Ibrahim, Sheila, Ryan S
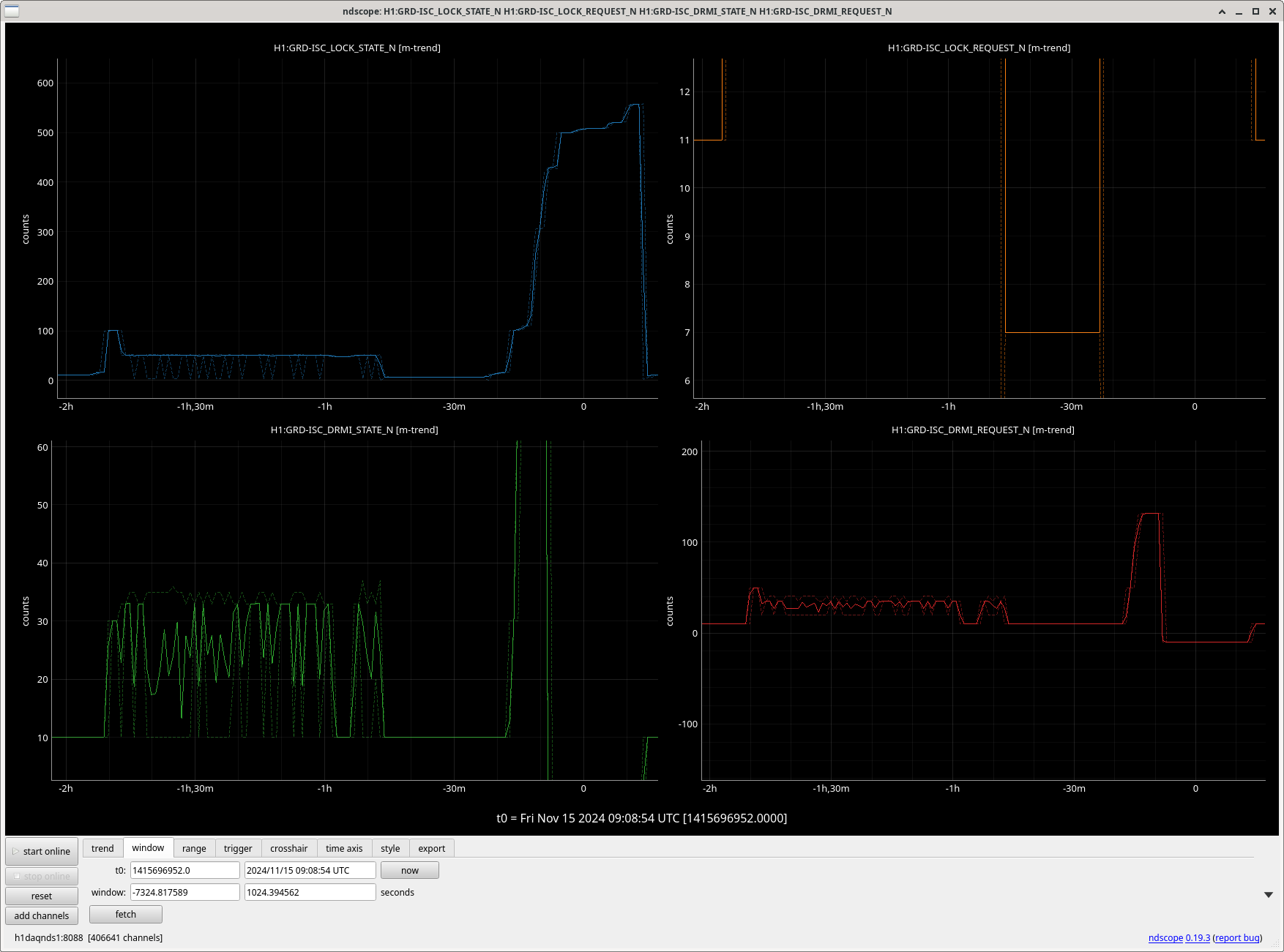
Ibrahim noticed that the guardian was in a loop of locking PRMI something like 20 times overnight.
What happened was that PRMI was poorly aligned (POP18 and 90 I ERR both below 20 counts), but PRMI was able to grab lock for a couple of seconds, but would not hold lock as the guardian engaged the top mass offloading, adjsuted gains and filters. Eventually this hit the timer in H1 manager to do an initial alignmemt, after just over an hour.
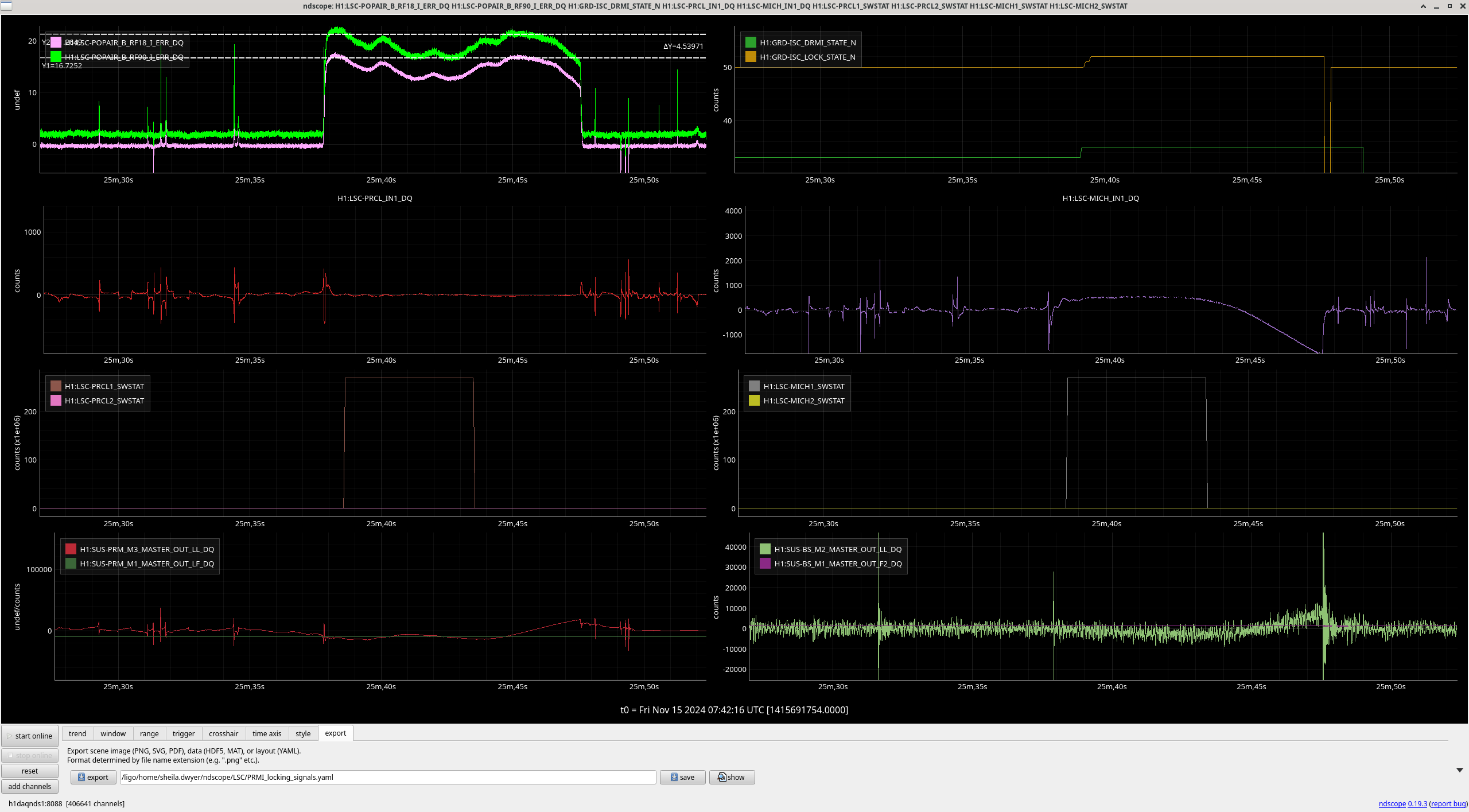
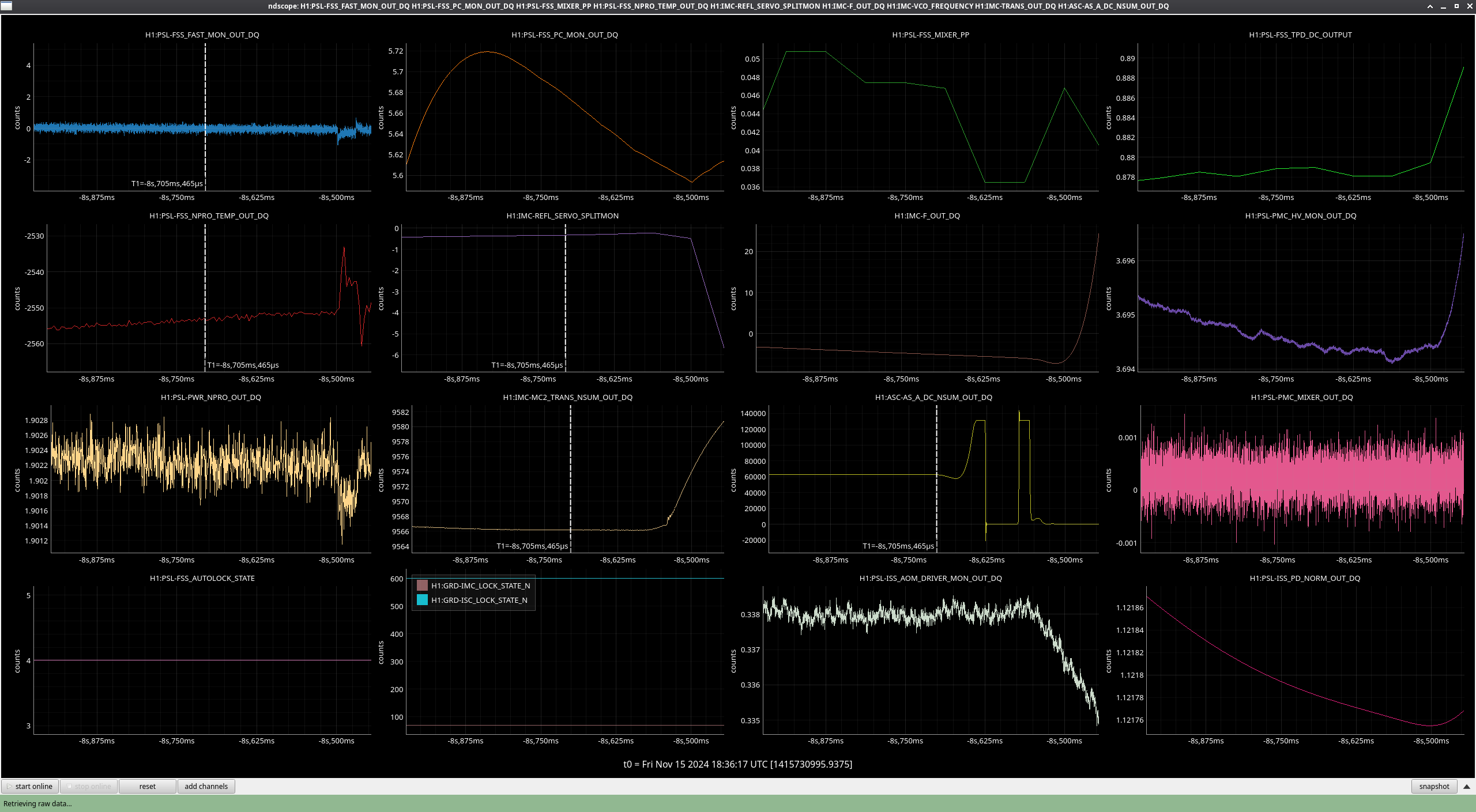
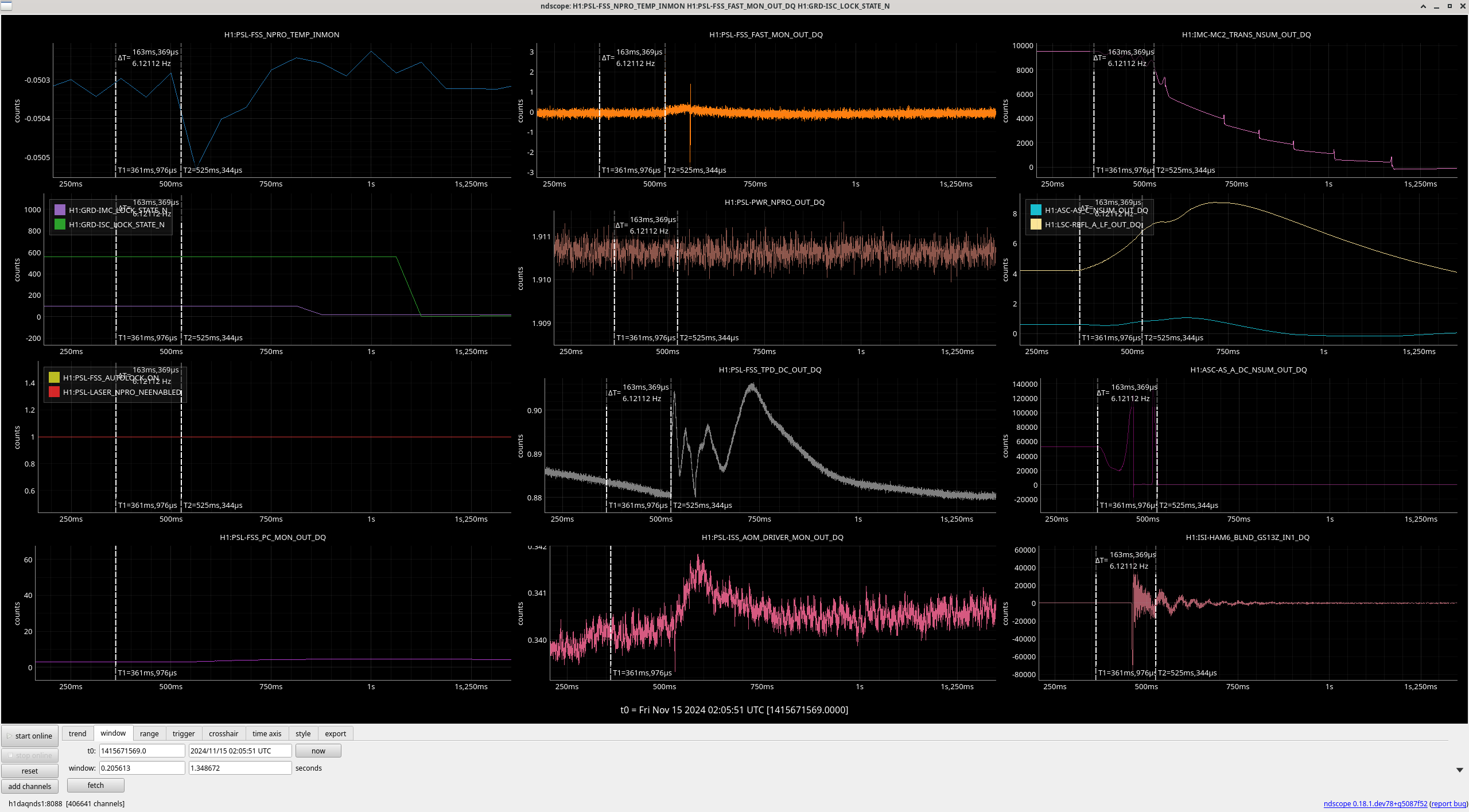
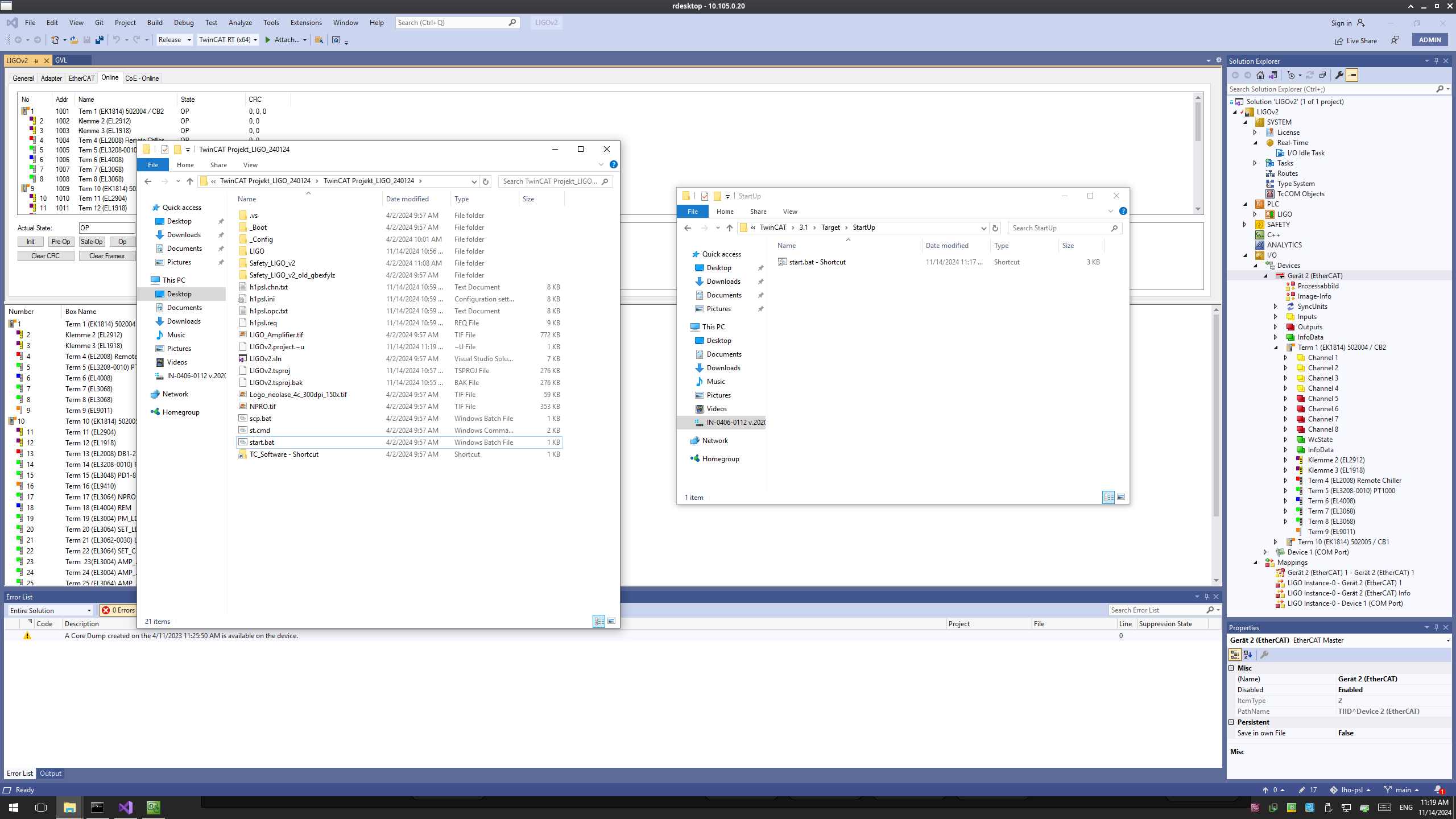
There is also a timer in ISC that checks if PRMI hasn't locked in 10 minutes it should move onto MICH fringes. This didn't happen in this case because of the very short locks. Ryan and I read through the ISC_LOCK AQUIRE_PRMI state, and realized that it had a check (line 1371) for DRMI arrived (in the state PRMI locked), which didn't include a check for the state being done, which would return true in ISC LOCK before ISC_DRMI finished the final steps in PRMI locked . In the second, zoomed screenshot, you can see that as soon as the DRMI guardian enters state 35 (PRMI locked), ISC lock moves on immediately from state 50 (ACQUIRE PRMI) to 51 and 52 (PRMI ASC), which resets the timer so that we never went to MICH fringes.
We added a check for the ISC_DRMI state to be both arrived and done in PRMI locked, so that PRMI will have to survive the offloading and boost engagement for the timer to be reset. Ibrahim has now reloaded this. We think that if this situation came up again, now we would only spend 10 minutes relocking PRMI, before going to MICH fringes. If H1 is under the manager control, it would run initial alignment if running MICH fringes didn't help.