ryan.crouch@LIGO.ORG - posted 22:06, Sunday 15 June 2025 - last comment - 10:29, Monday 16 June 2025(85063)
OPS Sunday EVE shift summary
TITLE: 06/16 Eve Shift: 2330-0500 UTC (1630-2200 PST), all times posted in UTC
STATE of H1: Observing at 147Mpc
INCOMING OPERATOR: Corey
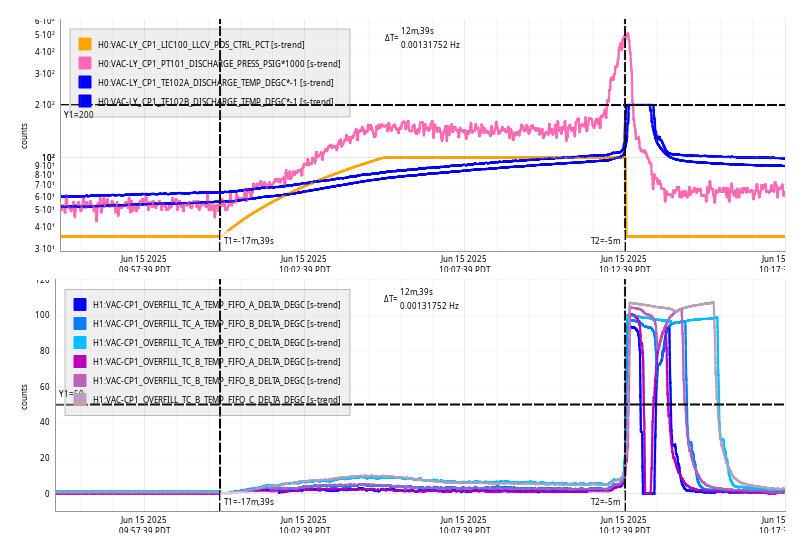
SHIFT SUMMARY: 1 lockloss with an automated relock without an IA, at the start of both locks today the SQZers' ASC took us in the wrong direction and degraded the range. I was not able to recover it the second time.
LOG: No log
- 23:10 UTC Observing
- 00:16 UTC lockloss
- The IMC struggled to relock, but it was able to lock after 7 minutes
- 01:18 - 03:14 UTC The wifi was out alog85064
- 01:32 UTC Observing
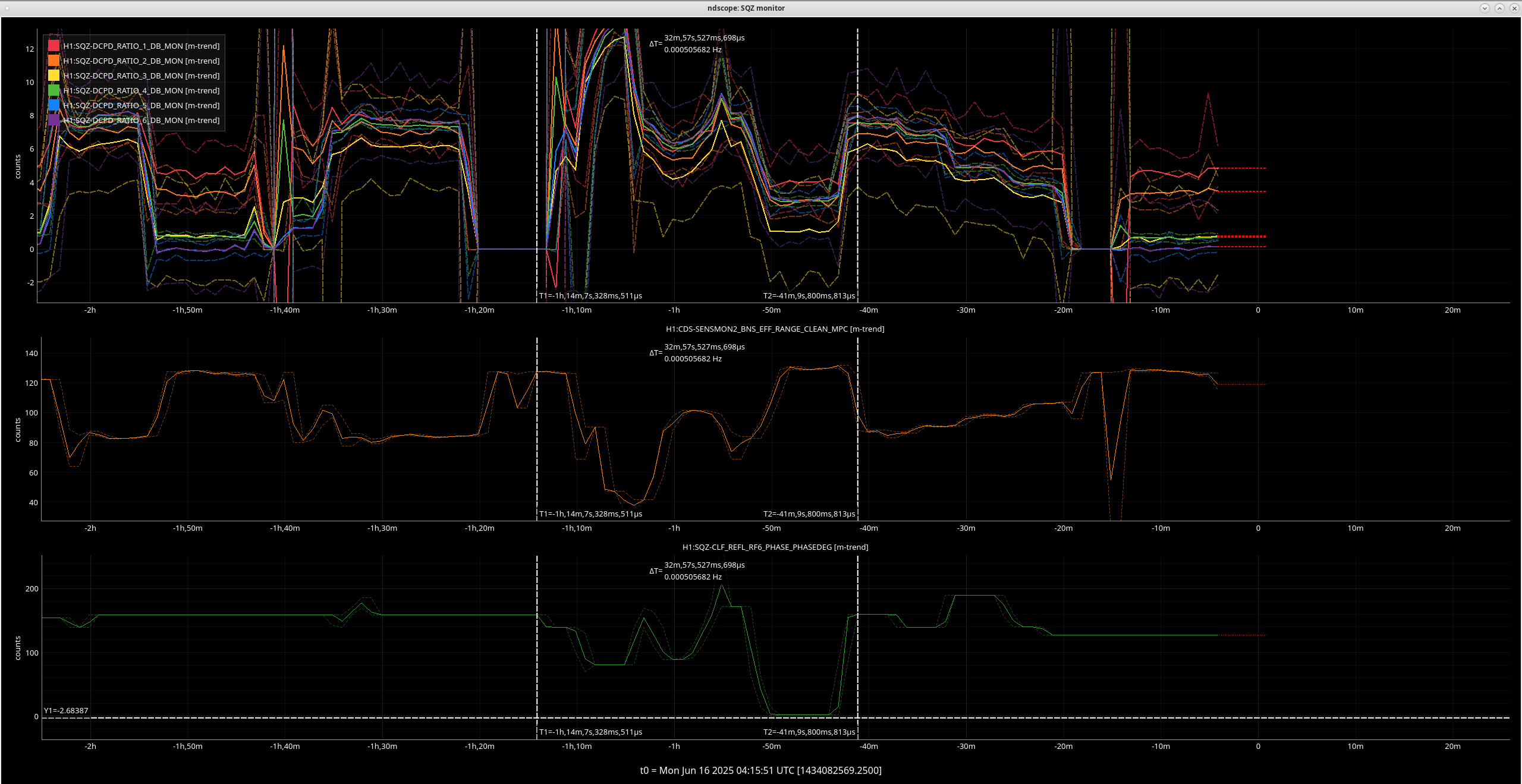
- 01:59 UTC I dropped observing as SQZ ASC was running away again, I had no access to the wiki or alog for a bit of this SQZ snafu :(
- Running SCAN_ALIGNMENT and ANG made it worse, running RESET made it even worse
- Even when I returned the ZMs to were they were when SQZing was good earlier and using the same angle its still bad, worse than no SQZing
- I double checked the ZM alignment based on top mass osems, and I looked at FC1&2
- After consulting with Sheila (rerun SCAN_ALIGN and ANG, after which I tried manually scanning the ANG and I could only get ~130 Mpc around 1-2degrees) and Naoki popping in to help (try reverting everything) I still couldn't recover SQZing so Sheila suggested to go into Observing with no SQZing for now
- I set the Flag for asc42 to False in sqzparams and reloaded SQZ_MANAGER after first talking to Sheila
- 04:03 UTC Observing (with no SQZing)
- 04:48 UTC dropped observing again to try to bring back SQZing
- 05:05 UTC observing with squeezing
Images attached to this report

Comments related to this report
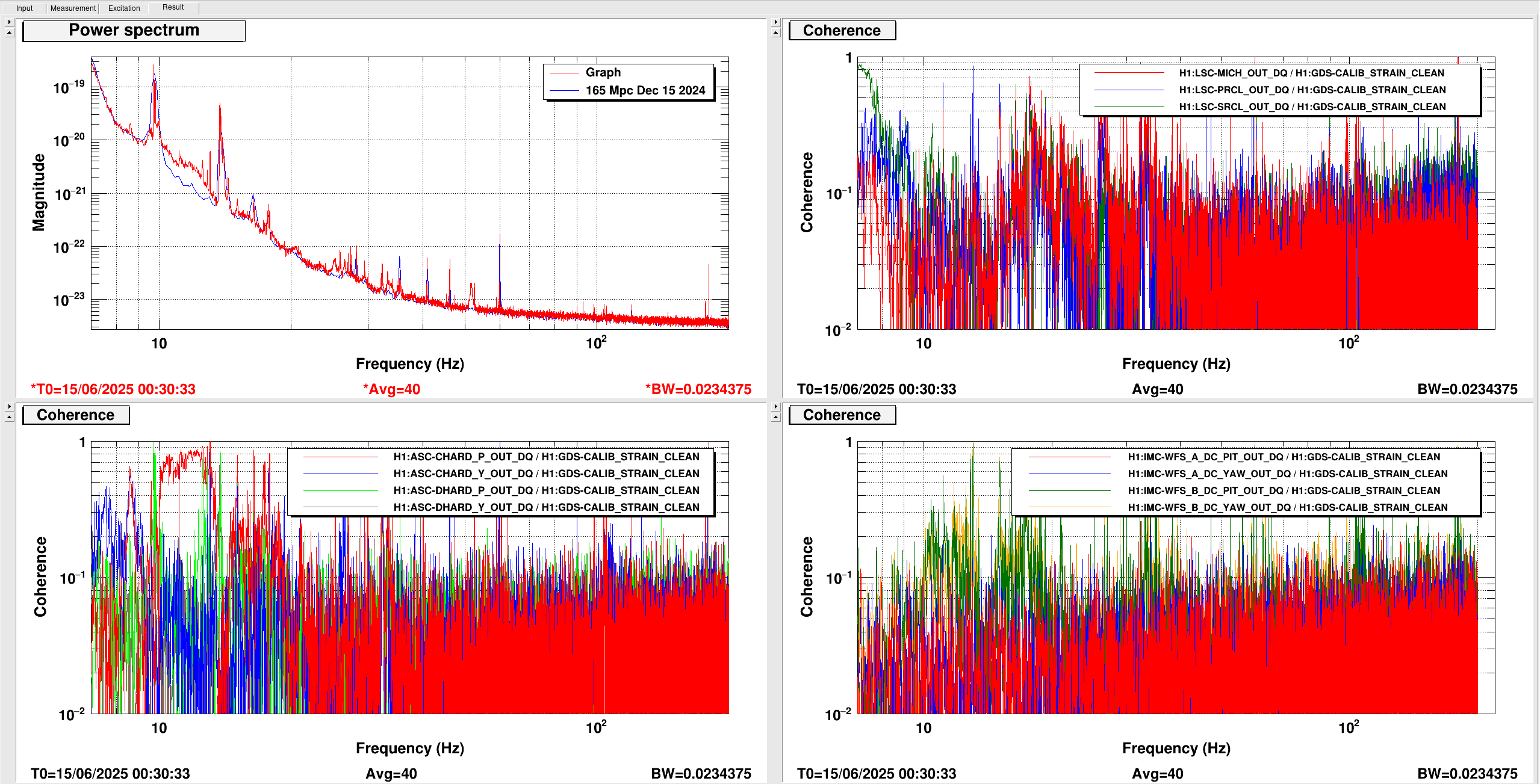
There was two issues with the SCAN_ALIGNMENT_FDS alignment scans:
- In the the first scan, the LO was unlocked so during the whole time we just had mean SQZ so nothing was changing and all SQZ plots were flat. I'm unsure why this happened, but I have added the @LO_checker_FDS (and other checkers from FDS) to SCAN_ALIGNMENT_FDS and SCAN_SQZANG so that in the future the GRD would catch this, and relock the LO.
- Also, SCAN_ALIGNMENT_FDS currently uses an outdated value for ASQZ of (-)100deg to start the ASQZ optimization scan. This meant that all the second scan didn't optimize the ZMs or angle at best ASQZ, then after the scan was finished (for both), the sign was flipped to (+) which is also outdated and took us to even worse SQZ.
SQZ_ALIGNMENT_FDS is outdated as we haven't used it since we got the SQZ_ASC working well.
To do: find the optimum value/sign of ASQZ and put into SQZ_ALIGNMENT_FDS. Then we can try to rerun this and compare with where SQZ ASC takes us.
While adding checkers to SCAN_ALIGNMENT_FDS and SCAN_SQZANG_FDS also made an @LO_checker_FIS and added it to FIS, see changes in svn rev31848.
Also over the weekend, after running RESET_SQZ_ASC, if the sqz angle is outside of 150 to 250, it gets reset to 190, however optimal SQZ angle this last week has been 140-165 deg. So I edited this to reset the SQZ angle to 150deg if it's outside of 120 to 220 instead. Seen this as the Operator team have been using the state RESET_SQZ_ASC as the ASC has been unstable at the start of the lock (another issue we are planning to solve).