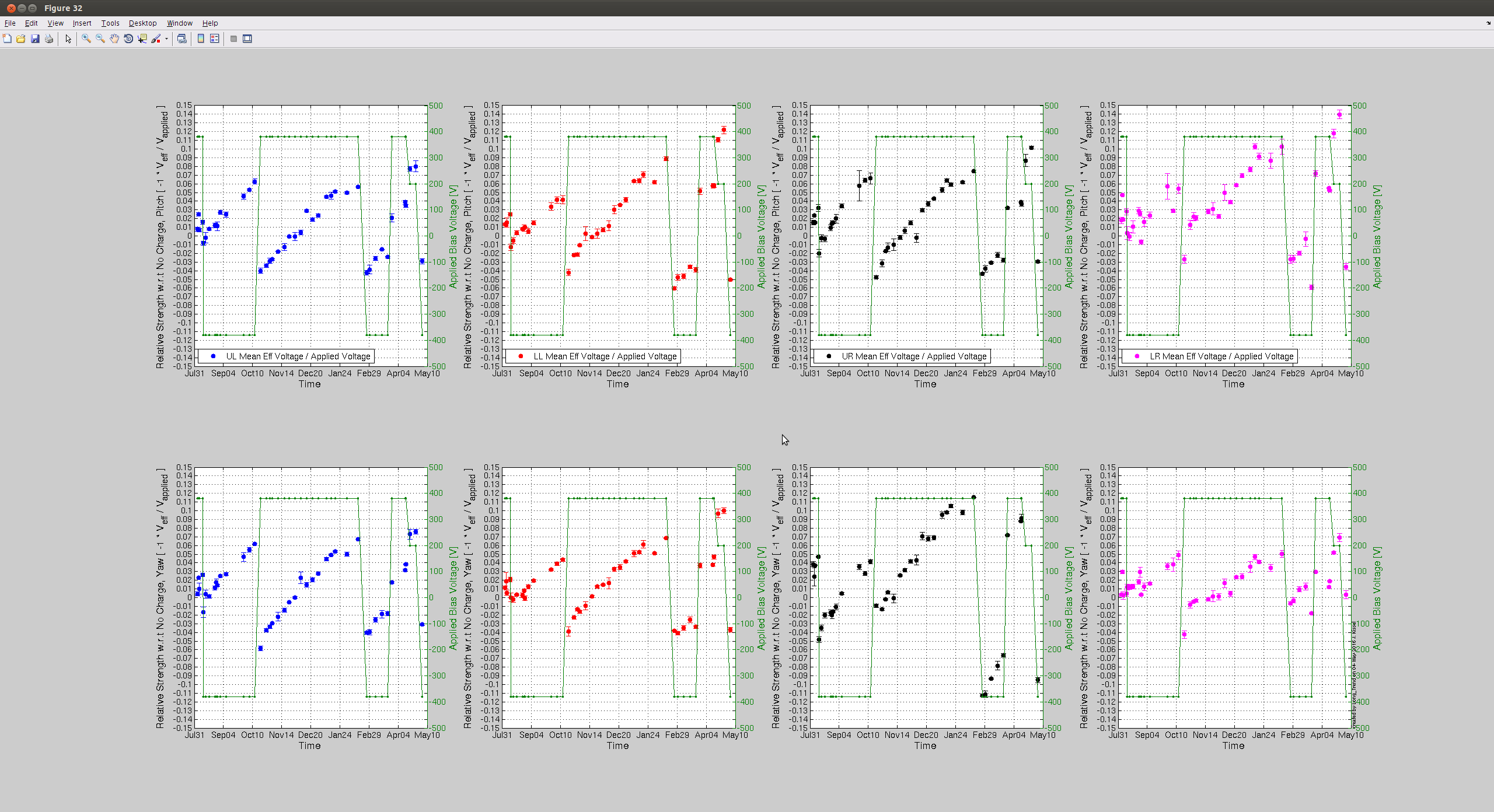
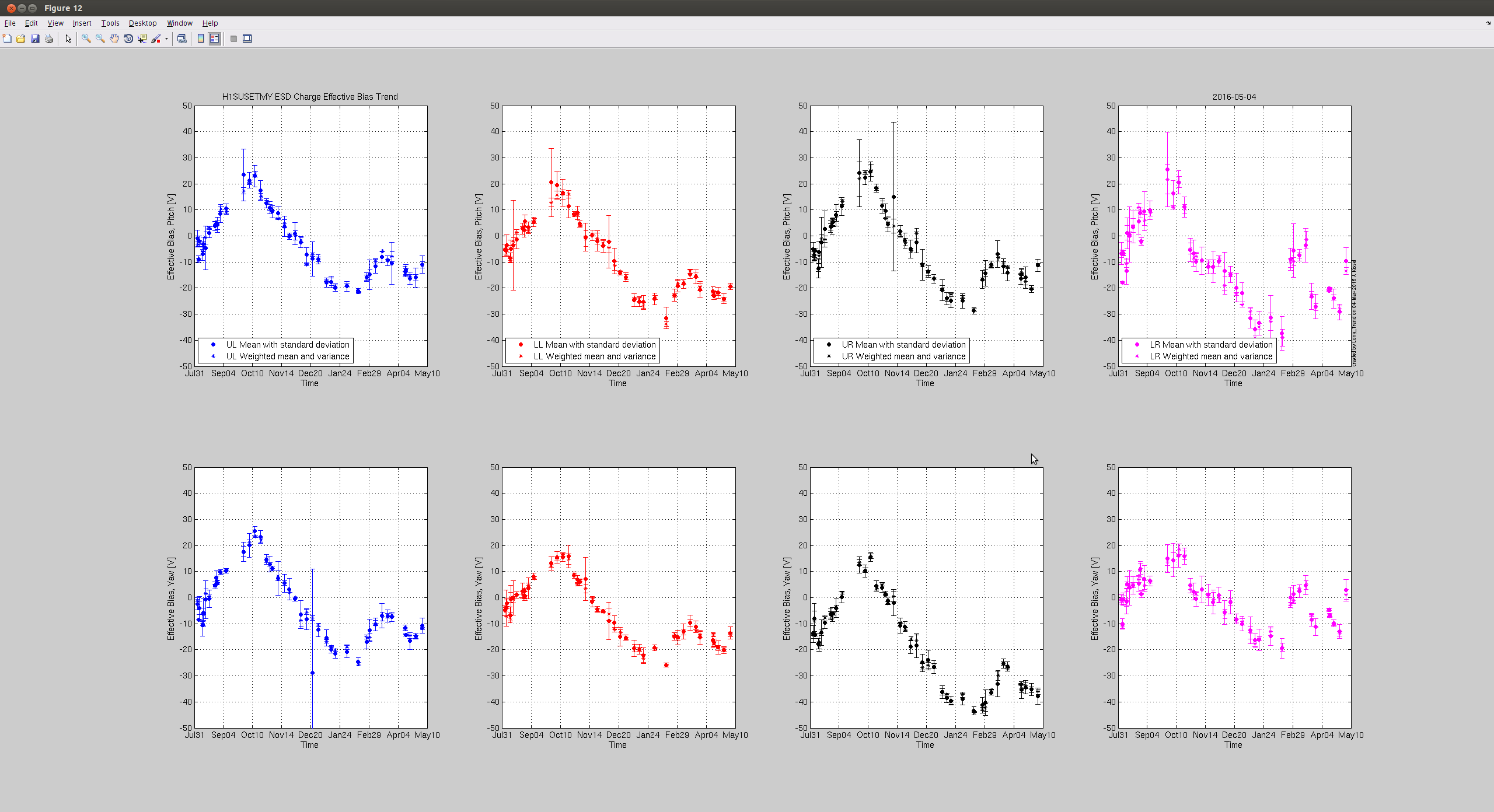
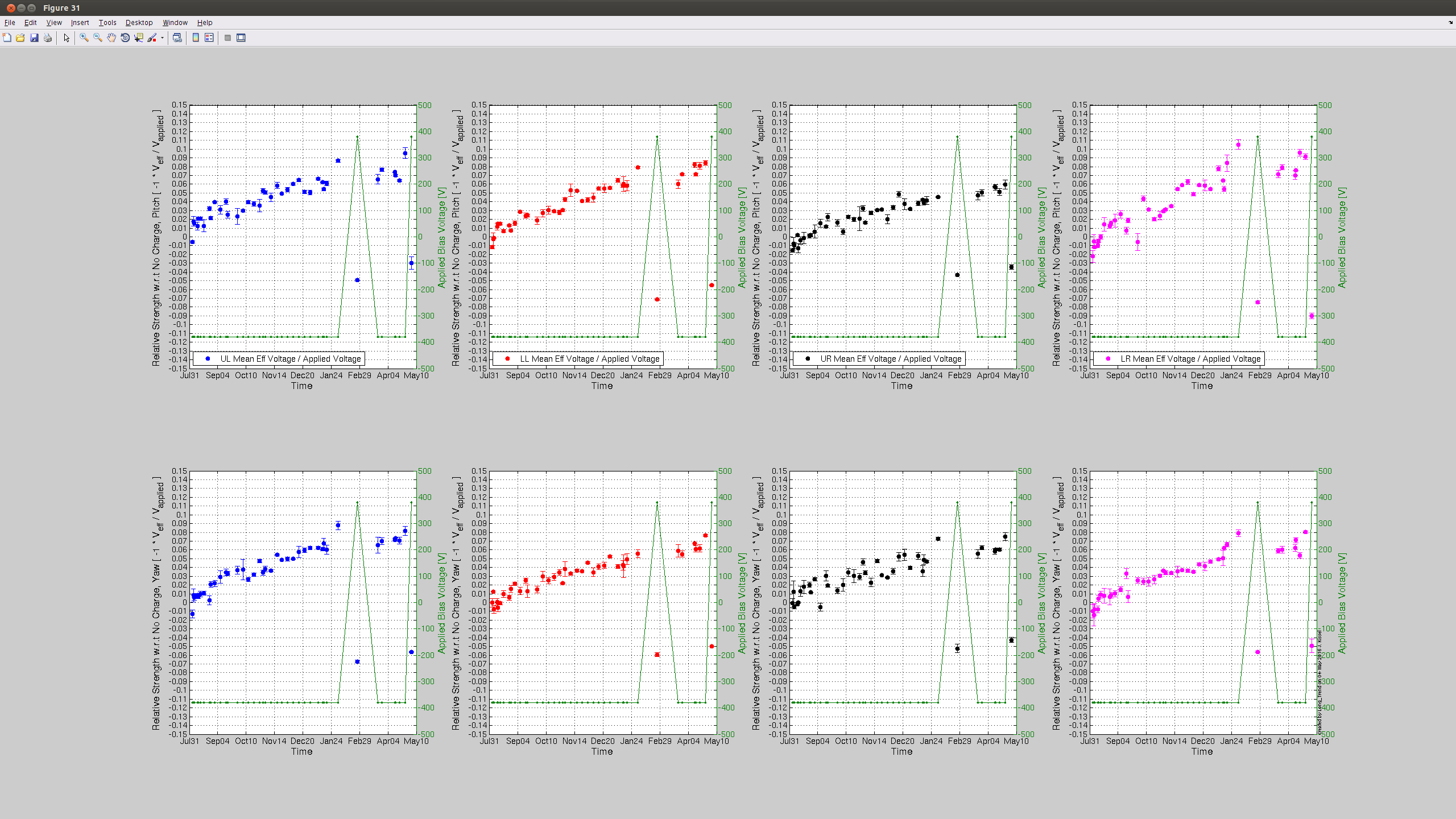
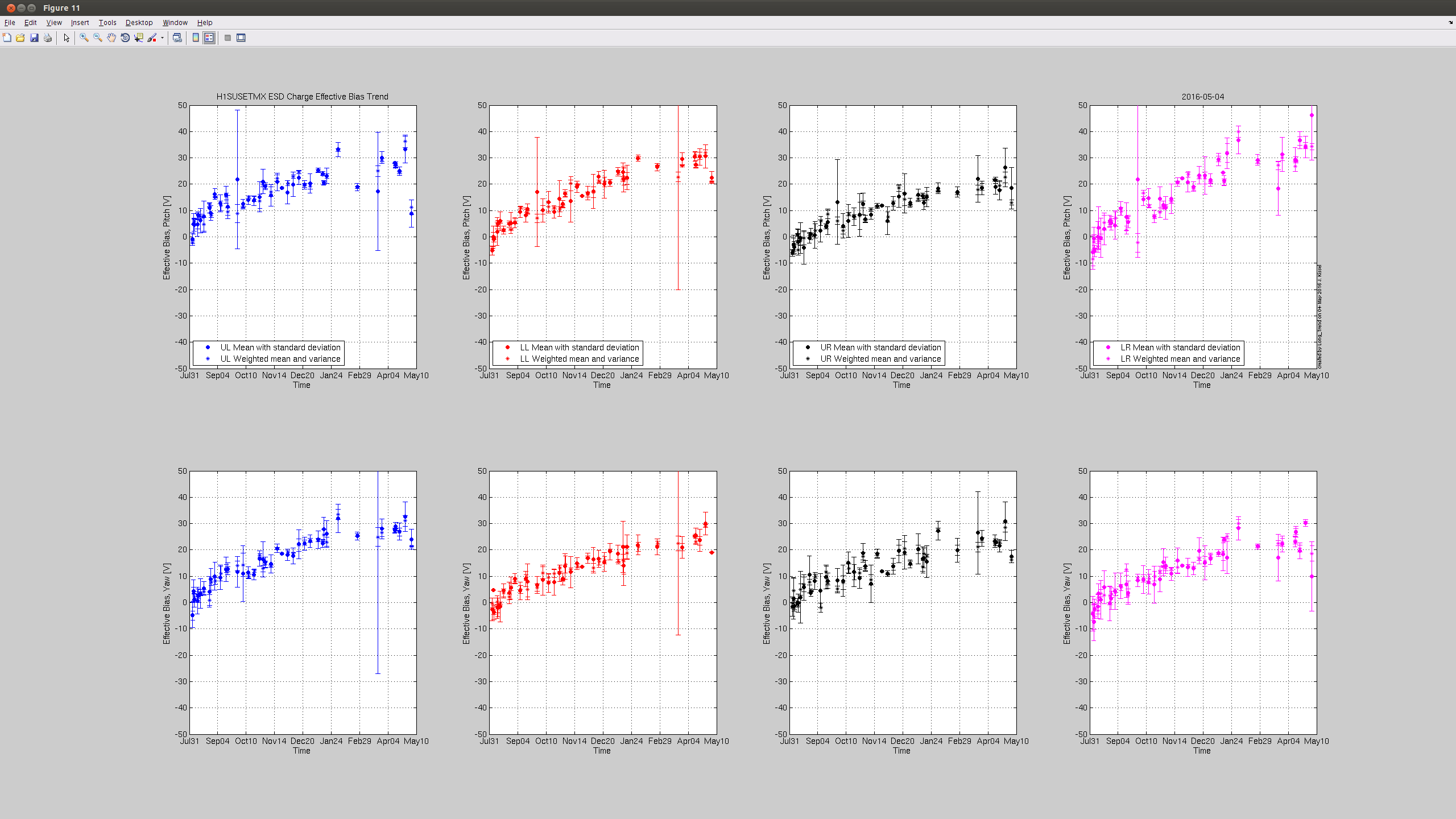
Summary:
Cable routing from ISCT1 to ISC field rack 2 (R2) didn't make sense with or without the flipped connector reported yesterday (alog 26970).
Routing was fixed, WFS was connected to the demod, and it seems like everything works as far as the electronics is concerned.
But we still have whitening BIO problem (alog 26307), so we can only use odd dB gains (3, 9, 15 etc.).
Next step would be setting up the optical path.
Cable routing error:
Before I started working, the cables between the ISCT1 and ISC R2 were routed as follows:
|
ISCT1 REFL B feedthrough |
cable label |
R2 position 11 top row
(REFLAIR B WFS 9MHz patch panel)
|
R2 position 9 top row
(REFLAIR B WFS 45MHz patch panel)
|
|
L1 |
14 |
CH1 |
|
|
L2 |
12 (or 21) |
CH2 |
|
|
L3 |
9 |
CH3 |
|
|
L4 |
26 |
test |
|
|
H1 |
6 |
|
CH2 |
|
H2 |
7 |
CH4 |
|
|
H3 |
3 |
|
CH3 |
|
H4 |
4 |
|
CH4 |
|
test |
5 |
|
CH1 |
"Test" input on the patch panel was routted to 9MHz CH4 output. Also 9MHz and 45MHz were mixed up. Don't ask me why.
Rerouting:
Hi- and low-frequency and test mixup was fixed at the ISCT1 feedthrough because it's easier than at the rack.
At the rack, high frequency patch panel (45MHz, R2 position 11) is at lower position than the low frequency patch panel (now 36MHz, R2 position 9), but our POPX patch panel and demod are at the bottom of the rack. Moving cables from high position to the bottom looked more cumbersome than from low position to the bottom.
For this reason, cables at the ISCT1 feedthrough were rearranged such that 45MHz cables go to higher patch panel and 36MHz cables to the lower one, and 36MHz cables at the rack were moved to the bottom patch panel. I also moved 36/45MHz test input cable from position 11 to the bottom because it was easy though I didn't have to.
Anyway, in the end this is what I ended up with:
|
ISCT1 "REFL B" feedthrough |
cable label |
R2 position 11 top row
(POPX WFS 45MHz patch panel)
|
R2 position 9 top row
(unused)
|
R2 position 2 top row
(POPX WFS 36MHz patch panel)
|
|
L1 |
5 |
|
|
CH1 |
|
L2 |
6 |
|
|
CH2 |
|
L3 |
3 |
|
|
CH3 |
|
L4 |
4 |
|
|
CH4 |
|
H1 |
14 |
CH1 |
|
|
|
H2 |
12 or 21 |
CH2 |
|
|
|
H3 |
9 |
CH3 |
|
|
|
H4 |
7 |
CH4 |
|
|
|
test |
26 |
|
|
test |
POPX 36MHz signals were connected to POPX WFS demod at position 3.
Signal check:
Used a flashlight and confirmed that all four quadrants respond in DC on MEDM.
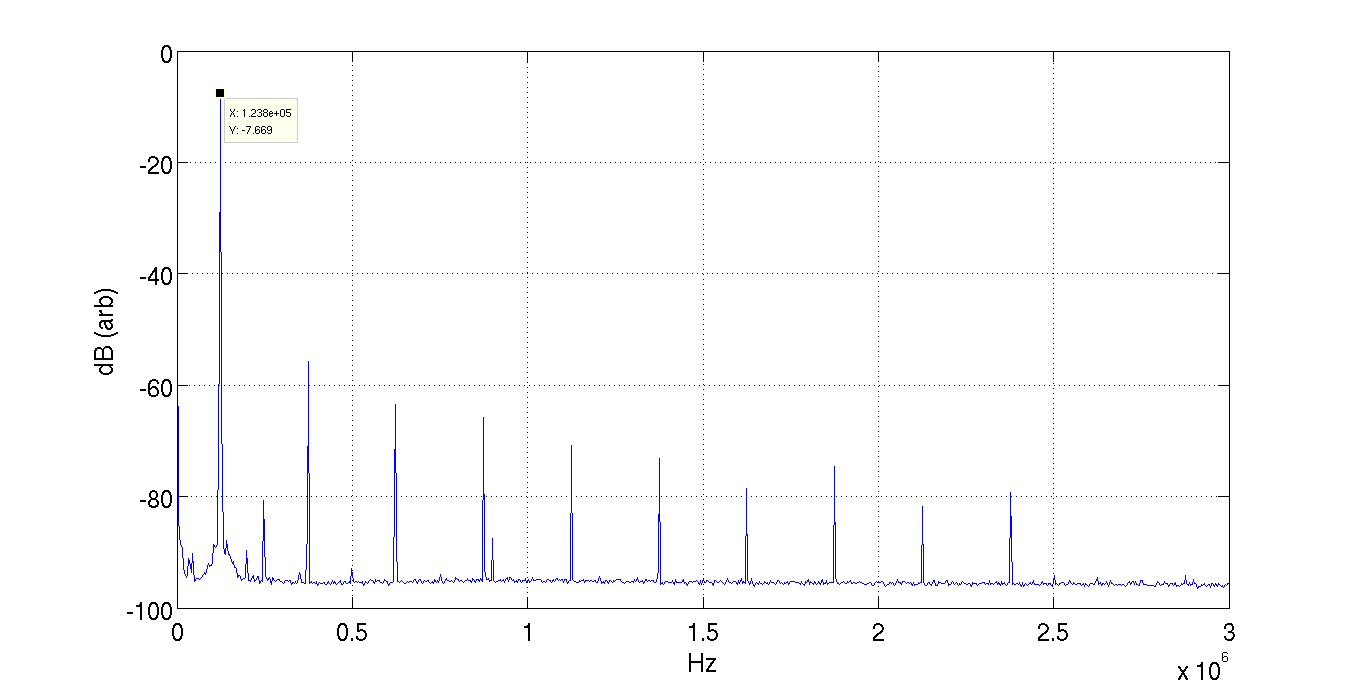
At the field rack, I injected a 36.4MHz-ish signal to test input, and confirmed that all eight demod outputs (H1:ASC-POPX_RF_I1 etc.) change by about the same amplitude and at the same frequency.
Measured the TF from the test input to the RF monitor output of the demod, and confirmed that the amplitude at 36.4MHz for all four quadrants agree within +- 0.02dB or so.
Notch frequency were 45.39, 45.56, 45.71 and 45.92MHz for quadrant 1, 2, 3 and 4 respectively.