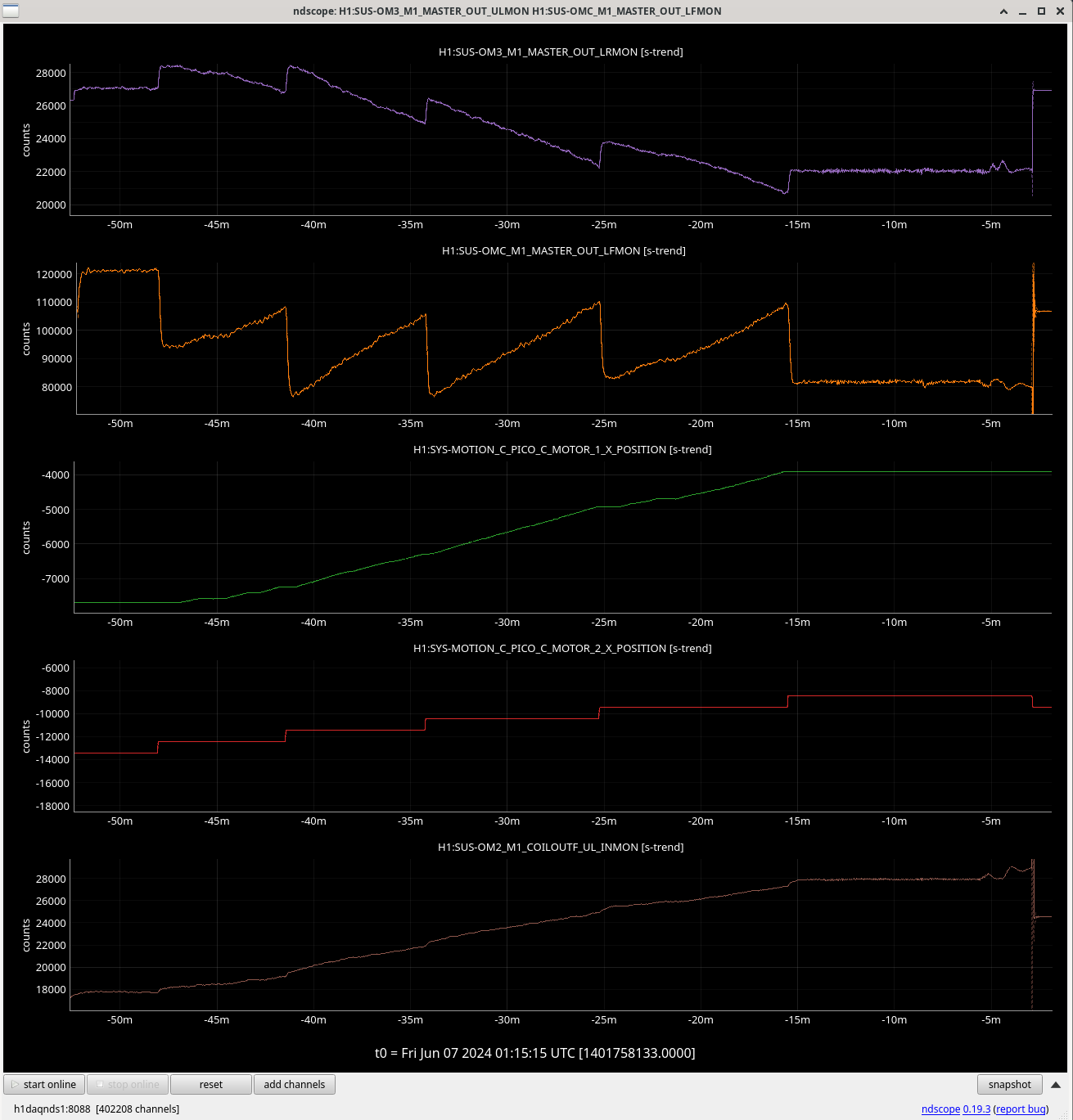
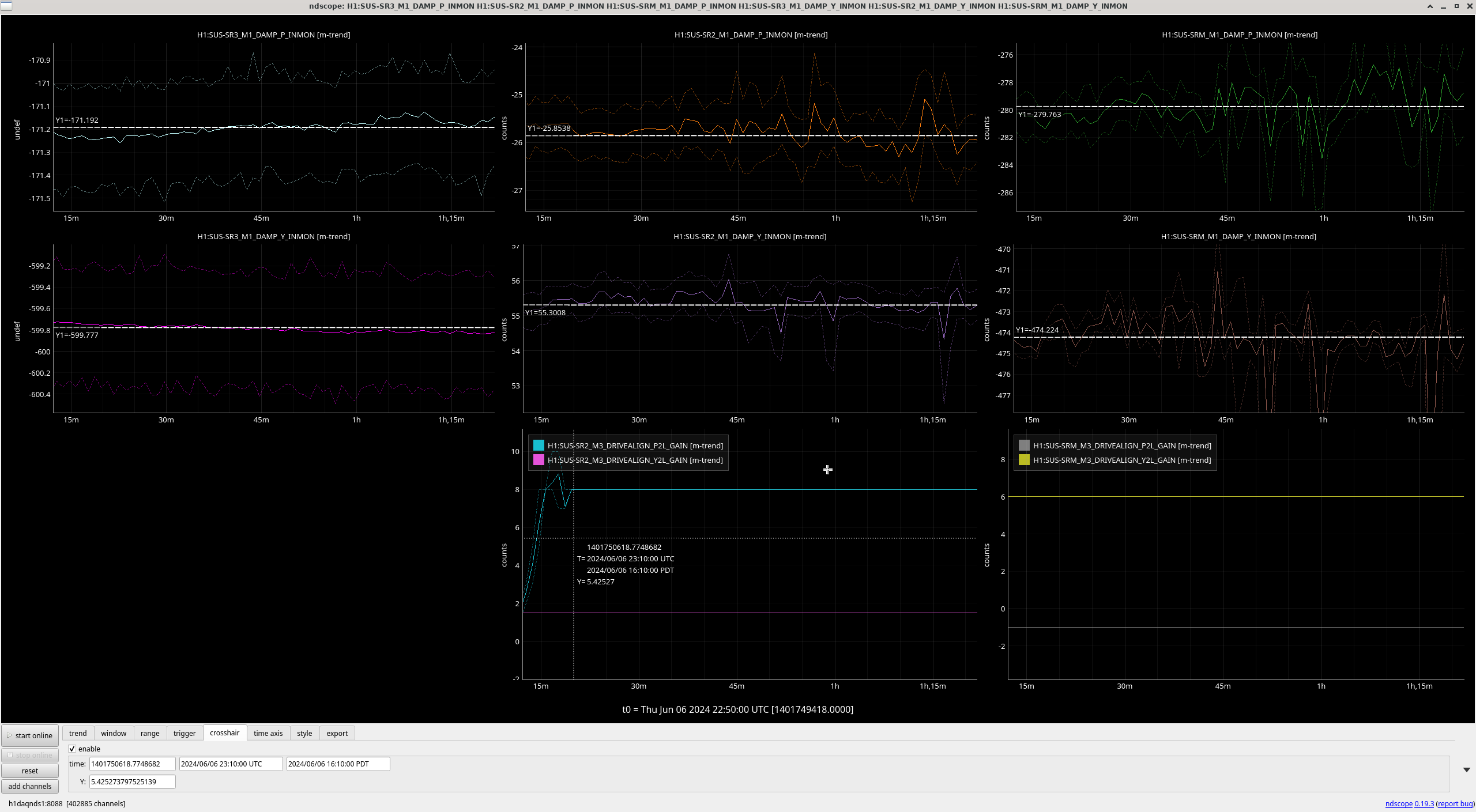
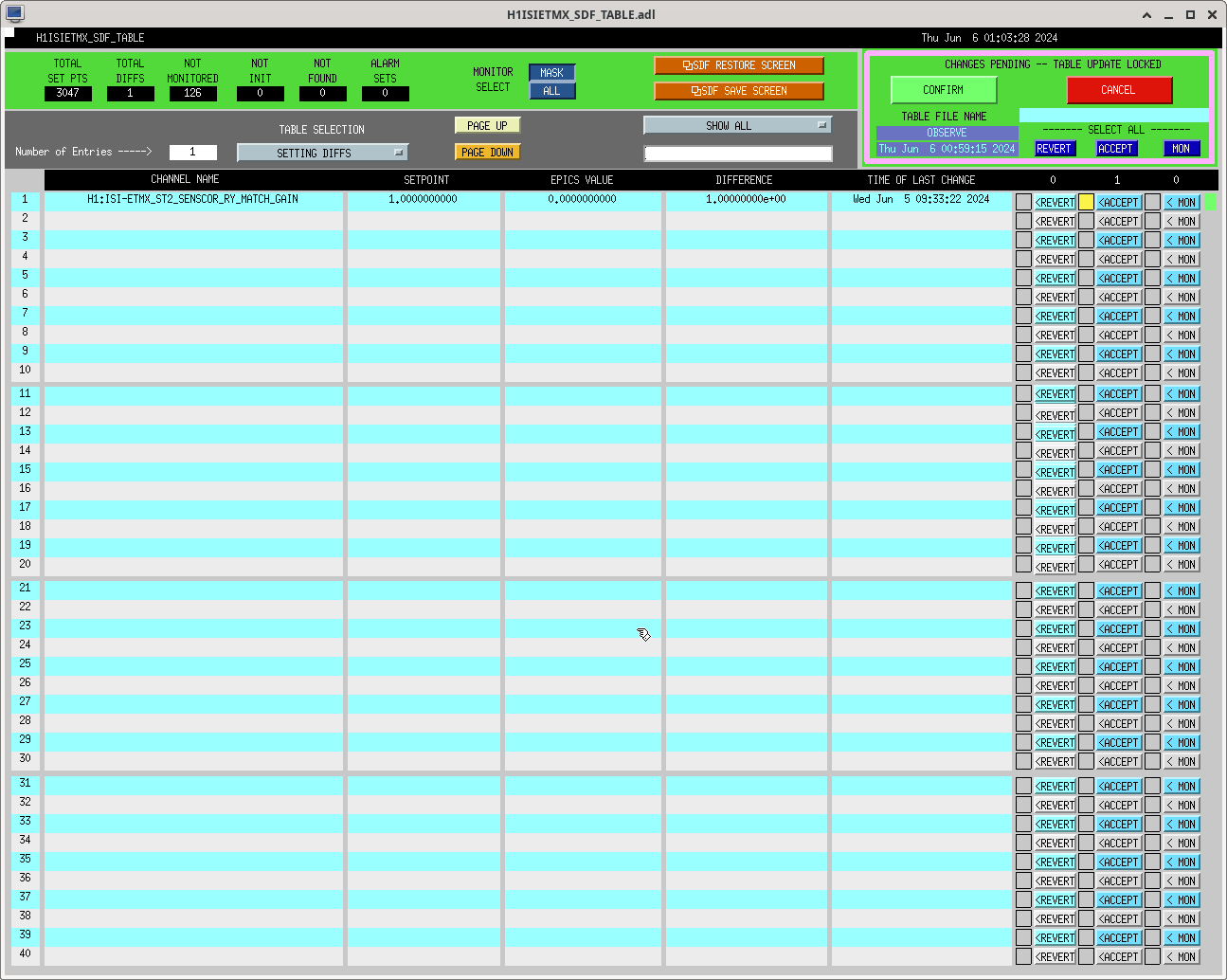
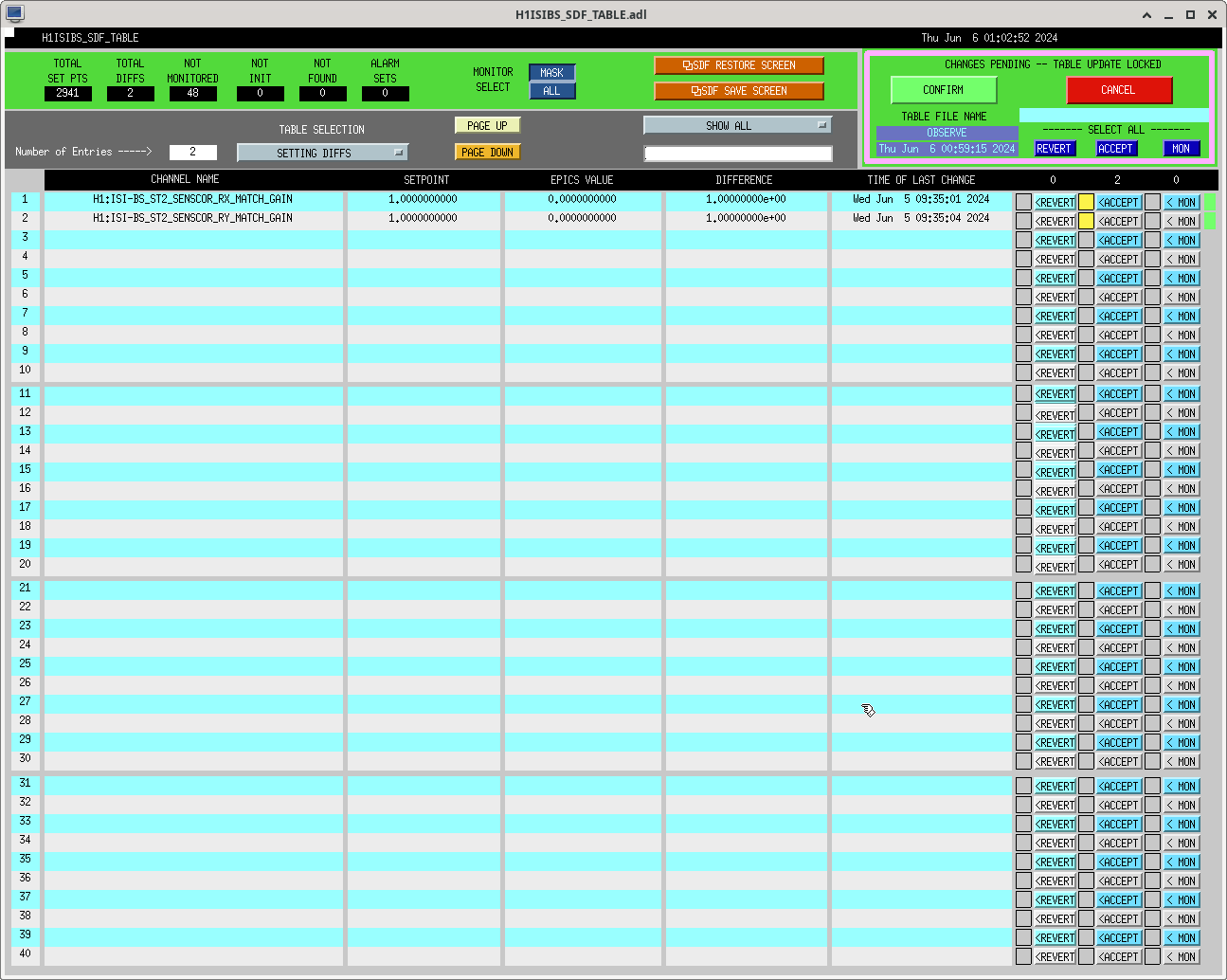
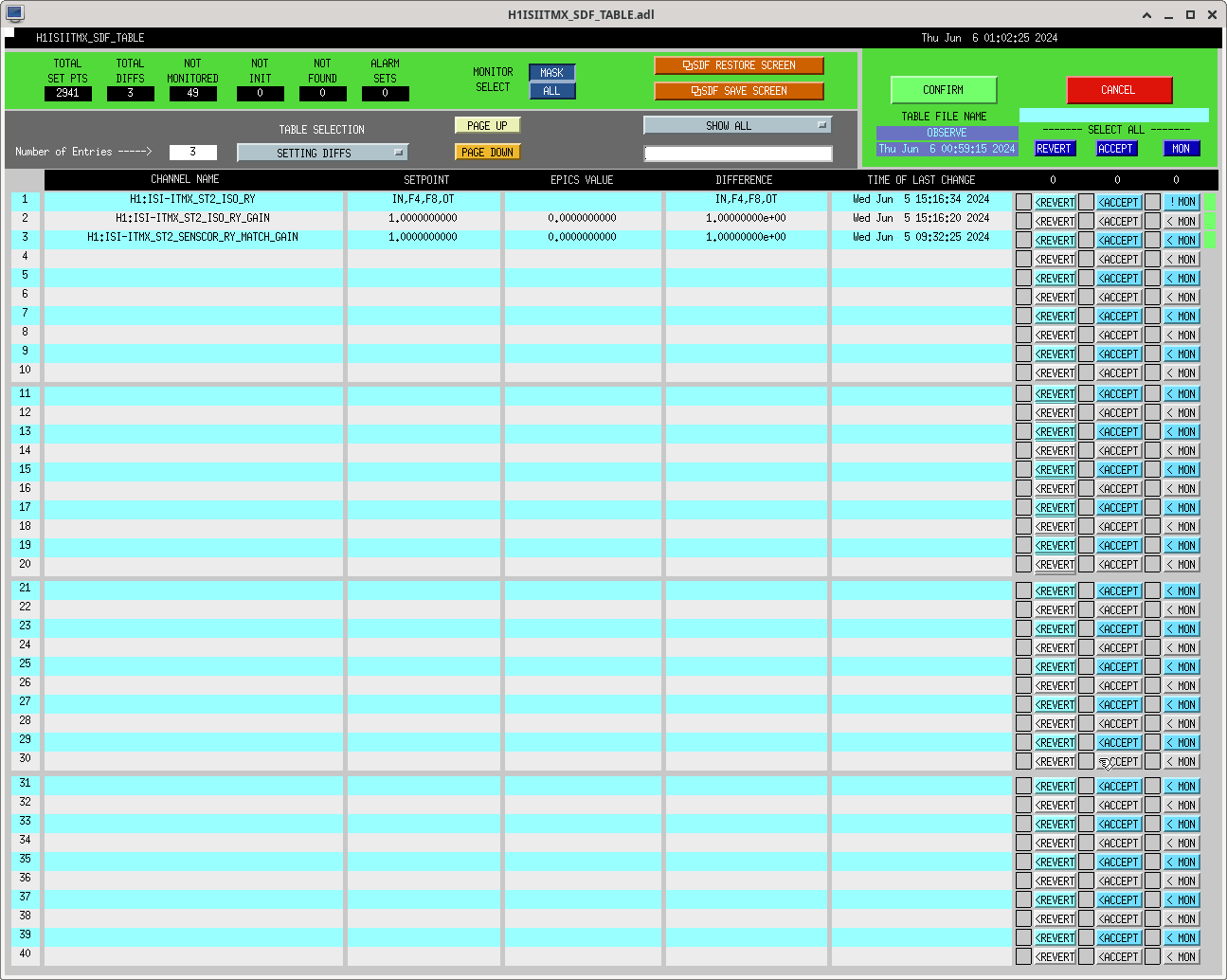
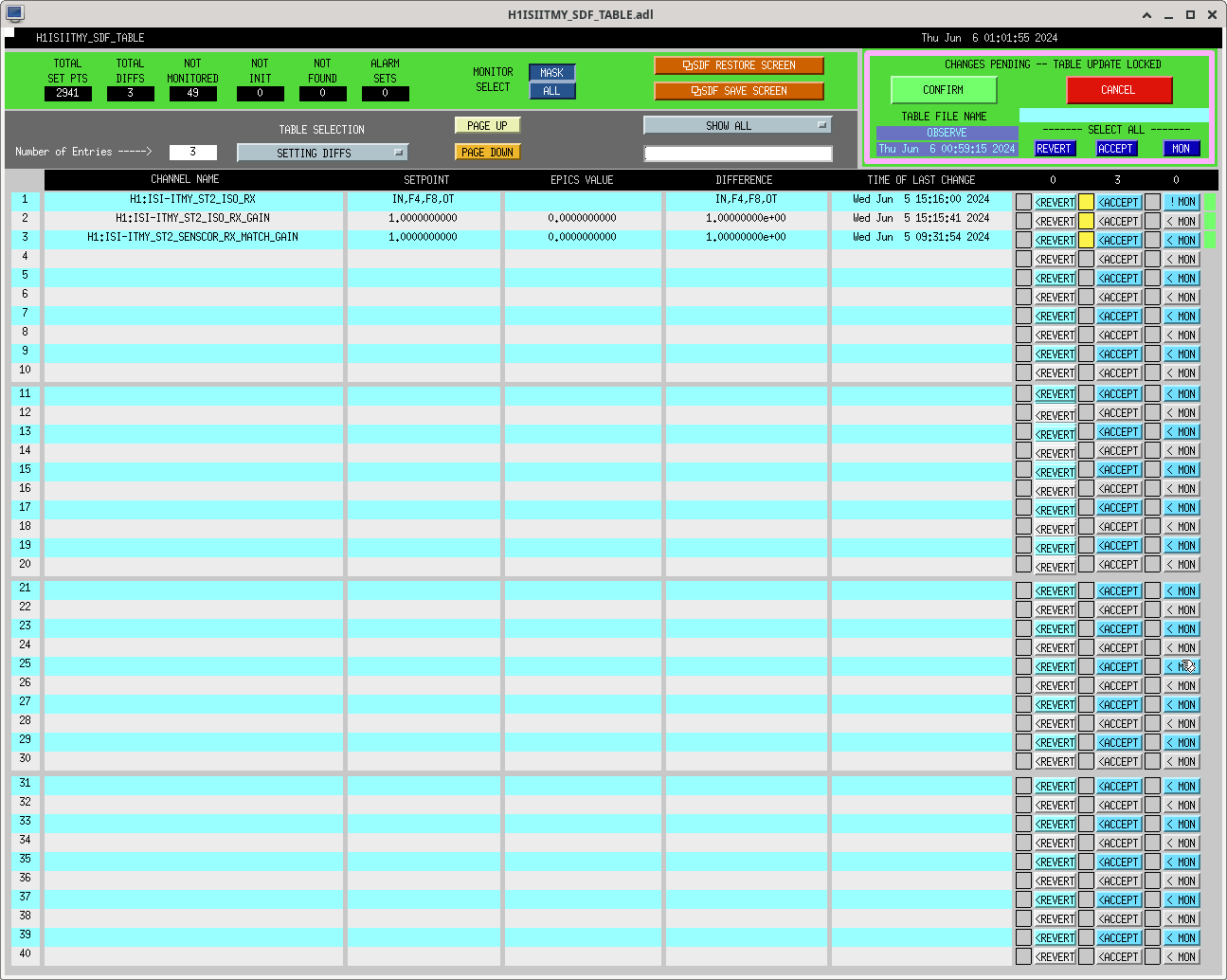
ibrahim.abouelfettouh@LIGO.ORG - posted 19:21, Thursday 06 June 2024 (78292)
IFO Out Suspensions (OMC, OM2, OM3) OSEM Master Out Count Delta During Powerup
Jenne, Ibrahim
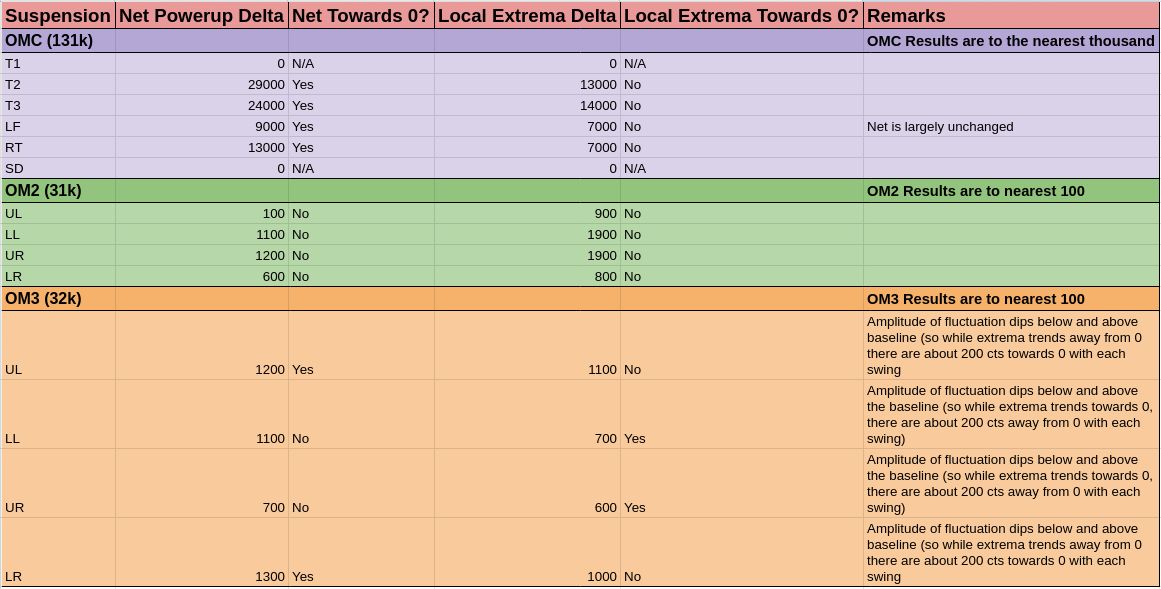
Trended the net movements of some OM suspensions during powerup from our most recent lock acquisition (2024-06-06 10:21UTC to 2024-06-06 15:56 UTC). This was done during today's comissioning to know whether our new OFI alignment configuration would saturate our IFO Out suspensions during powerup. Therefore, this data is just one reference of how much these suspensions usually move during powerup. For details on the actual OFI move today, refer to alog 78290. I've attached an identical (and prettier) sheets screenshot of the table below.
Suspension |
Net Powerup Delta |
Net Towards 0? |
Local Extrema Delta |
Local Extrema Towards 0? |
Remarks |
OMC (131k) |
|
|
|
|
OMC Results are to the nearest thousand |
T1 |
0 | N/A | 0 | N/A | |
T2 |
29000 | Yes | 13000 | No | |
T3 |
24000 | Yes | 14000 | No | |
LF |
9000 | Yes | 7000 | No | Net is largely unchanged |
RT |
13000 | Yes | 7000 | No | |
SD |
0 | N/A | 0 | N/A | |
OM2 (32k) |
|
|
|
|
OM2 Results are to nearest 100 |
UL |
100 | No | 900 | No | |
LL |
1100 | No | 1900 | No | |
UR |
1200 | No | 1900 | No | |
LR |
600 | No | 800 | No | |
OM3 (32k) |
|
|
|
|
OM3 Results are to nearest 100 |
UL |
1200 | Yes | 1100 | No | Amplitude of fluctuation dips below and above baseline (so while extrema trends away from 0 there are about 200 cts towards 0 with each swing |
LL |
1100 | No | 700 | Yes | Amplitude of fluctuation dips below and above the baseline (so while extrema trends towards 0, there are about 200 cts away from 0 with each swing) |
UR |
700 | No | 600 | Yes | Amplitude of fluctuation dips below and above the baseline (so while extrema trends towards 0, there are about 200 cts away from 0 with each swing) |
LR |
1300 | Yes | 1000 | No | Amplitude of fluctuation dips below and above baseline (so while extrema trends away from 0 there are about 200 cts towards 0 with each swing |
Images attached to this report