TJ & Hugh
With IFO down from elevated winds, we attempted to have the Guardian switch the gains more like how the old SEI COMMANDS script switch the gains--WP5647.
Original svn update 24 Nov alog 23695--Change tested on HAM5 and worked.
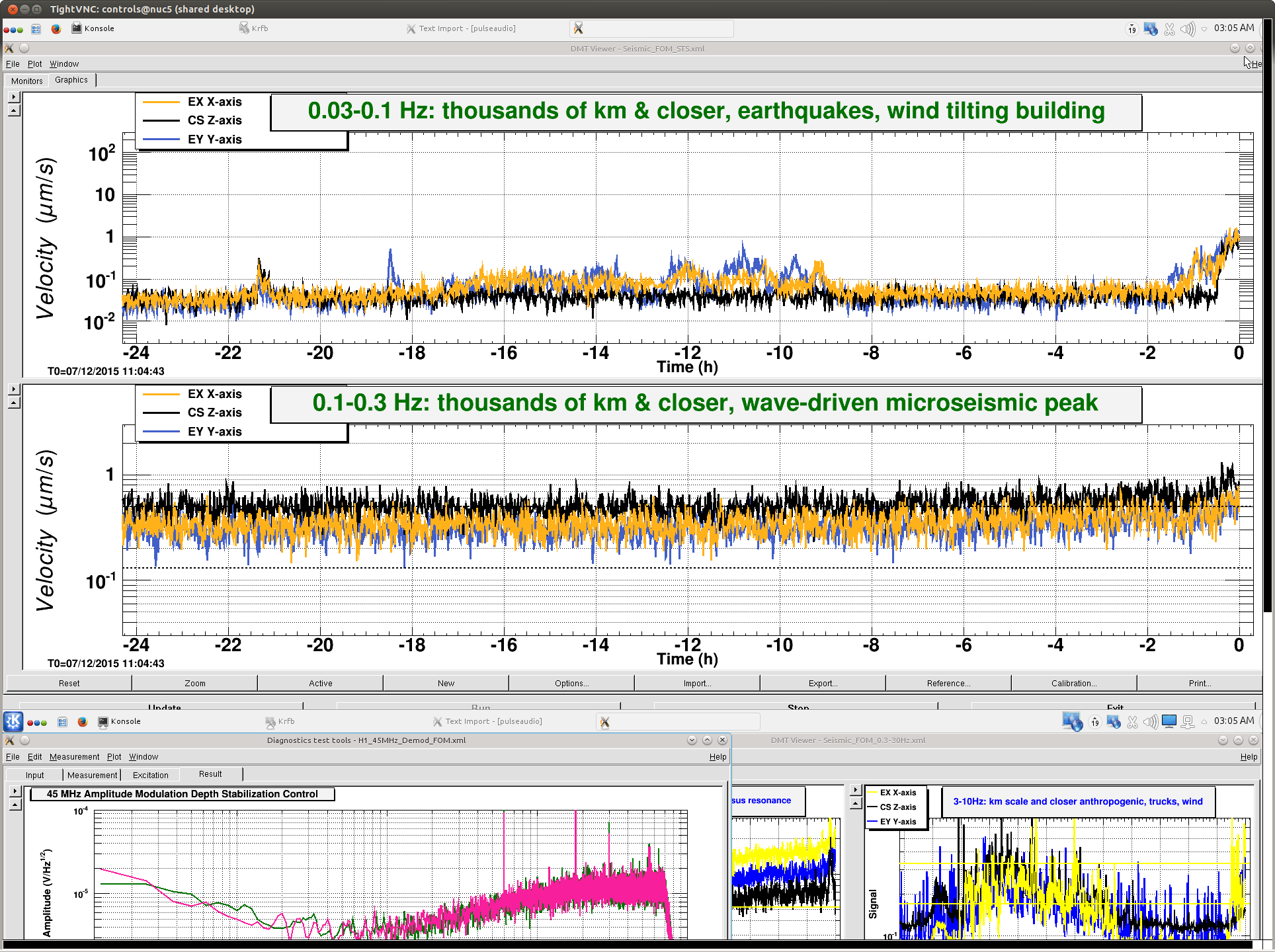
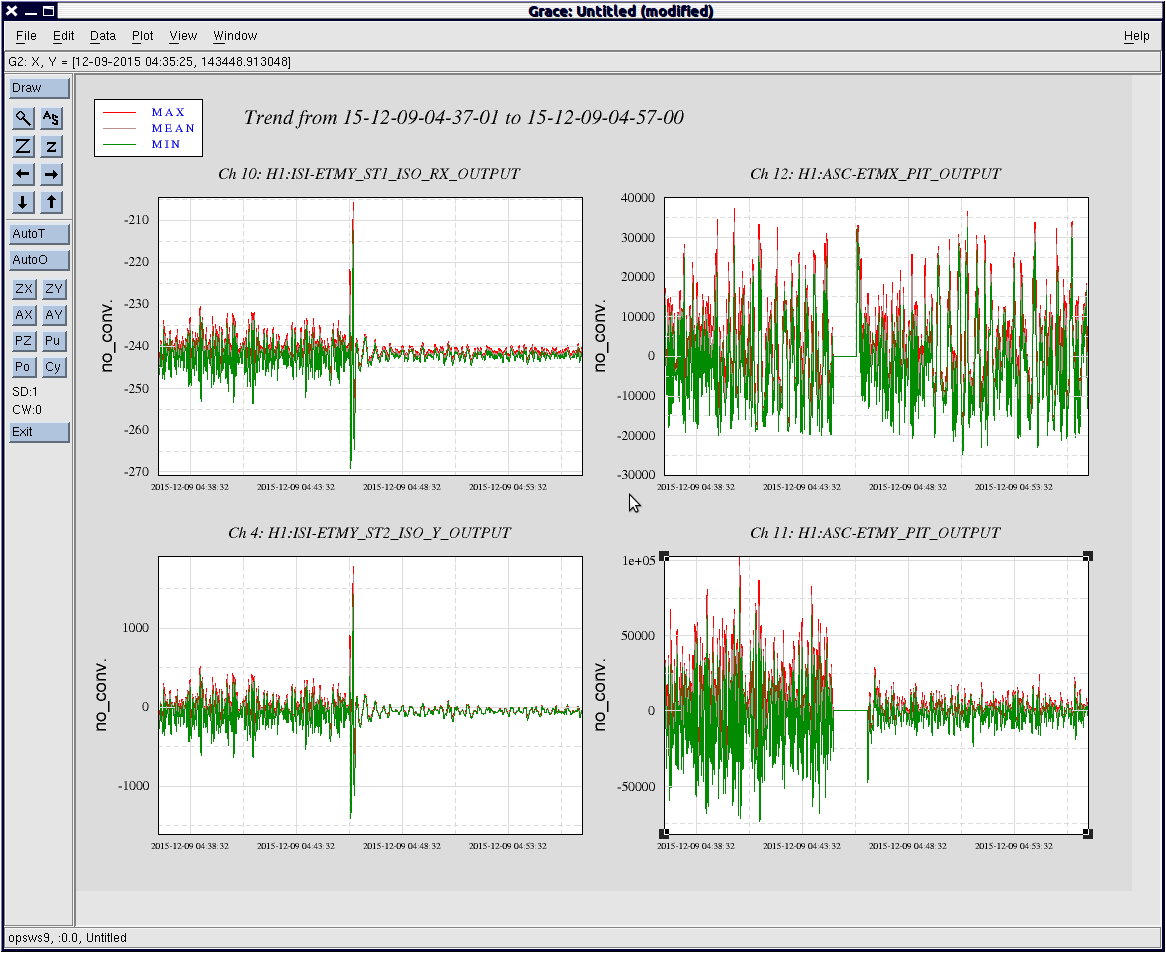
7 Dec, ISI trips with EQ reveal problem of this switching but only for HAMs 2 & 3, aLOG 24028.
In alog 24054 I report how the GS13 gain switch when done by the guardian well after the platform was isolated and quiet would still trip the HAM3 ISI. This led us to believe it was not the timing of the guardian GS13 switching--at the end of Isolation process after/while finishing the driving to the reference CPS location; but, that it was more related to how the guardian was doing the switching. The guardian switches both FM4 & 5 at the same time whereas the COMMAND script switches all the FM4 and then all the FM5s with a 1 sec sleep between.--See SEI Log 894 comment for code comparison.
Today,TJ modified the guardian code, see comment below, to try simulating the way the COMMAND script switches the Gain. Bottom line it still tripped.
We even tried reversing the order of the FM4 & 5, that is first FM5 then FM4 to turn off the analog whitening before we increased the analog gain, still tripped... So we still scratch our heads, it's winter, my skin is dry and it itches anyway.


Below is the code that we tried. I just added in a sleep for 1 second between the switching of the FM4 and FM5 banks in all dofs. When executed, it looked to have worked the same as the old perl script, but there must be some deeper magic that I need to look into.
(I switched this back to what it was before and committed it back in the svn).
Note to me: Had to restart the node in order for it to take any bits of new code. I've seen this before but I'm not sure what warrents a restart vs just a reload. I'm writing this here so I can look back and find the trend.