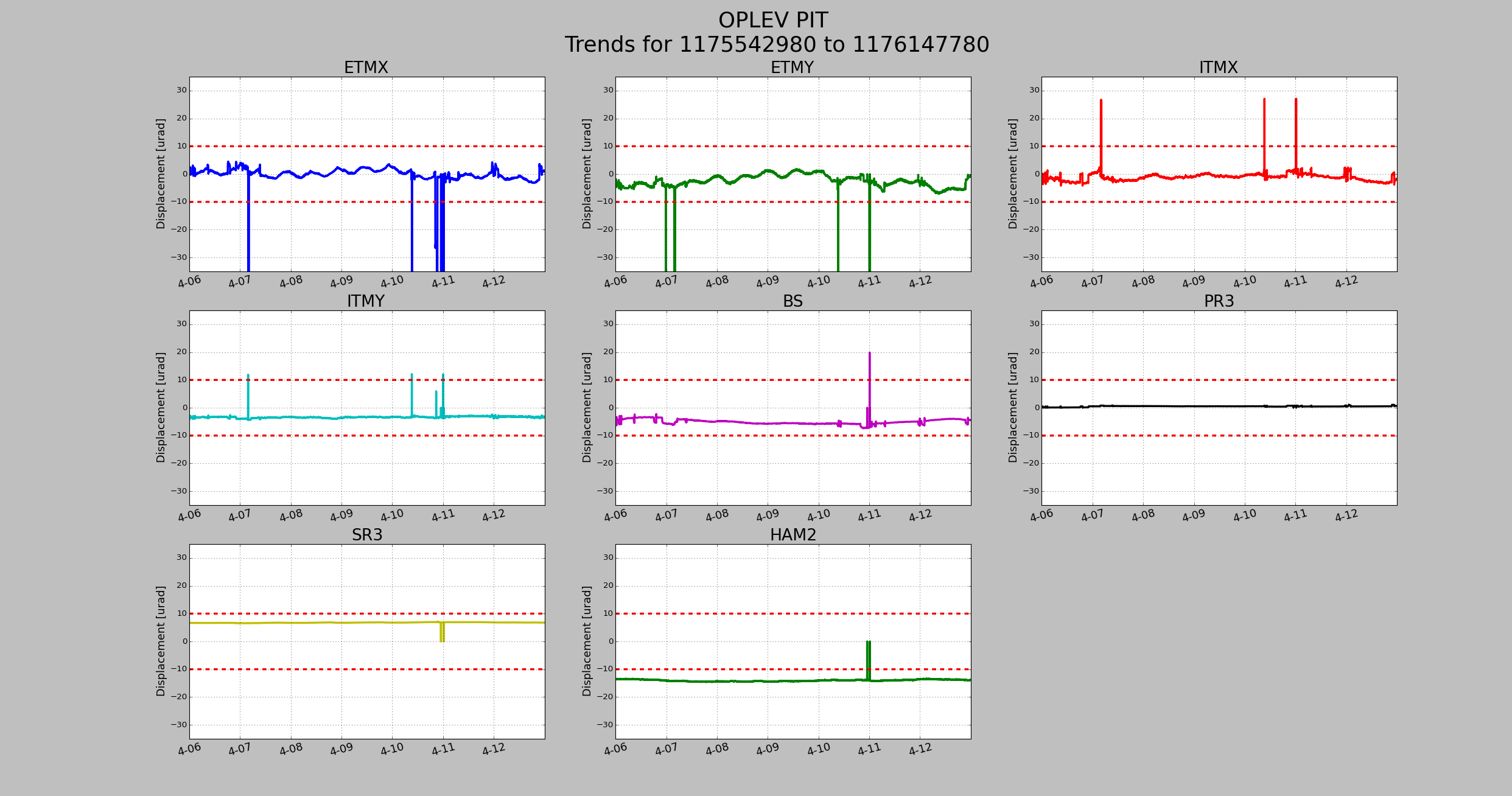
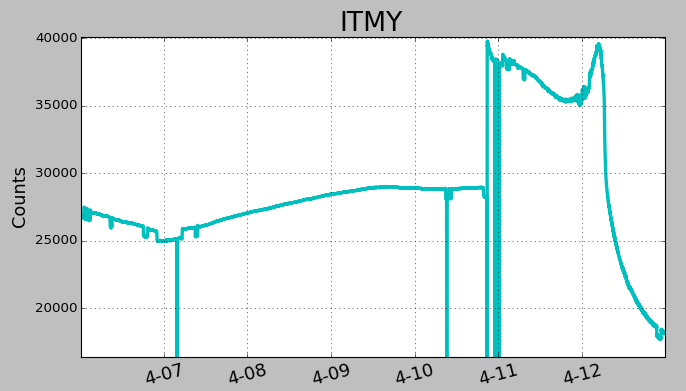
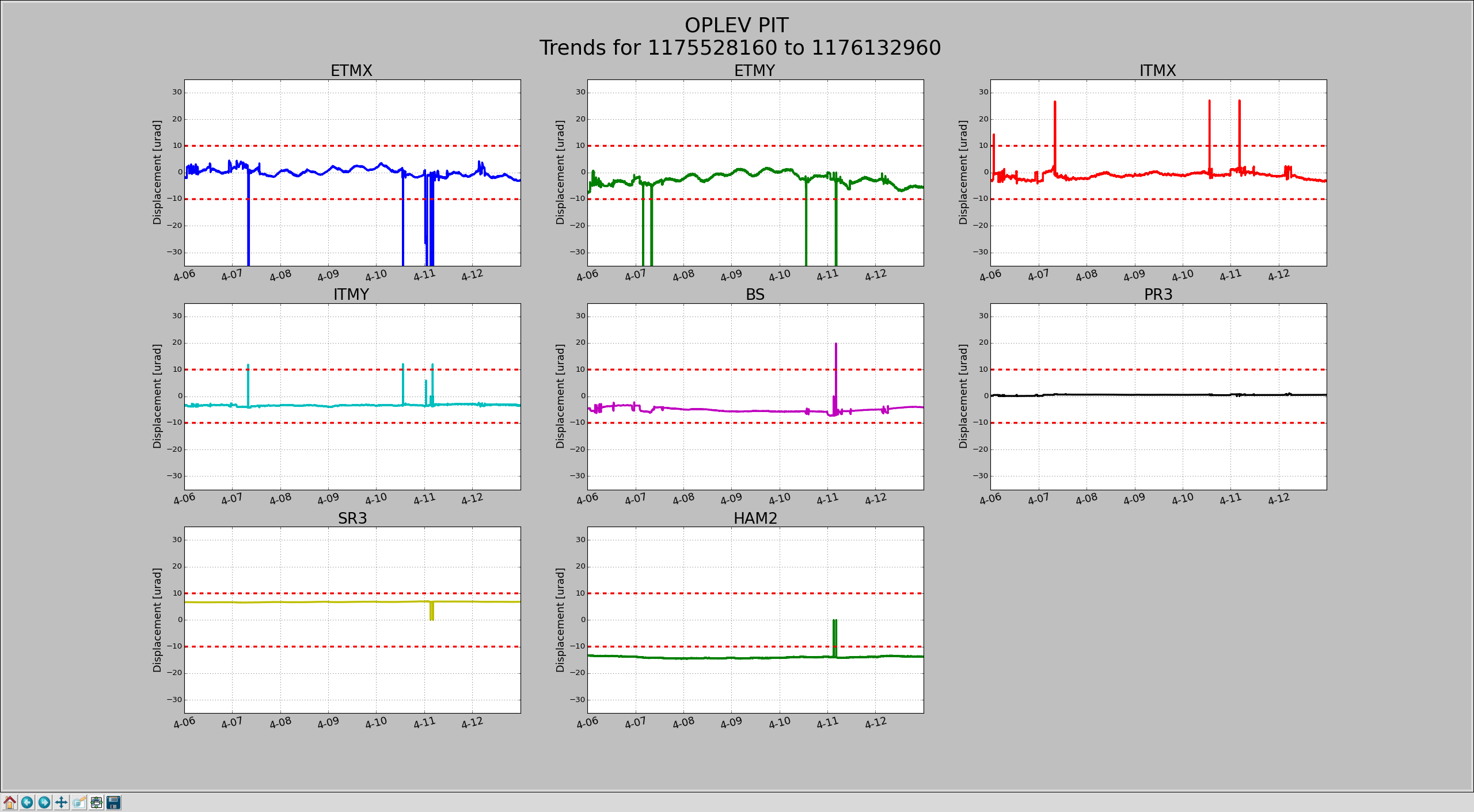
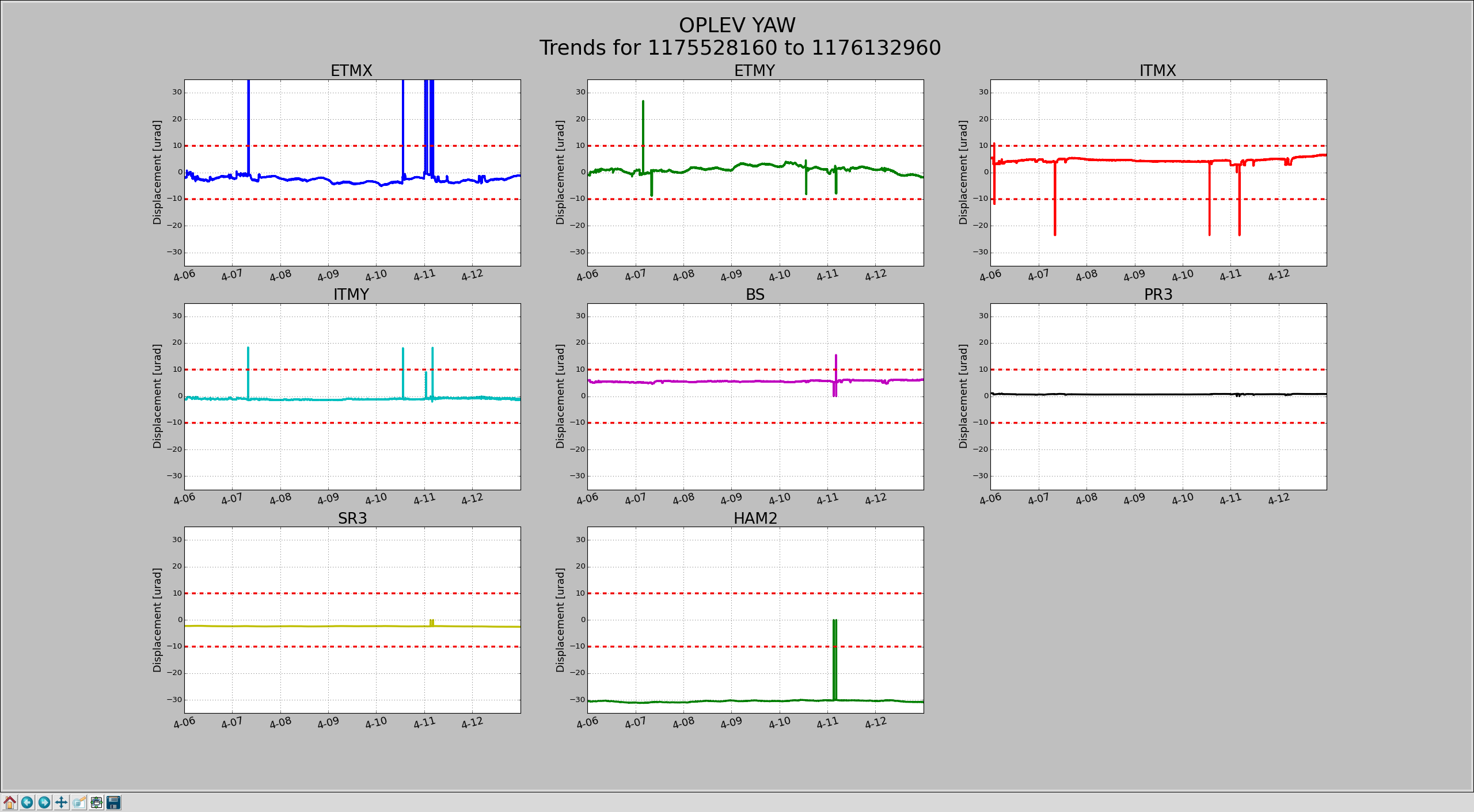
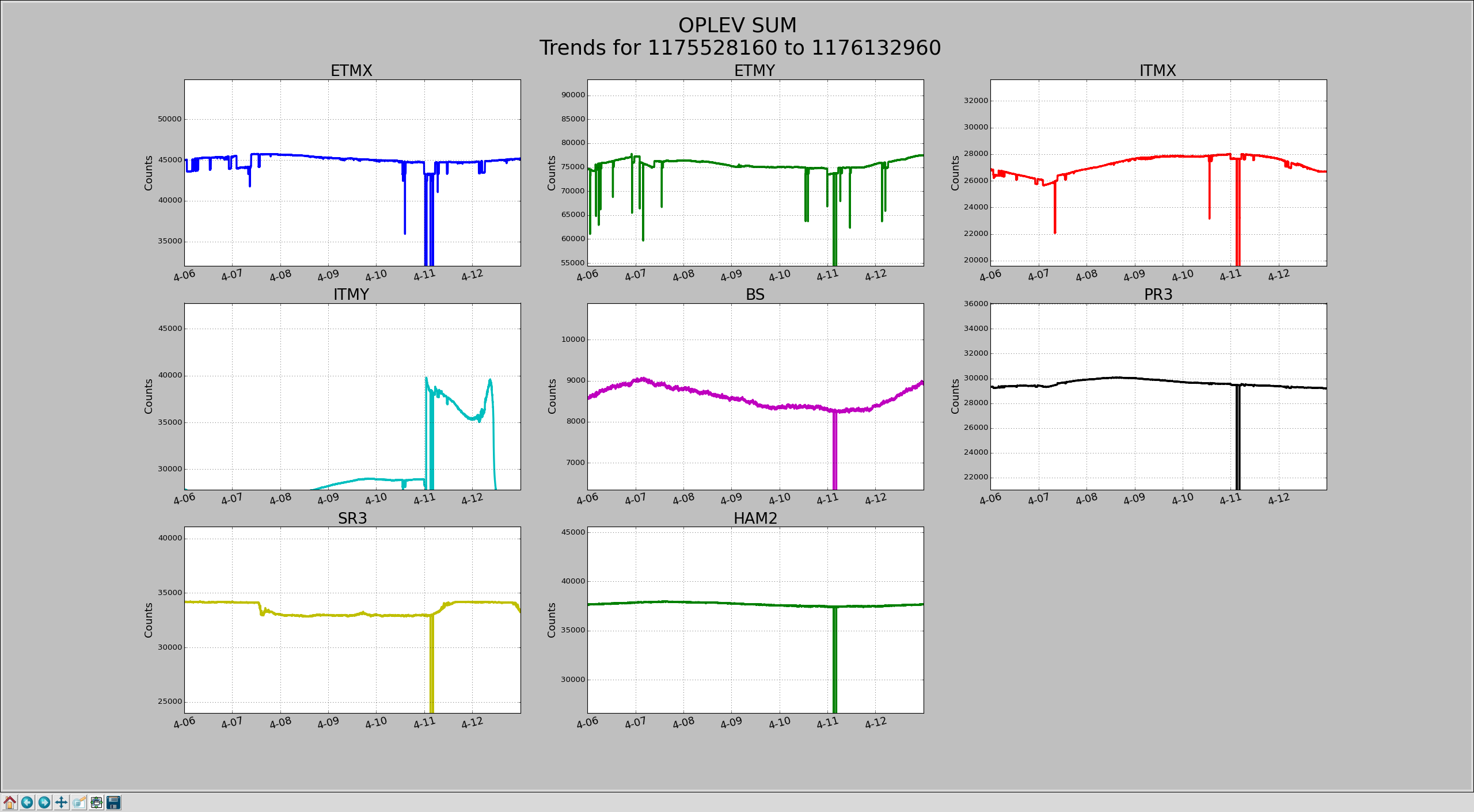
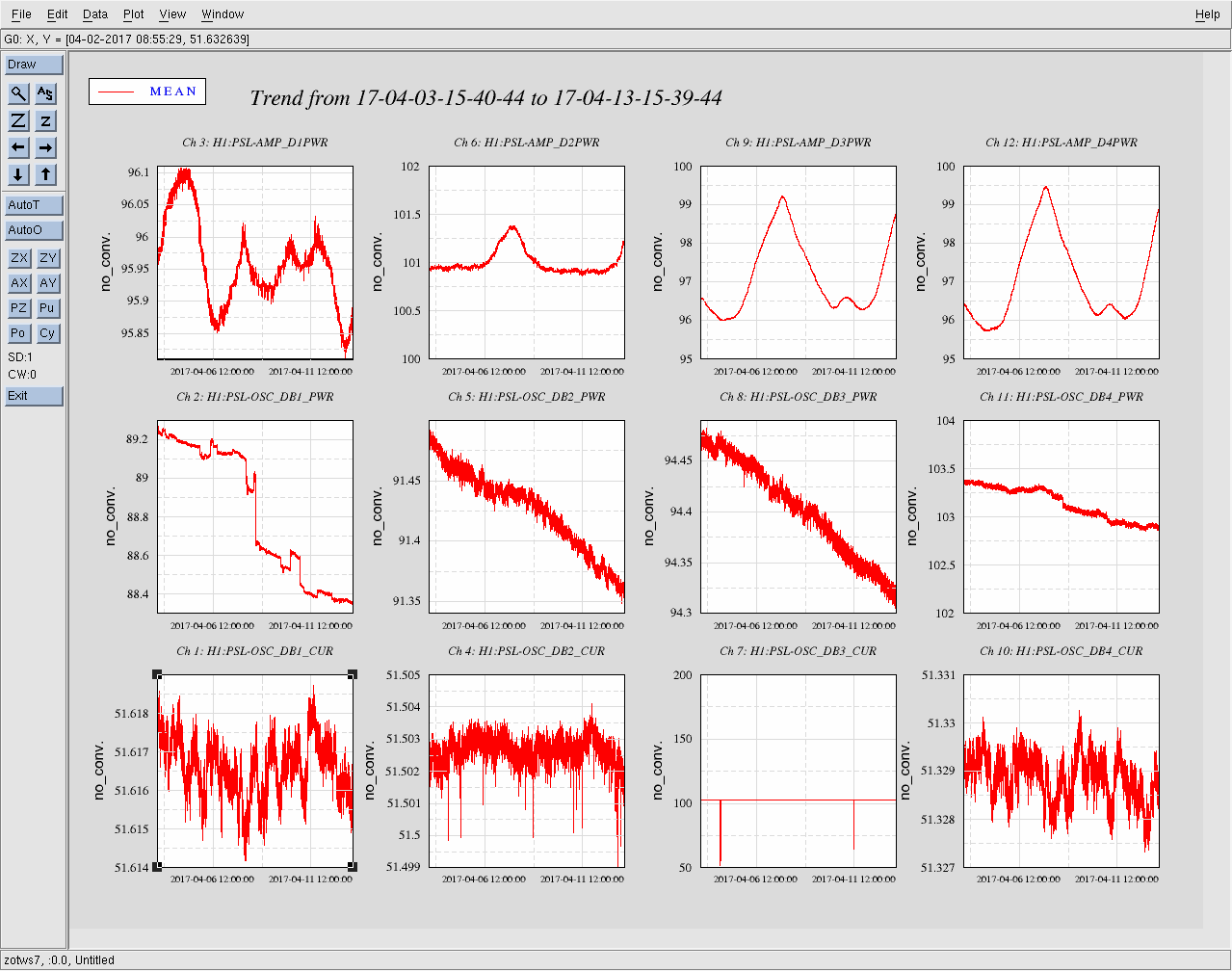

Lower limit is now set to 2000Hz instead of 1000hz.