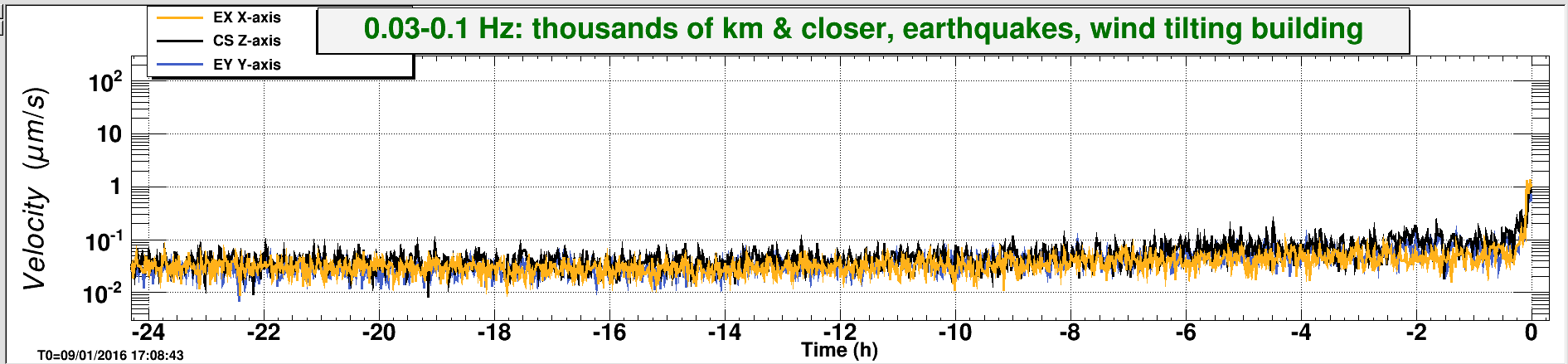
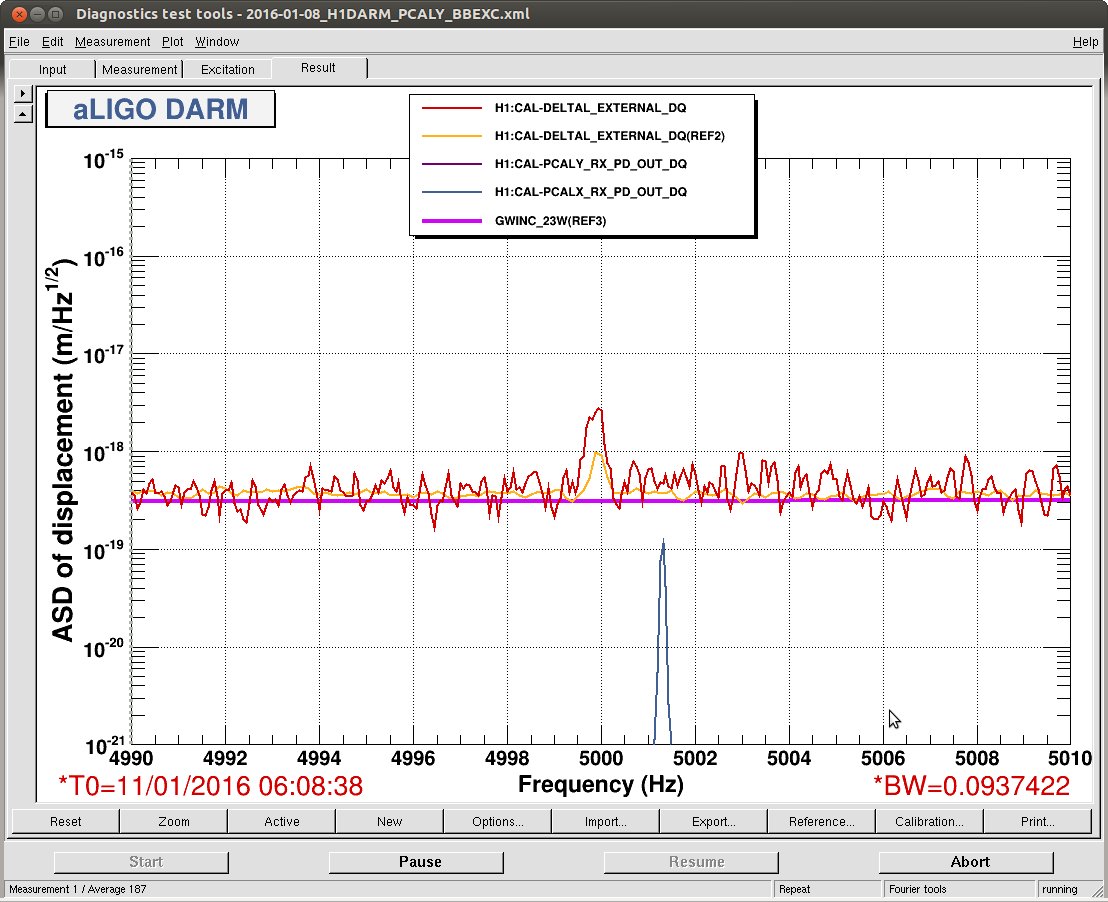
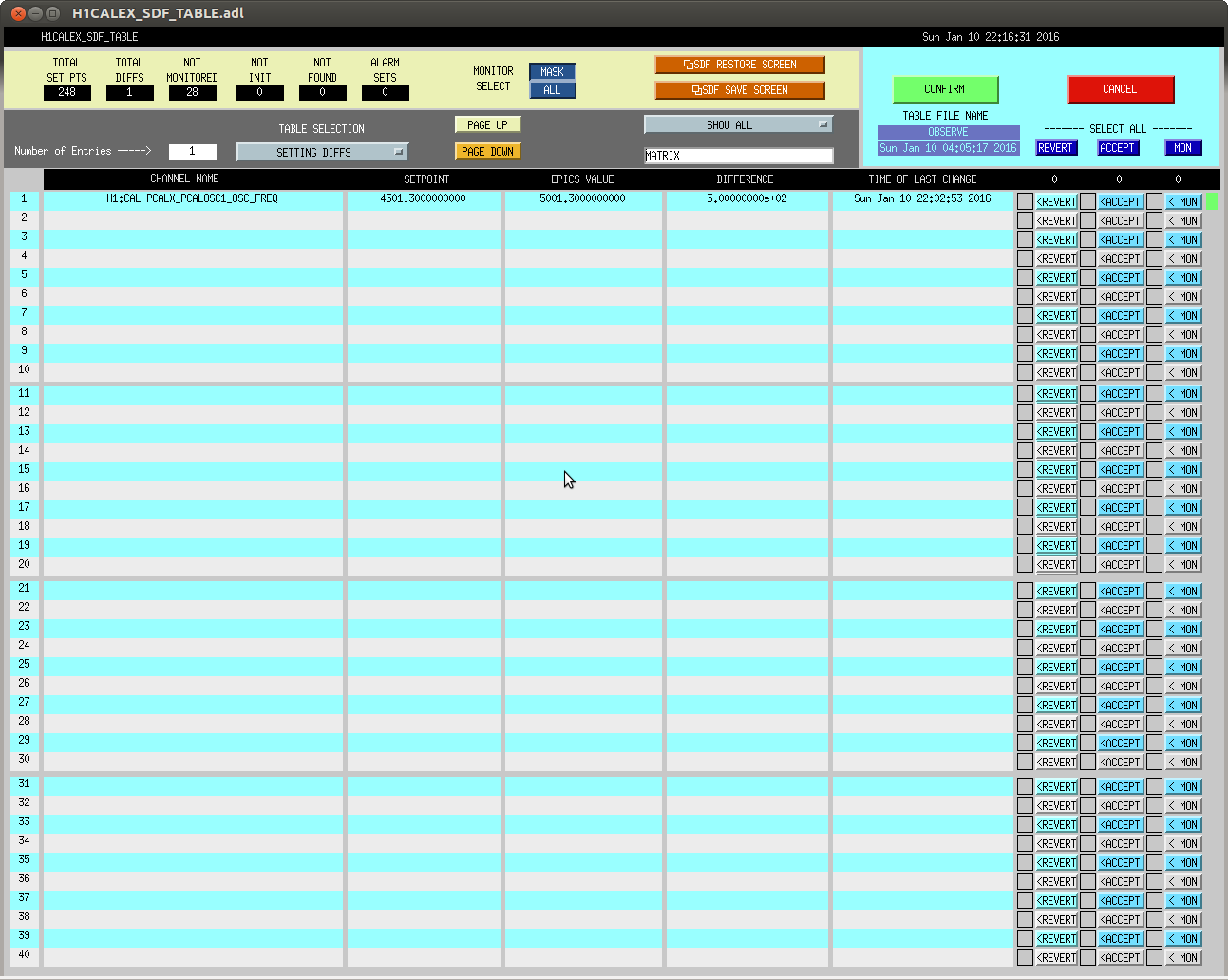
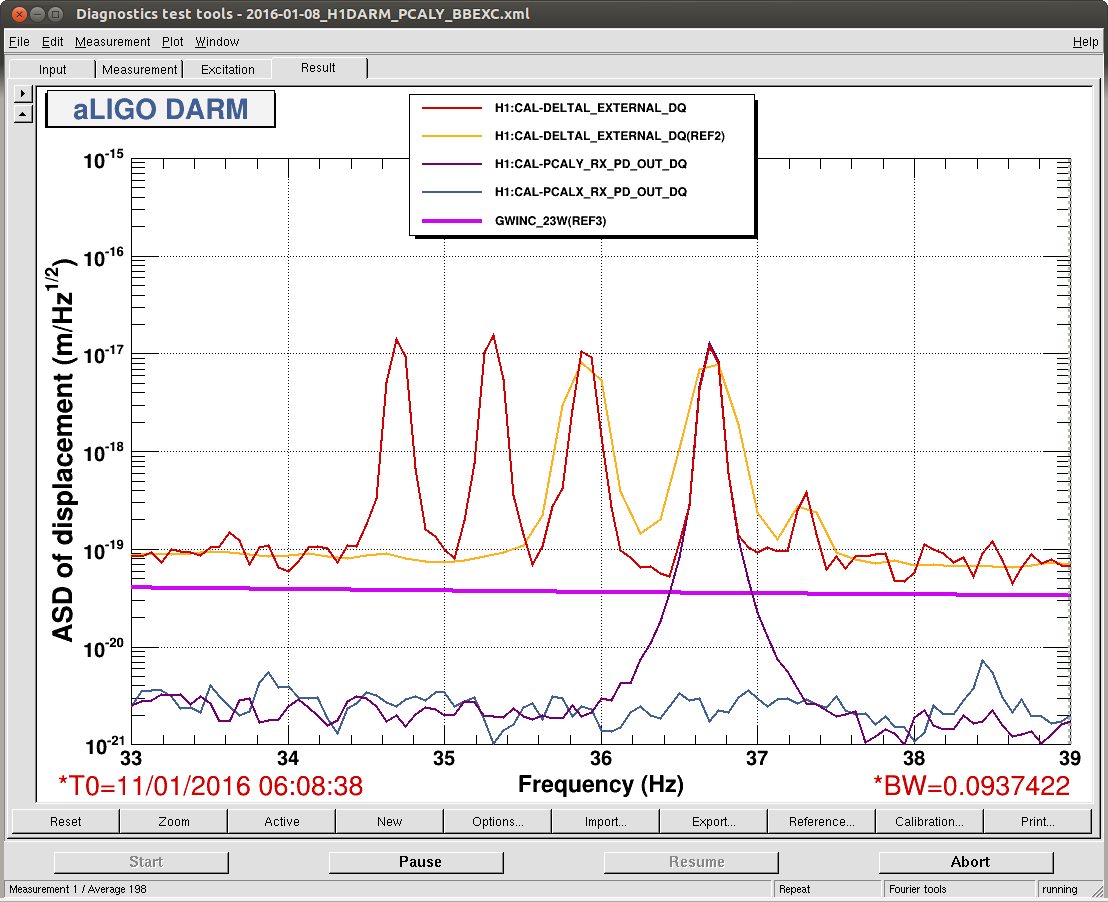
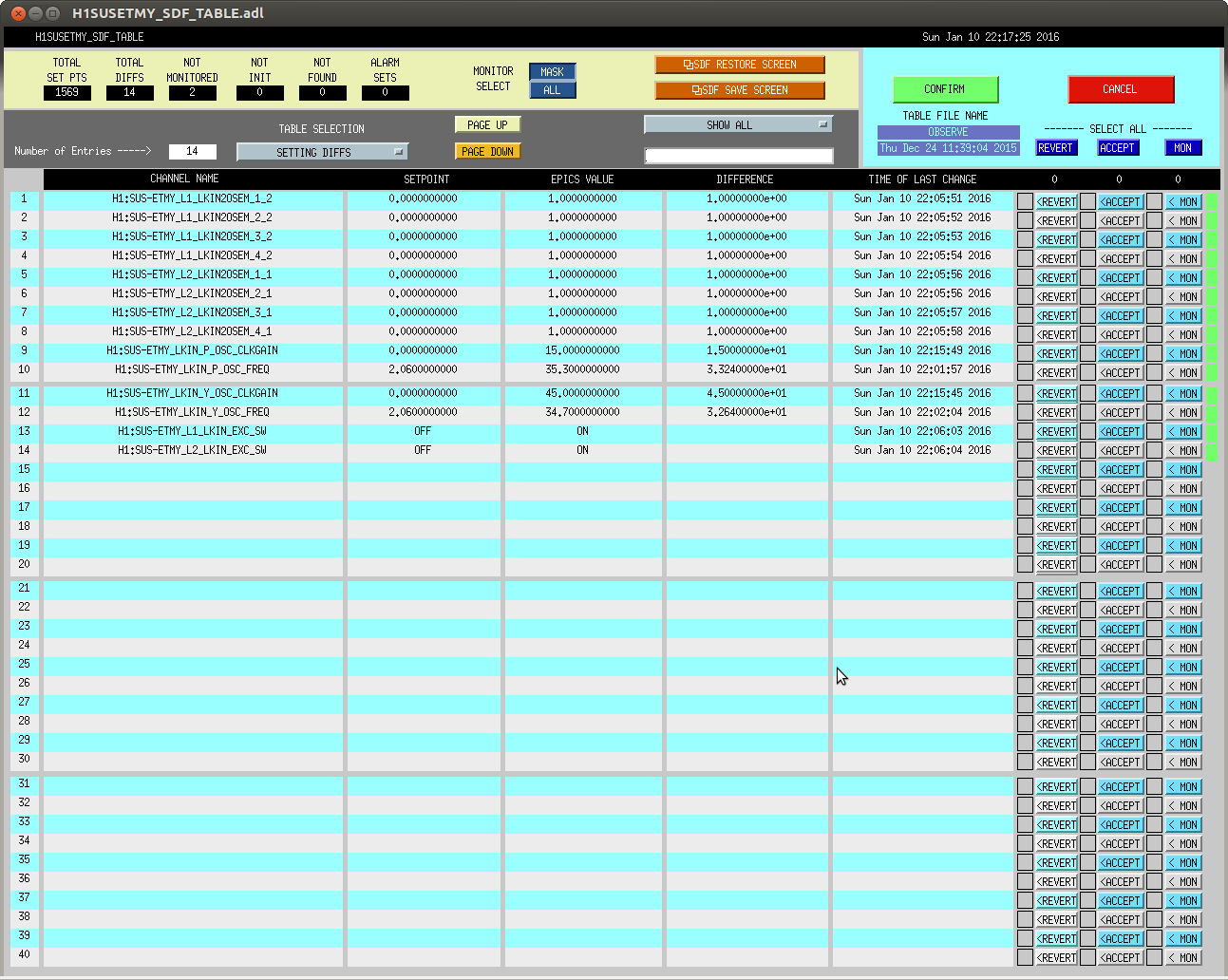
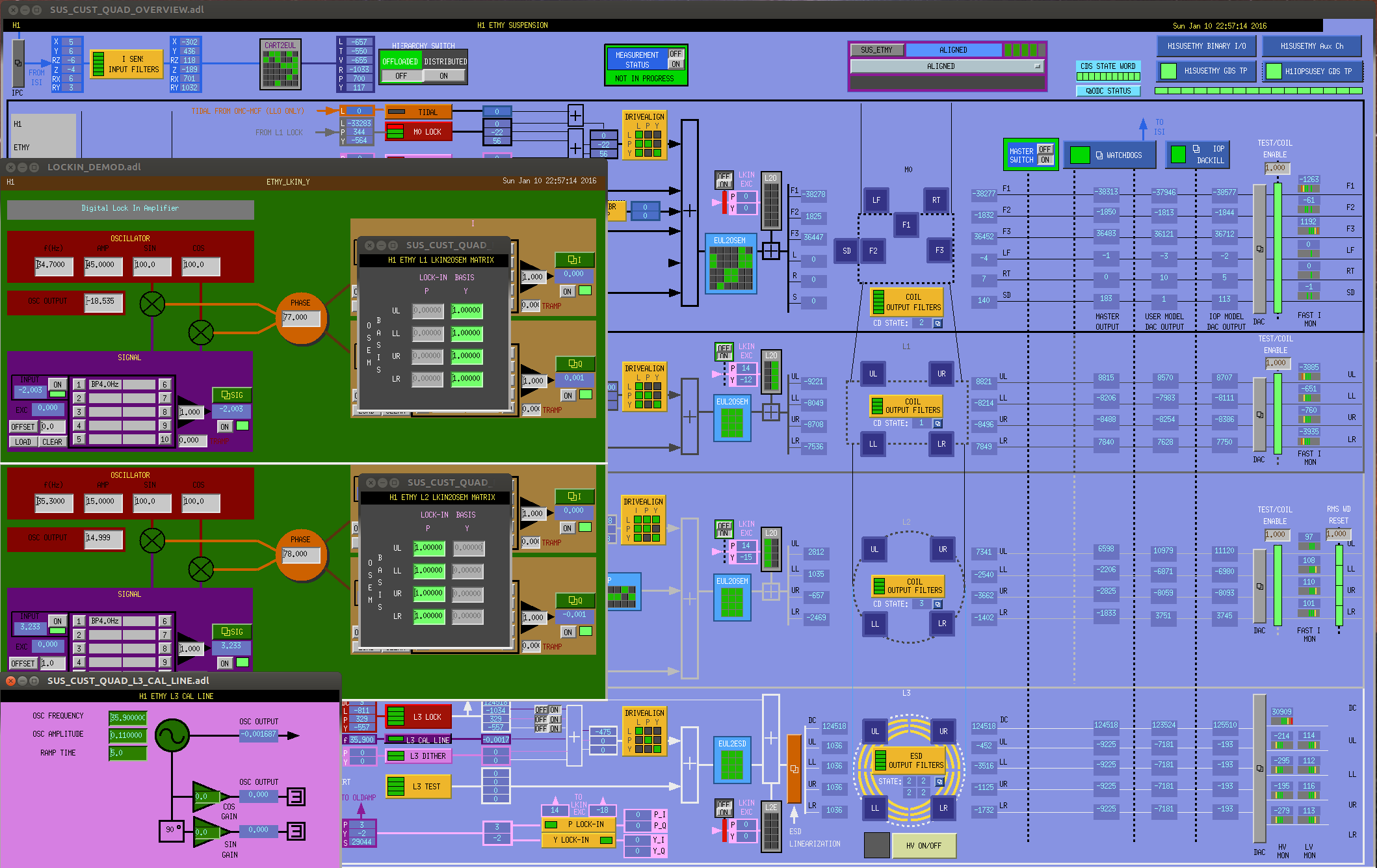
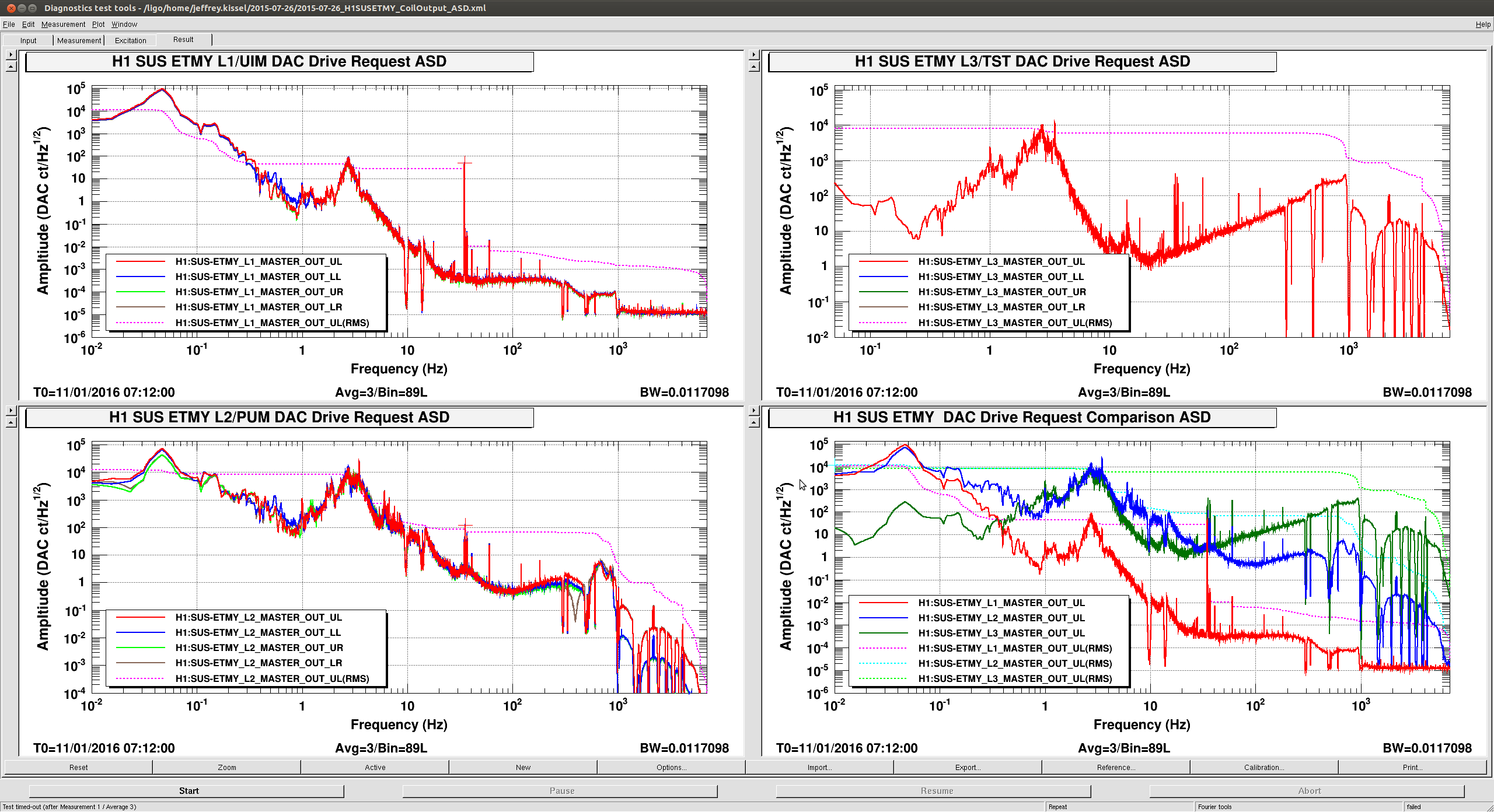
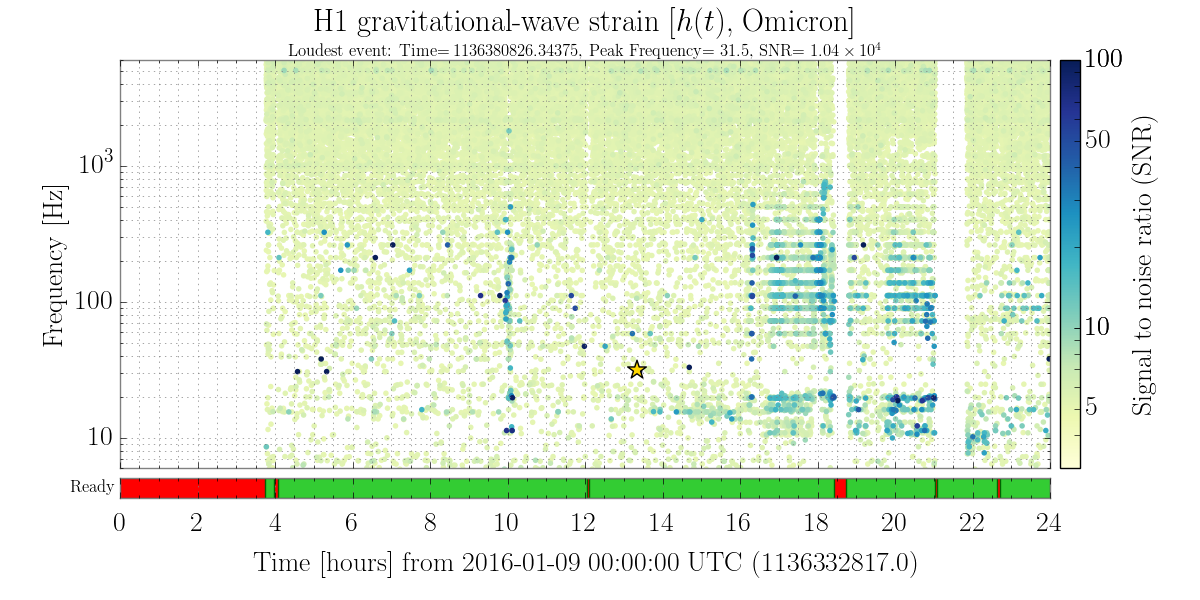
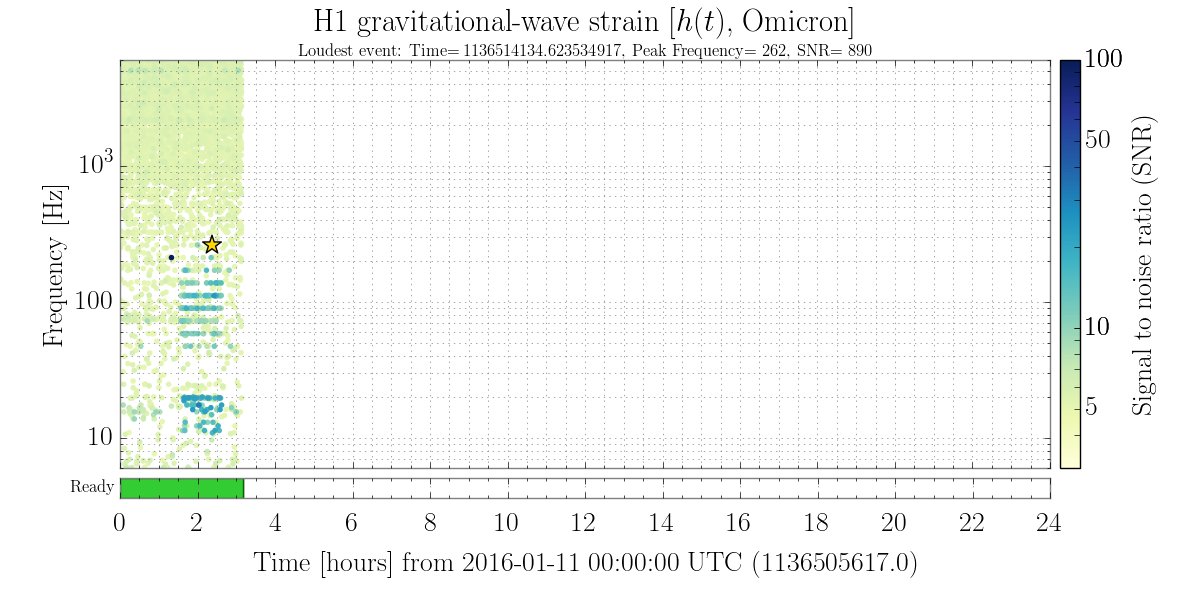
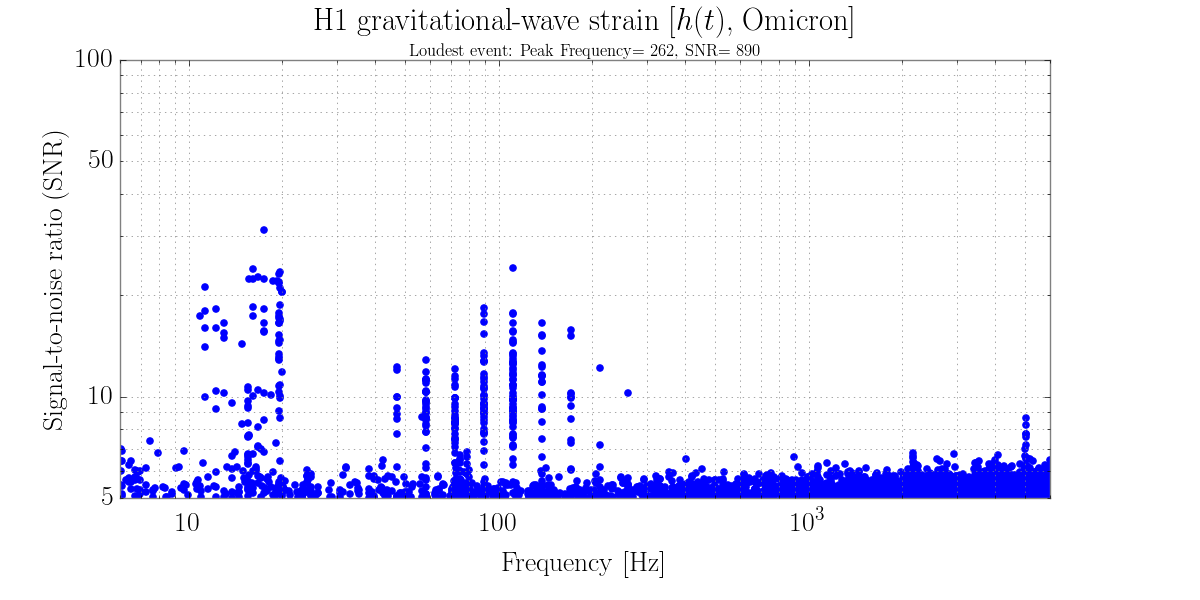
christopher.biwer@LIGO.ORG - posted 13:18, Monday 11 January 2016 - last comment - 16:51, Monday 11 January 2016(24867)
hardware injections test at H1 and L1
I will be conducting some hardware injection tests at H1 and L1. This aLog will be updated as hardware injections are scheduled.
Comments related to this report