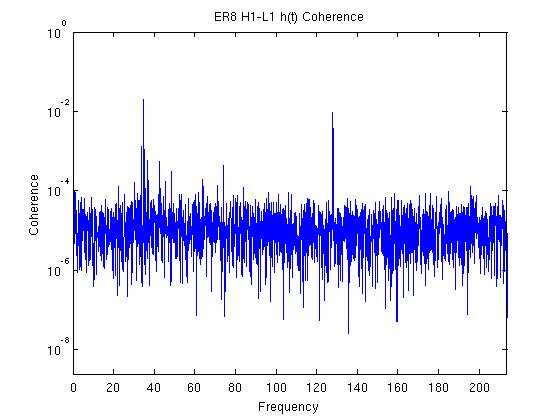
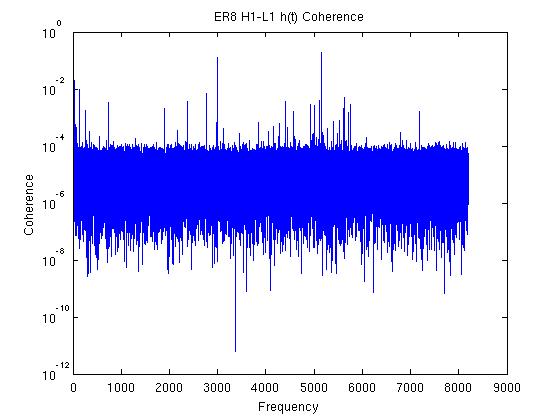
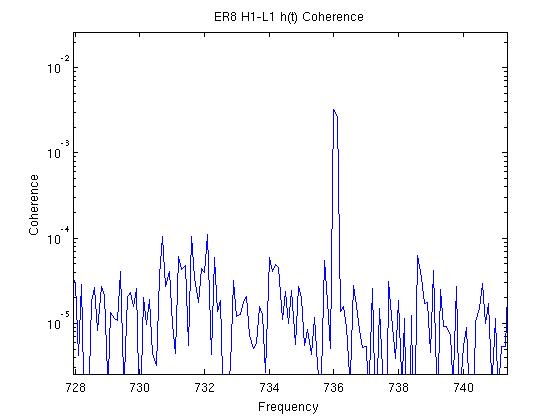
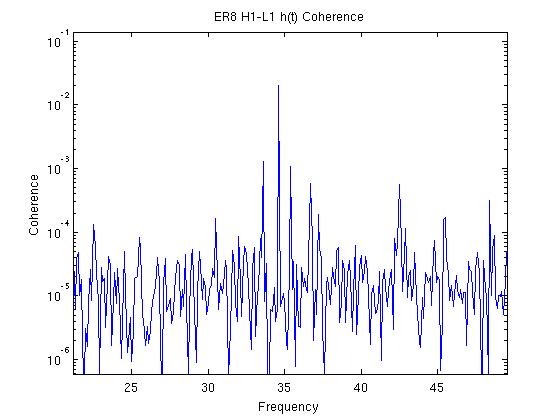
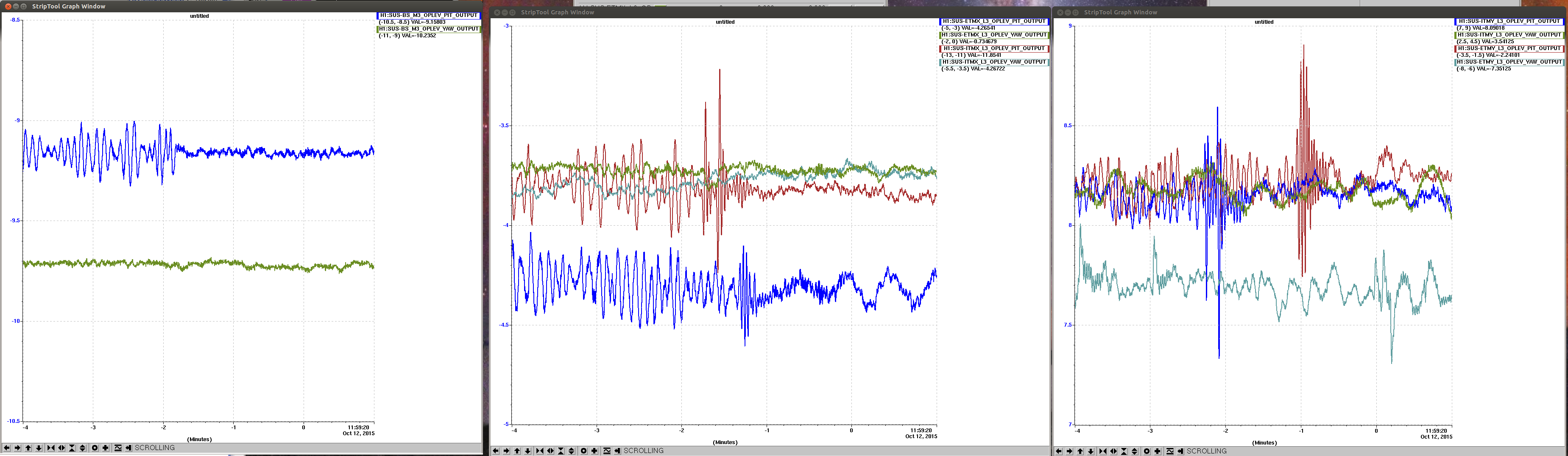
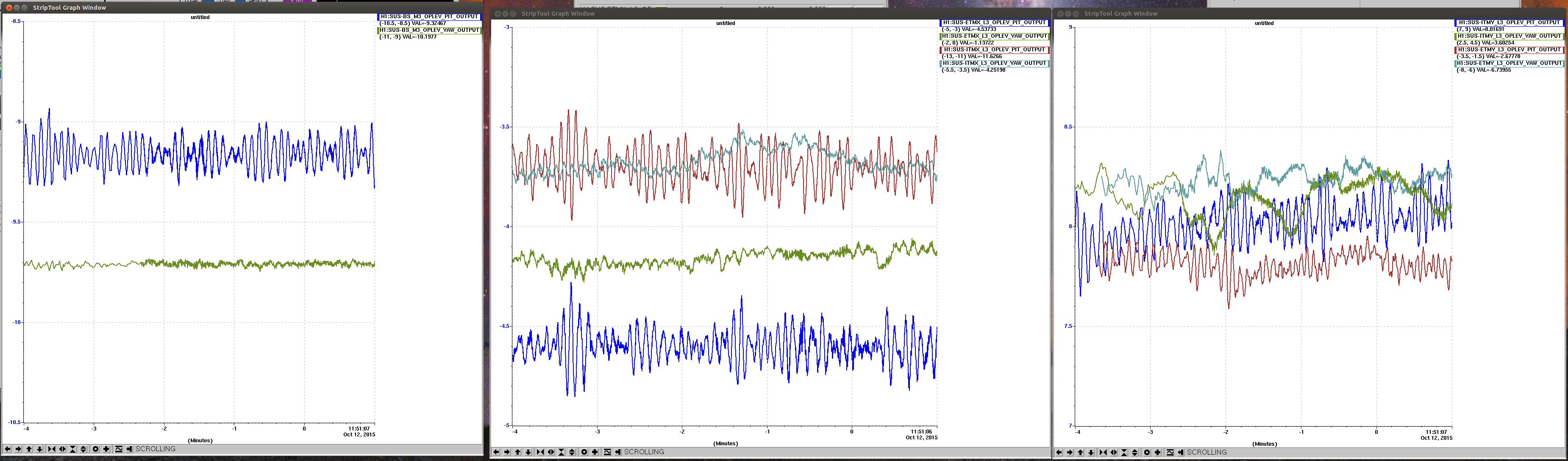
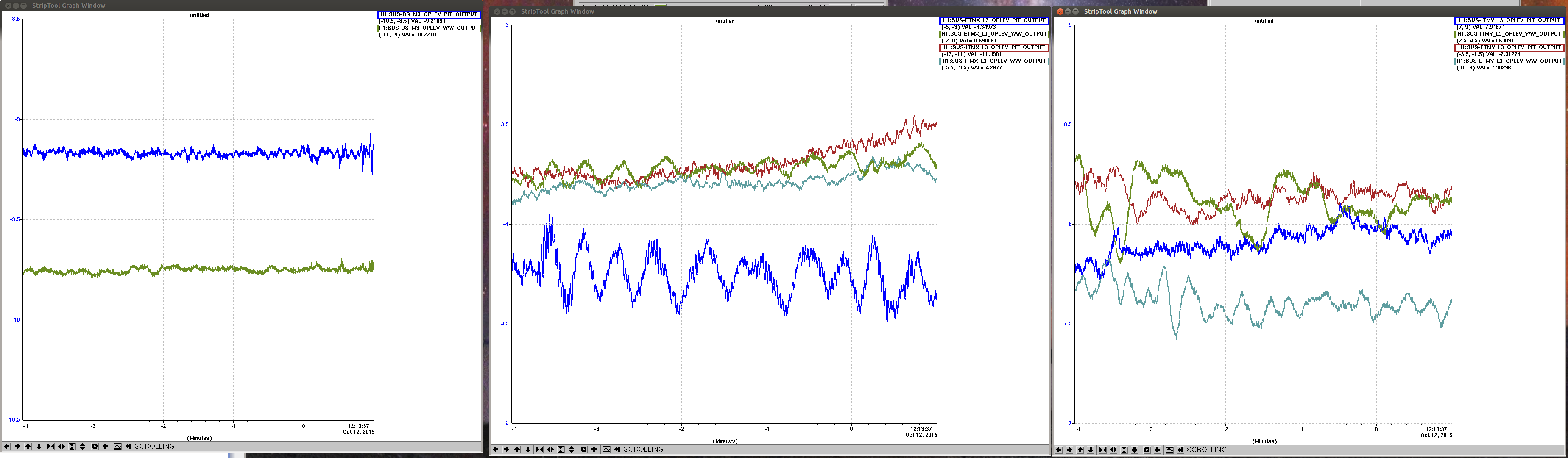
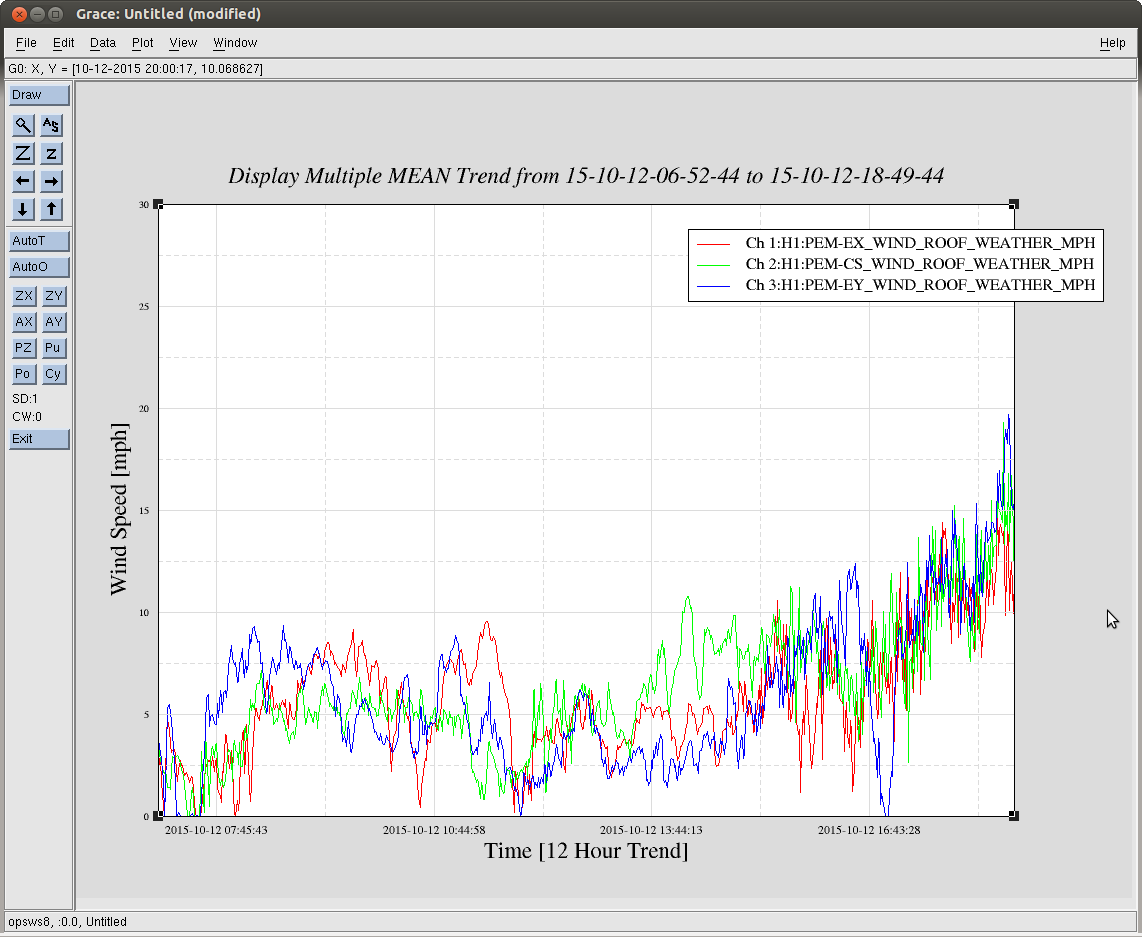
John, Gerardo
16:25 - Spun up LD, Turbo and QDP80
16:50 - LD was Calibrated with cal-leak, checked out.
16:55 - Valved in Turbo to vacuum volume, LD reported He background at 3.2 x 10-8 torr*L/sec, left system pumping.
17:08 - left Y-mid.
18:04 - Returned to Y-Mid to bag the butt welds of cylinder spool roll, 2 of them as half sections, for a total of 4 sections to test. Also continued to watch LD report..
19:20 - left Y-mid, LD reported background of 0.8 x 10-8 torr*L/sec.
20:25 - We returned to Y-Mid, LD reported a background of 5.3 x 10-9 torr*L/sec. Using a rate of 1 l/s of He, for 60 seconds dwell, leak hunting started:
* 3 butt welds of cylinder spool roll were tested, starting closer to the GV-11, no change on background for first 2 welds. Moved to the 3rd one, there was a signal, slow steady creep. Up until background reached 0.8 x 10-8 torr*L/sec.
* We paused for some time, gave the background a chance to drop with the VEA doors opened.
* We moved on to GV-11, since it is near to the butt welds, we checked its conflat and bellows with no change on background, other components had been checked before.
* Then some of the conflats on the spool piece by GV-10 were also tested, and again no change on the background.
* We moved to the turbo pump ports and turbo pump gate valve, they were tested with no change on the background.
* We returned to the butt weld, the 4th section (second butt weld) and tested it, we had a response and the background went up to 0.8 x 10-7 torr*L/sec, the signal was slow to creep up and it took sometime to show, thus creating a bit of confusion.
* We stopped leak testing because the background was too high, and it is going to take some time for the background to go down. We valved out the turbo pump from the vacuum volume.
We will continue with leak testing in the following days.
Note: While seen the background go up the turbo pump was isolated 3 times from the vacuum volume via its gate valve, and every time the background signal went down to <10-11 torr*L/sec