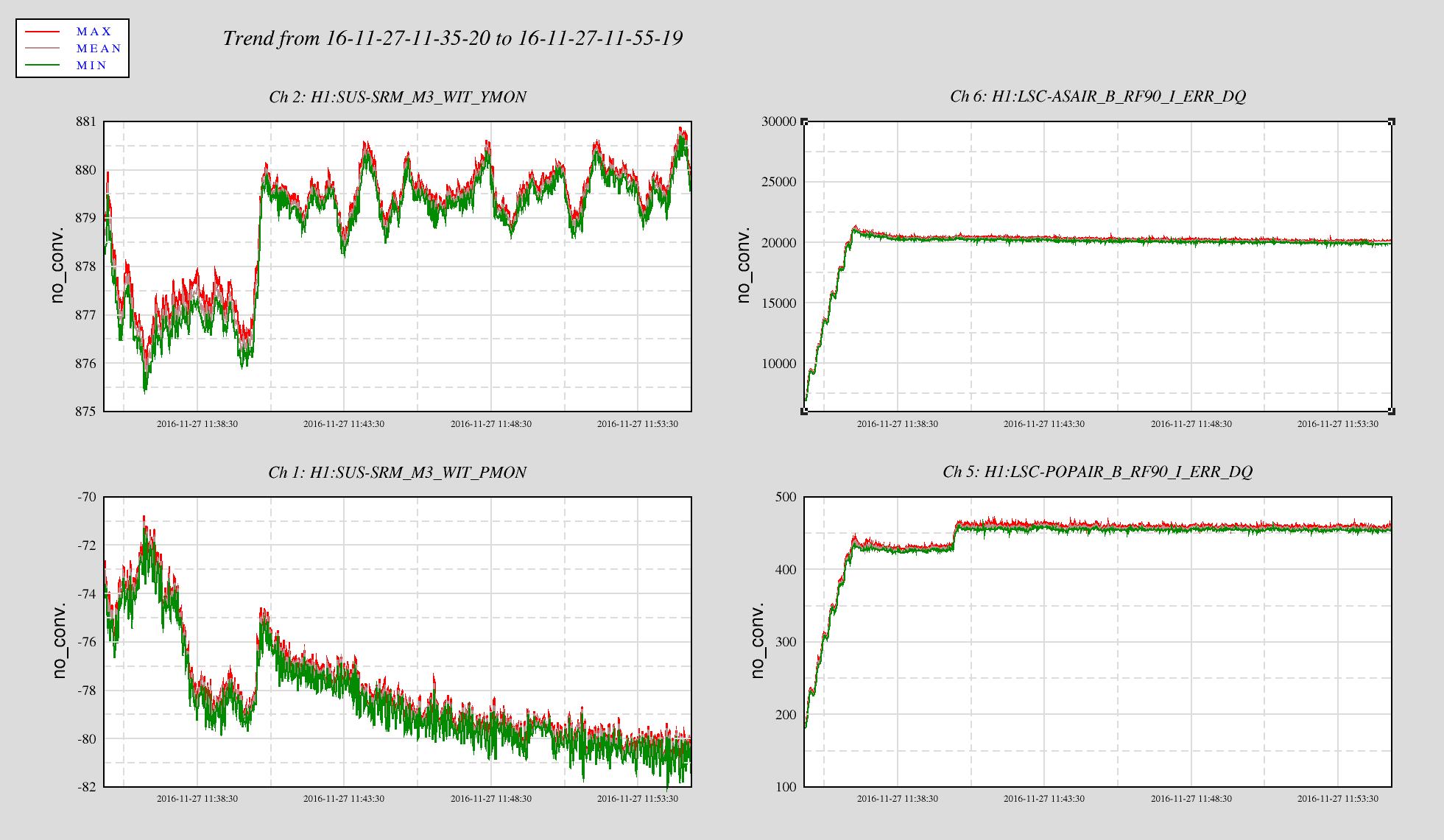
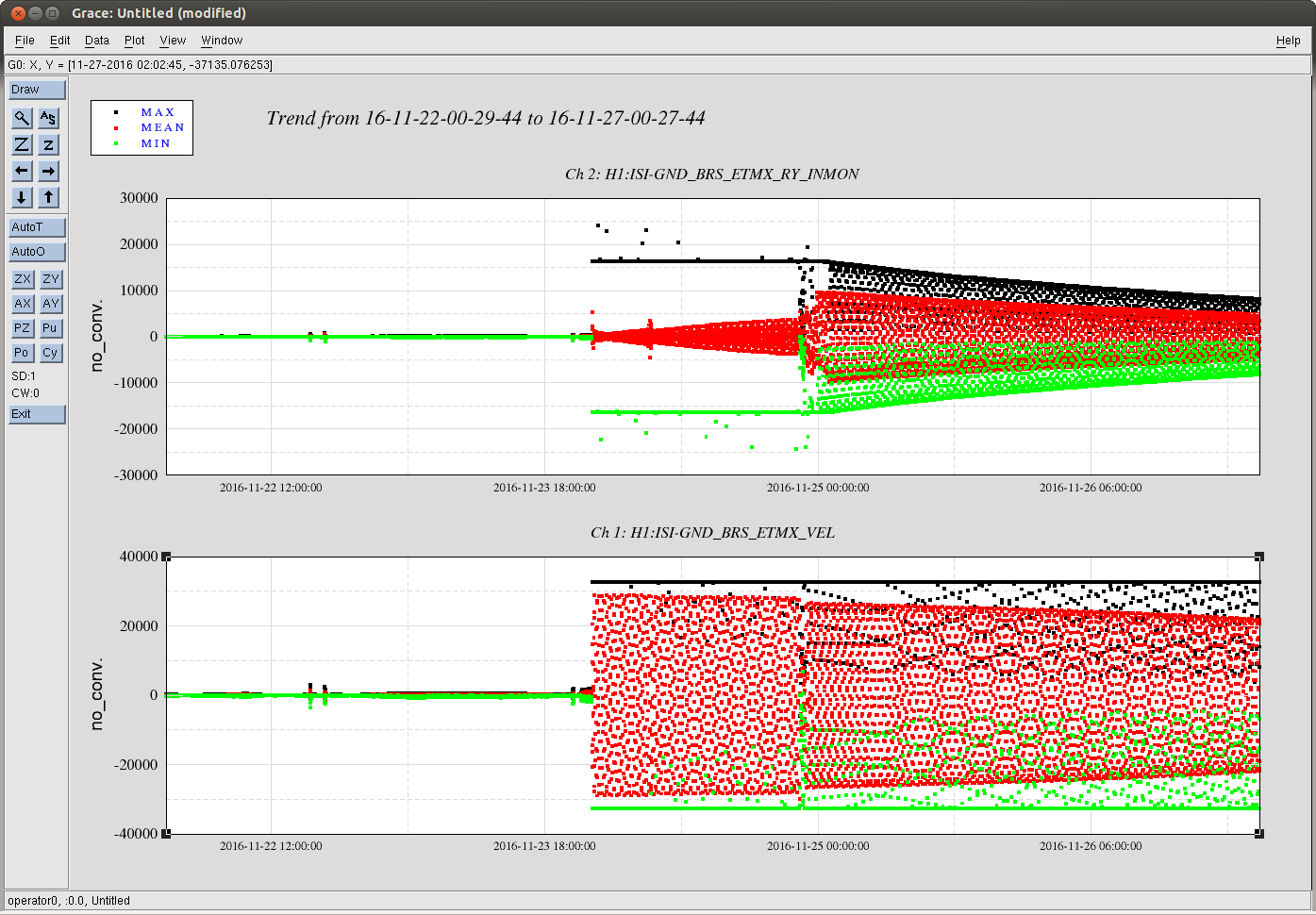
Peaks associated with BSC2 are the second largest source of environmentally driven peaks in DARM (next to the jitter peaks from vibration at the laser input) that we have found so far. We noticed that peaks in DARM at about 70, 105, and 198 Hz were amplified by acoustic injections in the LVEA. We tracked this to the beam splitter chamber and found that these peaks, as well as other peaks in DARM at 619.5 and 620.5 Hz, were increased by HEPI but not ISI injections (see Figure 1). This suggests that the culprit is on stage 0 of the seismic isolation, which is excited by HEPI but much less excited by ISI injections. The ITM elliptical baffles, hanging from stage 0 (Figure 2) are the most likely sources, either through scattering or clipping. Scattering would be our first guess, but I think we should also consider clipping because the peaks are not quite as broadened by sidebands as is typical of high Q peaks coupling through highly nonlinear scattering. The elliptical baffles have been previously implicated by a similar HEPI/ISI test (https://alog.ligo-wa.caltech.edu/aLOG/index.php?callRep=26016).
To be sure that the peaks were associated with stage 0 and not the table top, we made sure that the shaking was greater at the stage 2 GS13s for the ISI shaking than for the HEPI shaking, on all 3 axes, at the peak frequencies. Even though the shaking of the table was greater for the ISI injections than for the HEPI injections, the peaks were only increased by the HEPI injections (Fig. 1).
If we have time, we would like to try minimizing the peaks by putting DC offsets into HEPI.
Anamaria, Robert