TITLE: 10/13 Eve Shift: 2330-0500 UTC (1630-2200 PST), all times posted in UTC
STATE of H1: Lock Acquisition
INCOMING OPERATOR: Oli
SHIFT SUMMARY: Only about an hour of observing time this shift thanks to very high microsiesm and several earthquakes this evening. Fortunately, locking has been mostly automatic despite the frequent locklosses. Violin modes have been elevated due to these locklosses as well.
LOG:
- 23:30 - H1 relocking at DRMI
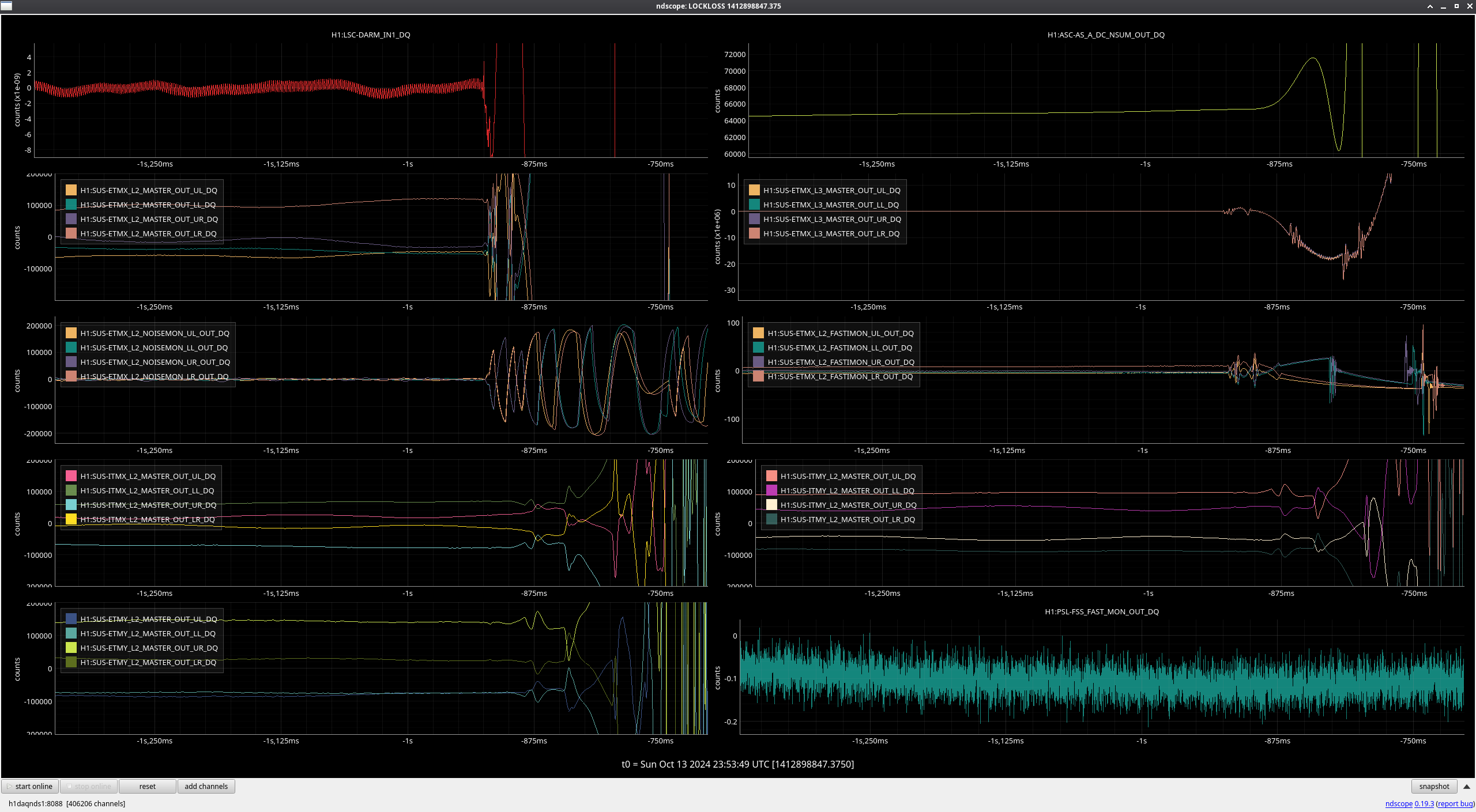
- 23:58 - Lockloss in TRANSITION_FROM_ETMX
- 01:04 - Reached OMC_WHITENING; holding to damp violins
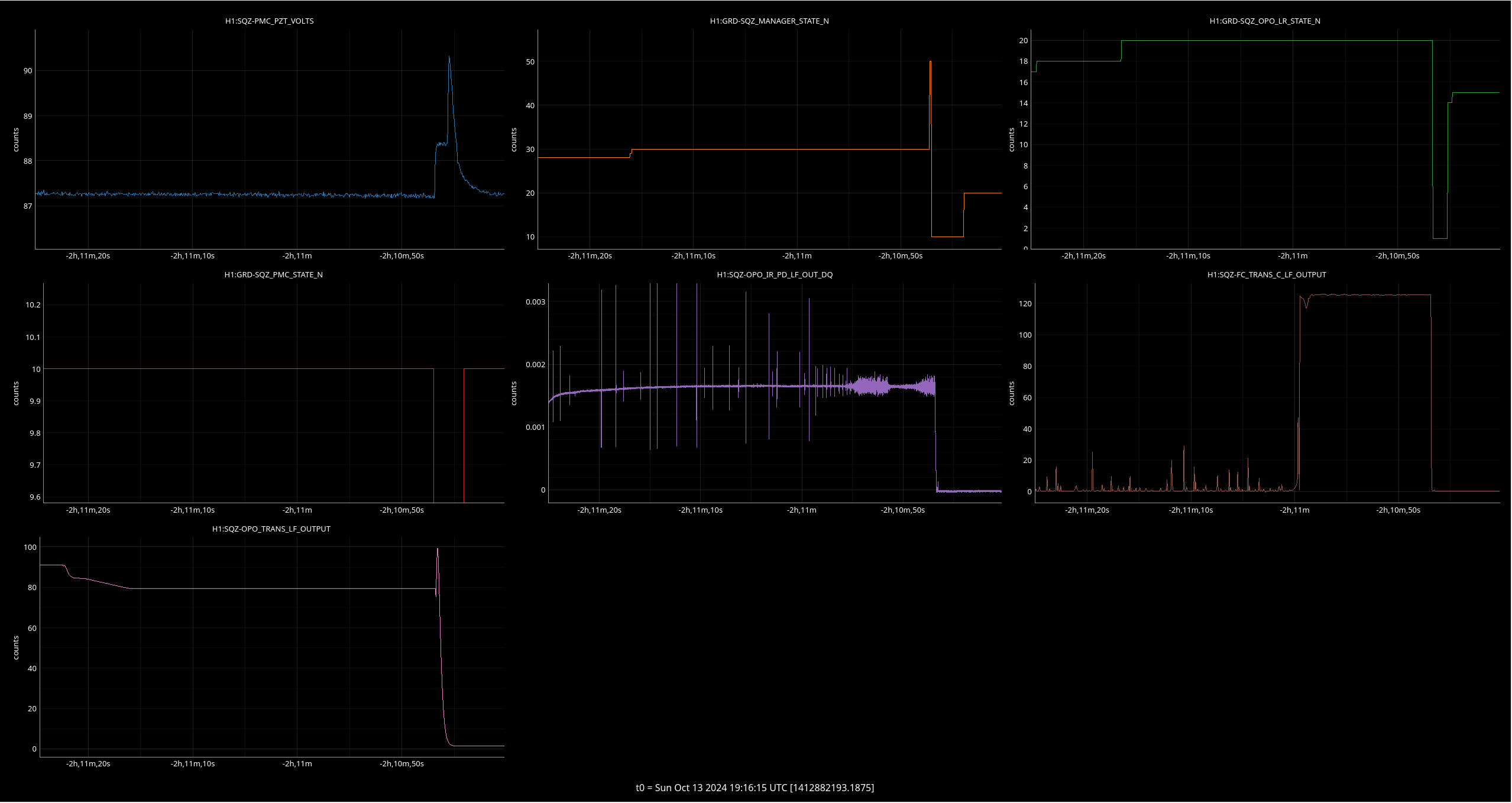
While damping violins, I noticed the SQZ pump ISS wasn't staying locked. Eventually I got to the solution of increasing the SHG launch power, but I first touched up the fiber polarization alignment by adjusting the half-wave plate on SQZT0 right before the fiber (motor 3) and minimizing the SQZ-SHG_FIBR_REJECTED signal (instructions found in alog71761). Then, I increased the SQZ-SHG_LAUNCH signal to about what it was during the previous lock stretch (17.6) by adjusting the half-wave plate immediately after the AOM on SQZT0 (motor 2). After that, I simply re-requested SQZ_MANAGER to FREQ_DEP_SQZ and squeezing was injected without issue.
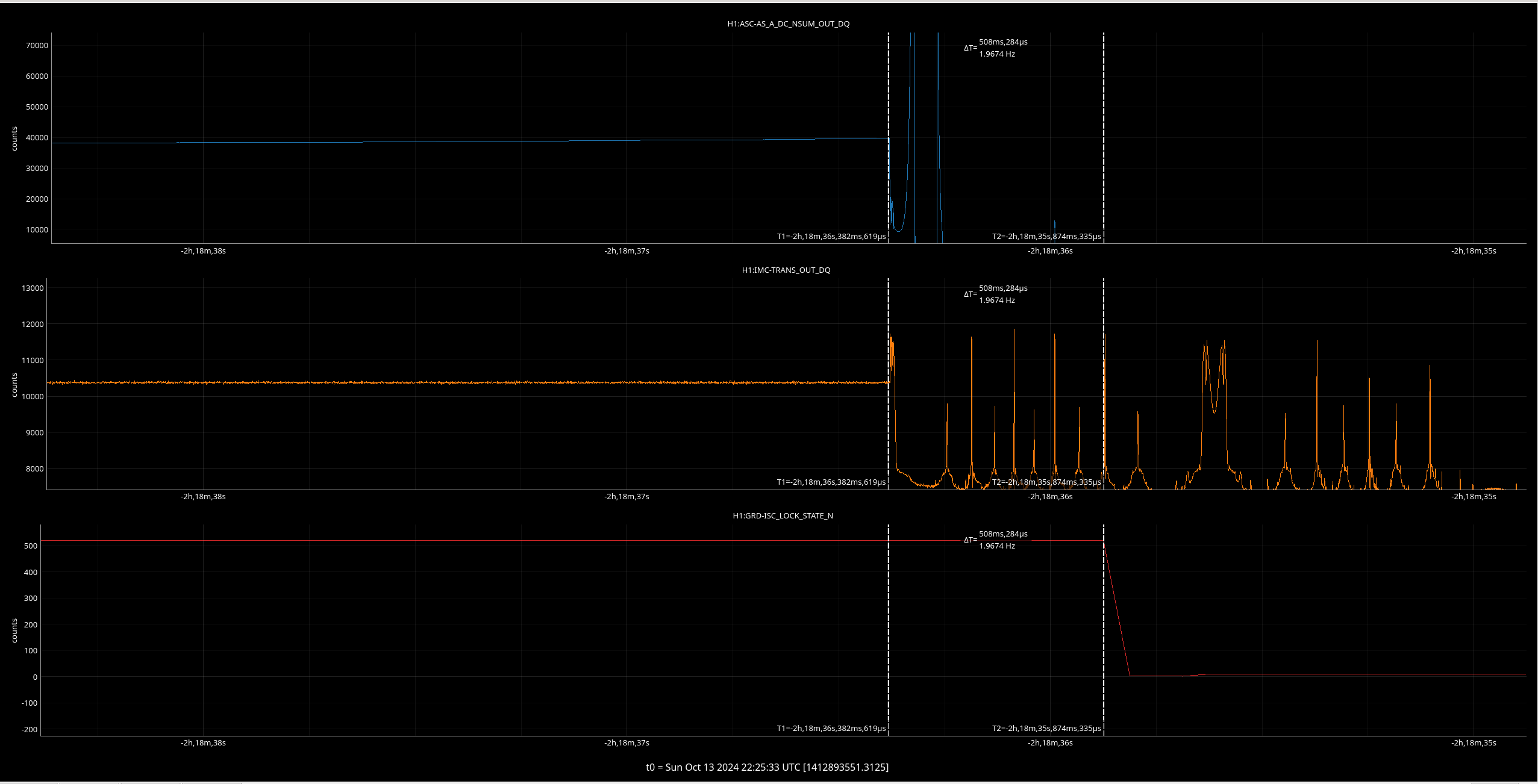
- 02:14 - Lockloss in OMC_WHITENING
- 03:24 - Reached NLN fully automatic
- 03:26 - Started observing
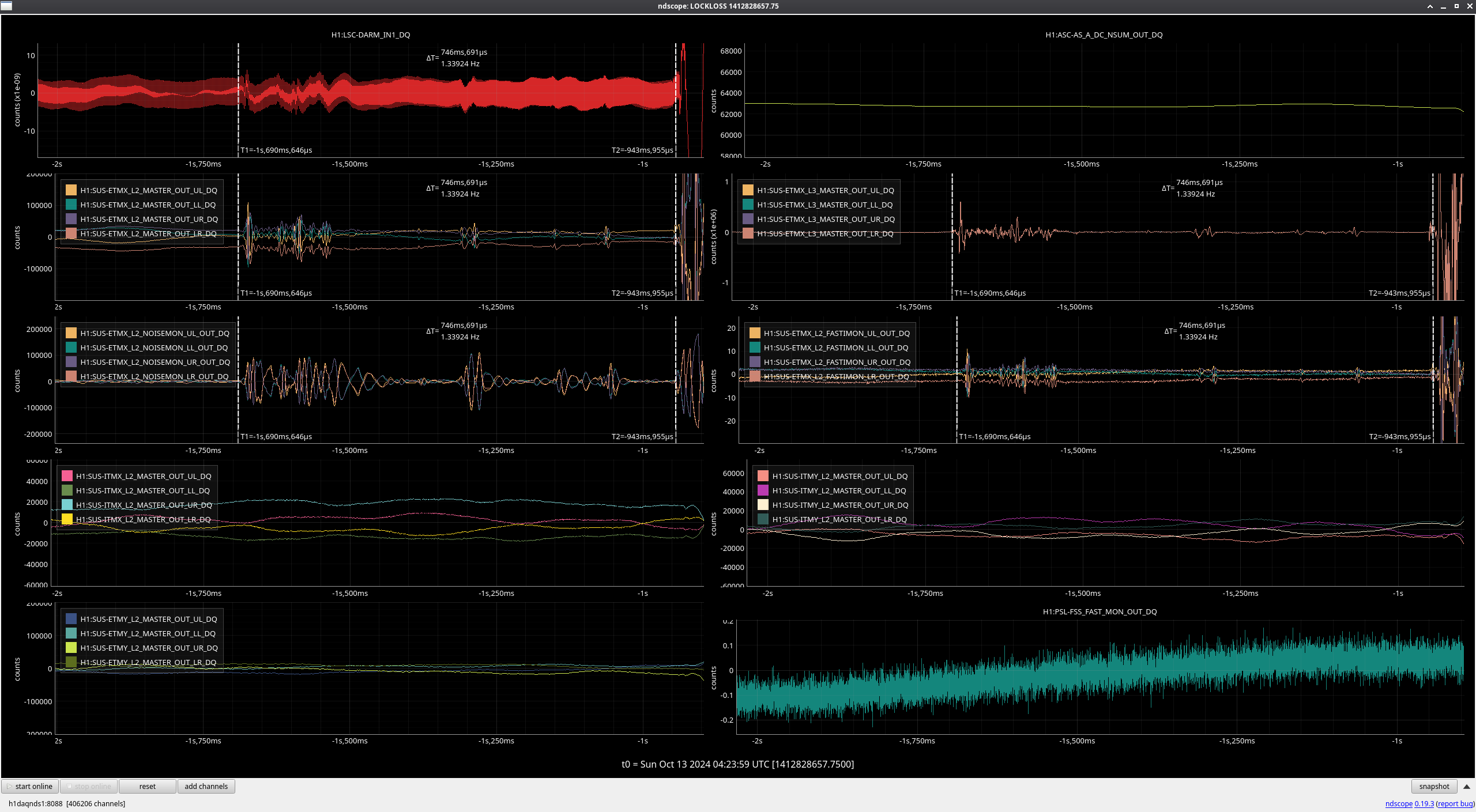
- 04:24 - Lockloss (ETMX glitch) - alog80638
H1 is currently relocking up to MAX_POWER.