Hi everyone it's been a while since I posted!
Julia Rice and I had a chat with Peter F today about motivating the electrostatic violin mode damper we've been building at Syracuse. We came away with a couple of questions to answer:
1. What's the actual displacement of the fibers when the violin modes are excited, and is our shadow sensor noise low enough to measure the modes.
2. What is the origin of the two violin modes per fiber? Is it fiber ellipticity built into the fibers themselves or asymmetry their attachment points AKA the ear/horn. If it's the former, we'd expect the main oscillation axis of the modes to be randomly oriented. If it's the latter we'd expect 4 modes per test mass to be dominant in DARM, and 4 modes to be much weaker, we'd also perhaps expect to see a regular spacing between pairs of modes.
I still have remote access (thanks Dave for helping me get my ports sorted with NoMachine), so I logged in to grab some plots of violin modes excited vs damped times.
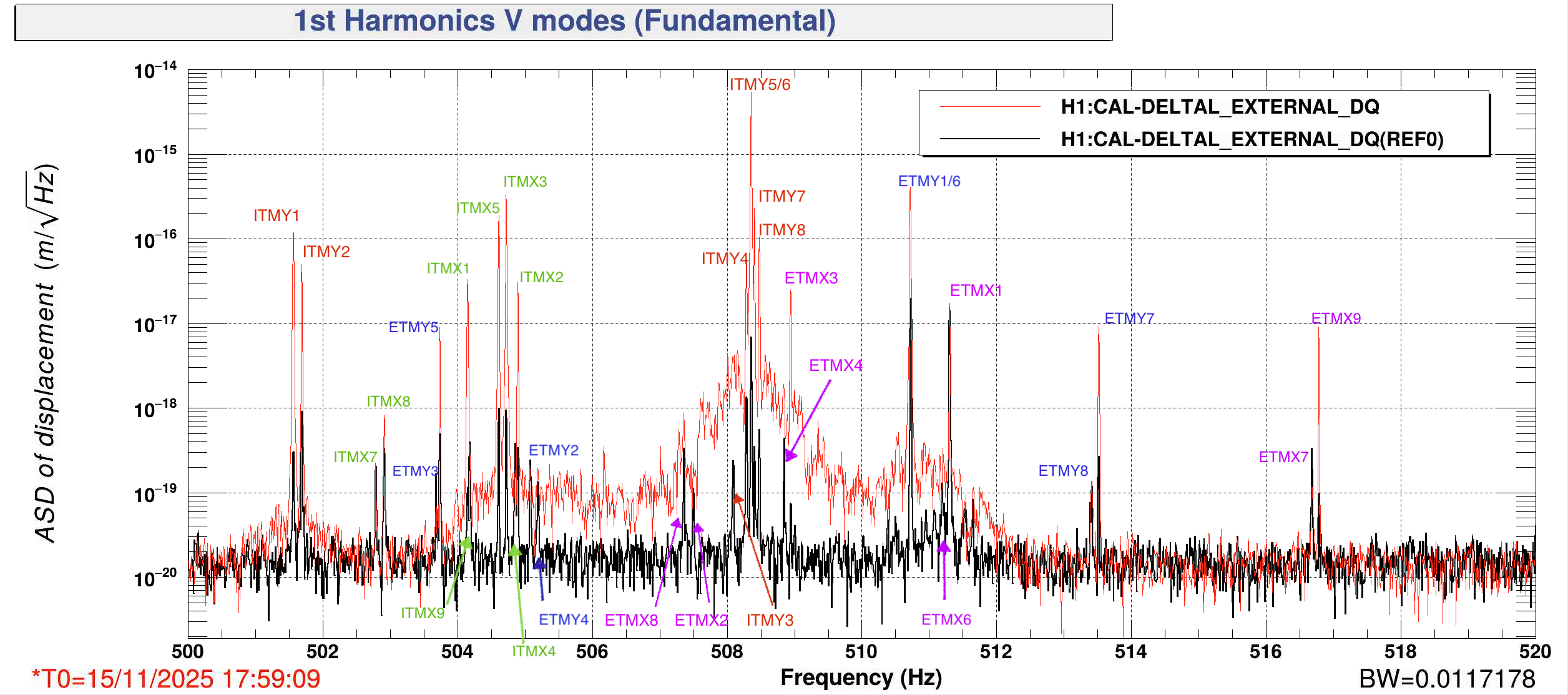
I found an excited time and a quiet time by plotting the ISC_LOCK guardian state and the monitor for ITMY MODE5 which I know is a problematic mode (first plot). I used 5 November 2025 17:59:09 UTC, gps 1447264767 for the modes excited time since this was after many locking attempts with the mode5 monitor was ~20k counts. I used 17 November 2025 20:57:12 UTC, GPS 1447448250 as my quiet time AKA t=0 on the first plot.
Second plot is the money plot! When the modes are excited their amplitudes in DARM range between 1e-16m/rt(Hz) and 1e-14m/rt(Hz), we can roughly convert this to fiber displacement by multiplying by the fiber to test mass mass ratio. We did some back of the envelope calculations with Stefan and there's a factor of 2pi in there somewhere too.
I labelled the plot referencing this handy violin mode spreadsheet from Rahul et al, which set me thinking about the violin mode origin in question 2 above...
I can see the regular spacing with one large mode and one smaller mode in the ETMs for the excited spectrum. BUT it's not like there is 4 modes visible in DARM and 4 that are totally anti-aligned: the smaller modes are still very much visible in the DARM spectrum.
ETMX9 (516.781 Hz) has a small buddy ETMX7 (516.678)
ETMX1 (511.2993 Hz) had a small buddy ETMX6 (511.18)
ETMX3 (508.938 Hz) has a small buddy ETMX4 (508.844)
ETMX8 (507.36) has a small buddy ETMX2 (507.493)
For the first 3 pairs, the bigmode is higher in frequency, not sure if significant. Also, in the damped spectrum the larger modes can become sufficiently damped that the smaller mode is now louder in DARM, I wonder if that might be because we have spent many more hours tuning and damping the settings for the large modes?
There are also some modes that break the trend: ETMY1 and ETMY6 are very close together.
For the ITMs, things are less clear. ITMY1 and ITMY2 are similar height in DARM, same with ITMX8 and ITMX7, and ITMX3 and ITMX5. Things are confusing around the clusters of modes 504 Hz and 508 Hz.
I had previously always assumed that ITMY mode5 and mode6, the extremely close modes, are on the same fiber. But perhaps mode5 is on the same fiber as mode7, and mode6 is on the same fiber as mode8!
To better visualise the data, I made a table of the mode "buddies" and their frequency separations here, check it out if your interested. There is a goofy plot in there with no x-axis and mode spacing on the y-axis. The frequency spacing of pairs of modes is centered around 0.1Hz.
I do think there is scientific value to having a shadow sensor at the fiber: it's clear that the modes are not perfectly aligned or anti-aligned with the DARM axis, I was able to identify all 32 modes. In the egregious case of ITMY, at least 7 of the 8 modes are large in DARM. That being said, the regularity of the spacing means I am quite confident (for most modes!) which two modes are on the same fiber.
Please let me know if I've missed something or if you have any thoughts!

Please quote all numbers for fiber motion and put all plots in 'meters' (either rms or pk), not meters/sqrt(Hz). It is the former that has physical meaning, can be compared to calculation, and is not dependent on the resolution bandwidth one might choose for a spectrum.
Good point and important for when we are calibrating our sensitivity to fiber displacement. Here's the main plot converted to meters RMS!

@Georgia, welcome to the violin mode life cycle! I hope you're using Alan Cummings as a resource. He was super helpful in understanding the mode splitting back in 2022: TL;DR -- the answer to your second question ("2. What is the origin of the two violin modes per fiber?") is known: dictated be asymmetries, offsets and angles in the fibre necks, ends and welds; not any ellipticity. Full conversation: Kissel [...] Can you model the driven transfer function coupling between PUM drive and the violin mode? We've recently taken two data sets that either don't make sense, or are incoherent, see - Swept Sine LHO:63083 - Broad Band LHO:63089 > and we're left wondering if it even makes sense to expect to see something on resonance. This would likely require not only your exquisite FEA that includes fiber profiling and pictures of the welds, but also understanding exactly where the PUM magnets are, and the bending bodes of the PUM. Let us know if you need any help in gathering enough information to support such detail, or if you think you've got enough already. Cumming This may well be possible with the FEA, although it's not something I've personally ever done. However, it probably warrants a little caution as to any manage any expectation of what might be possible with FEA (as does all the high precision v-mode stuff) - the precise coupling of a v-mode will likely be very dependent on the direction of oscillation, and this will most likely be dictated be asymmetries, offsets and angles in the fibre necks, ends and welds [what it's not is: general fibre ellipticity - proven previously with FEA that this would have to be so large that we'd see it in profiler measurements]. All of that isn't perfectly characterised, and also can't easily/at all be modeled in FEA, which is where we start to become limited. Also there is the fibre tensions - these are all assumed to be the same in the FEA, which in reality may not be the case. Indeed in LHO:57649 the comparison of ITMY's fibres measured fundamentals with FEA implies that there's a possibility fibre S1800746 may well be under more tension than the others as compared the projected FEA trends. That's not totally definitive as the reason, but it's certainly possible. I suspect again these are things that might start affecting the coupling at the levels of precision you are interested in. Practical point - currently the FEA models that exist for the S18XXXX era fibred ITMY are single fibre stiffness models to compare base frequencies of the v-modes that come from the differing fibre geometries. We don't yet have a 4 fibre ITMY model with the individual fibres [at that time you guys were still trying to choose the tranche of good-guy 'a-list' fibres, so it was not known which individual suspects would actually be used in ITMY. Looking at the alog links, it's clear you did ultimately install the a-list fibres S1800721 ,S1800751, S1800649, S1800746.]


































{kind=link}
{kind=link}