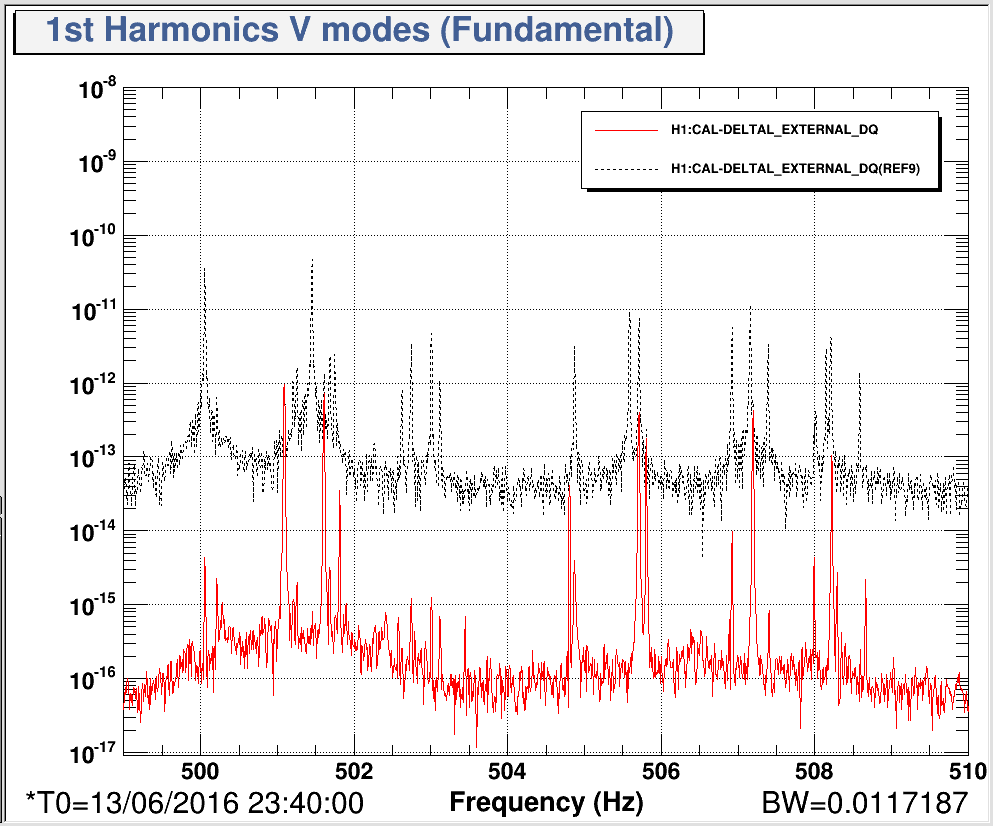
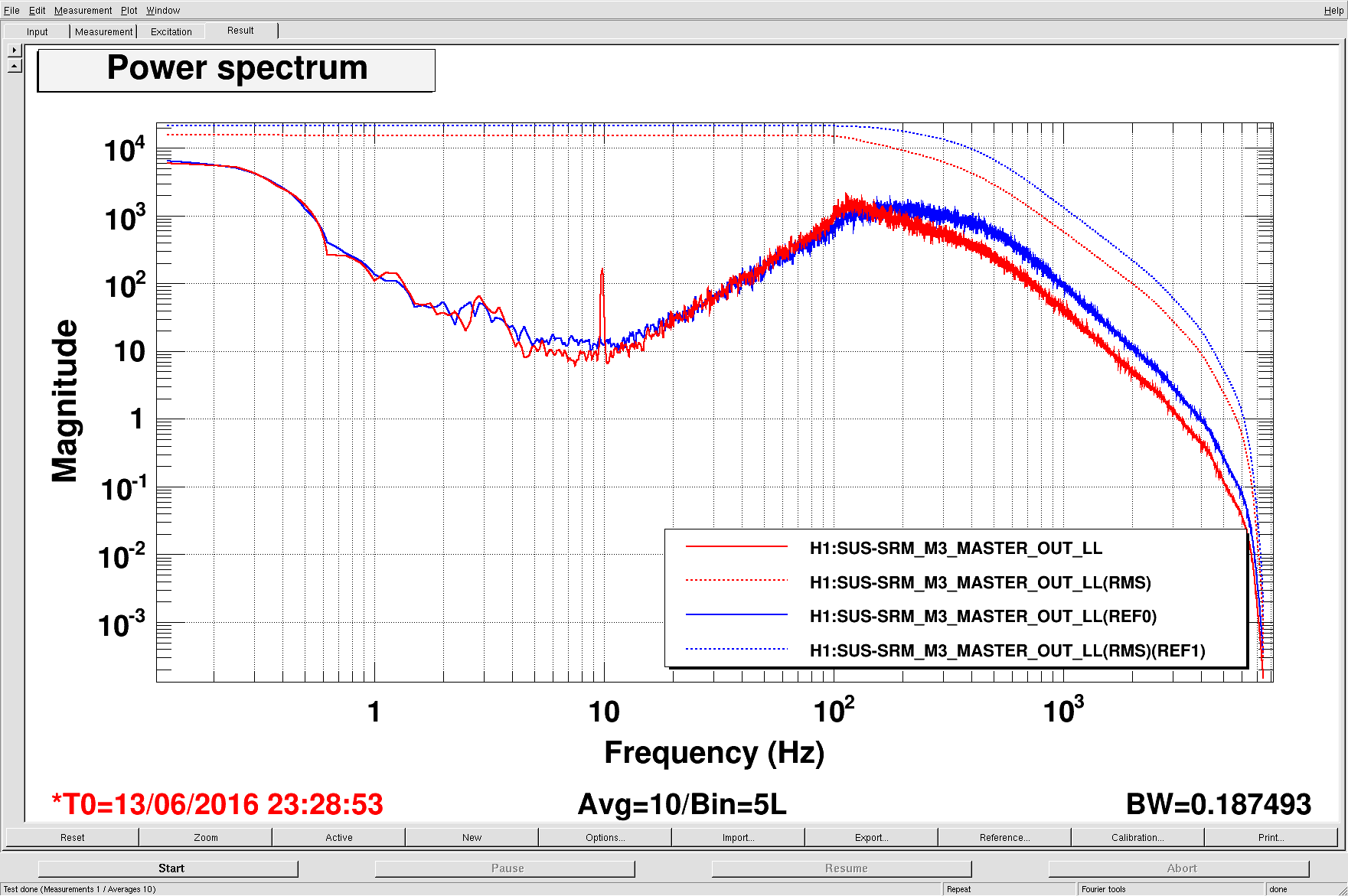
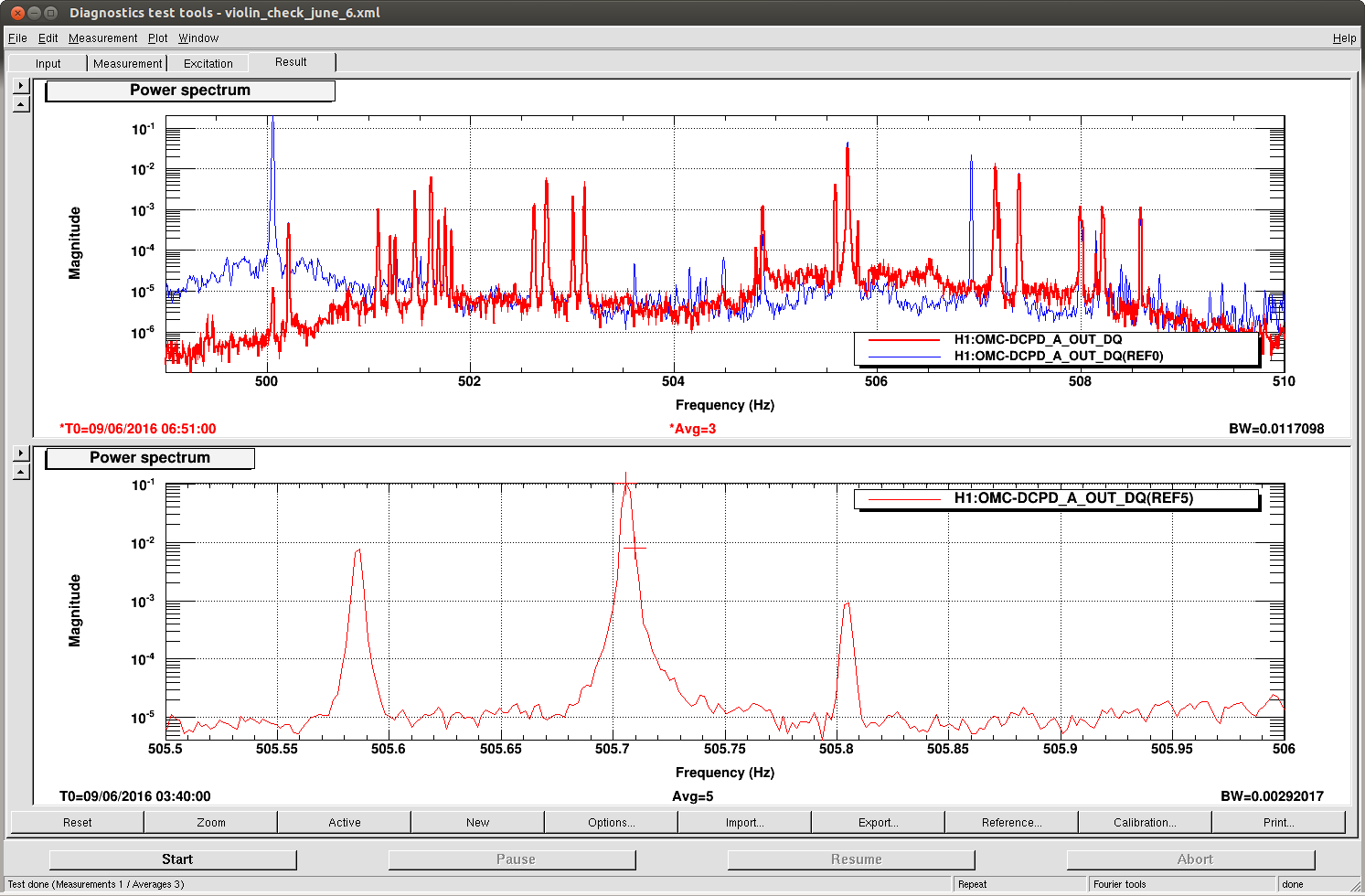
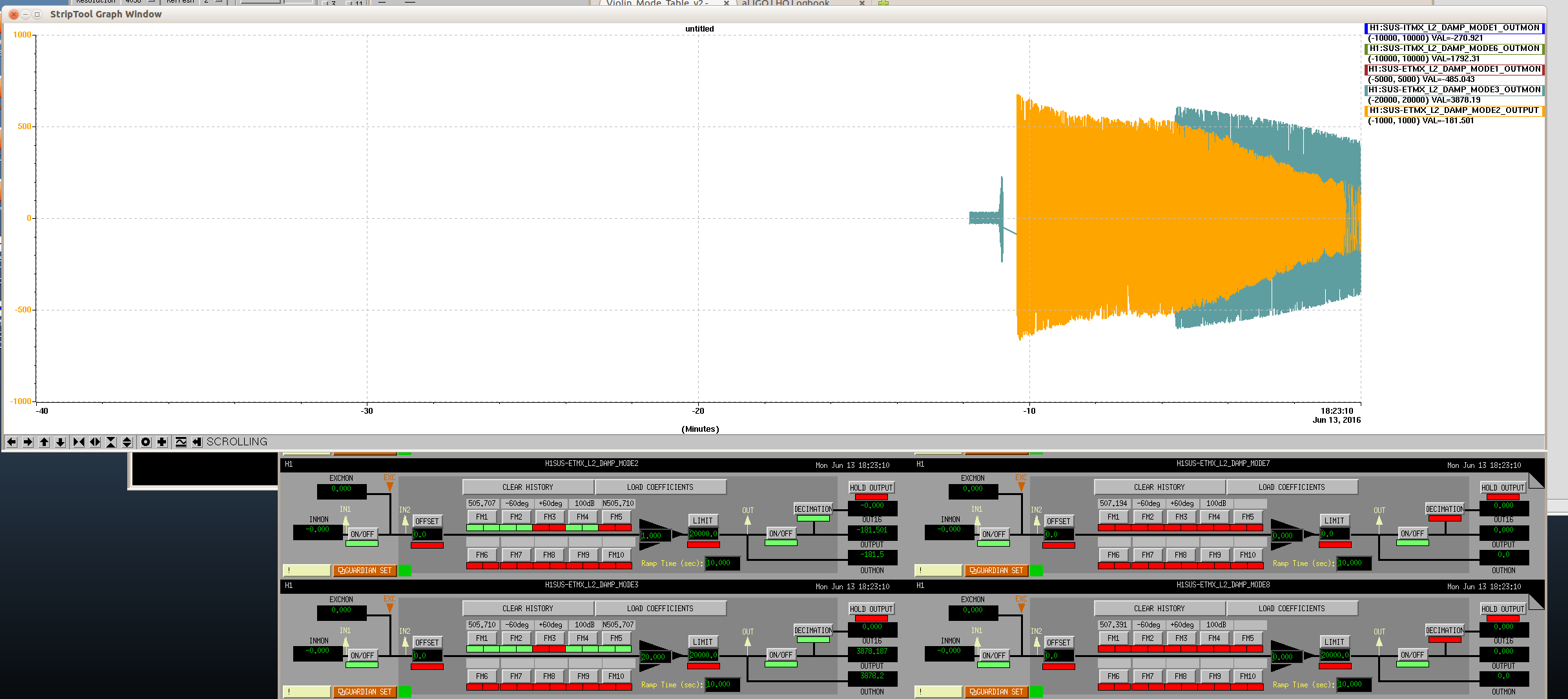
Evan, Sheila
Earlier today we had several locklosses while trying to engage the soft loops which may have been because SRM was uncontrolled and the POP90 power increased.
We searched for a better error signal for a while tonight, we looked at dither SRM and demodulating DARM (low SNR), demodulating SRCL (good signal but a large offset), POPX, some REFL WFS.
Finally we decided to try AS45I, where we had a reasonable signal with a zero crossing that gave us good sideband buildups for both pit and yaw. For pit we are using 1*ASA45I +0.76*ASB45I, while for yaw we are using ASA45I+ASB45I. The guardian is engaging these with a gain of -300 in SRC_ASC, which has worked once. It allowed us to turn on the soft loops and corrected the sideband buildups.