J. Kissel, J. Rollins, E. Goetz (with ideas, support and inspiration from others)
Picking up where I left off on the saga of the IFO's thermalization vs. the DARM sensing function (LHO:69593), the open actions were:
(a) more, lower, frequency points
(b) synchronizing the thermalization period to a point in time
(c) more data sets
all to better understand if the sensing function during each thermalization period evolved consistently -- since we saw that the first three examples looked very much not consistent.
Namely, we're still craving a single metric of thermalization that we can use to create a look-up table for "when the metric is value Z, apply this XX% / YY deg frequency dependent transfer function amount of extra modeled systematic error to the sensing function's budget of systematic error."
I've not yet been able to execute (a), and probably won't before the start of the run (and thus maybe never). So we'll have to model what we can from these four frequency points.
This aLOG focuses on (b) and (c).
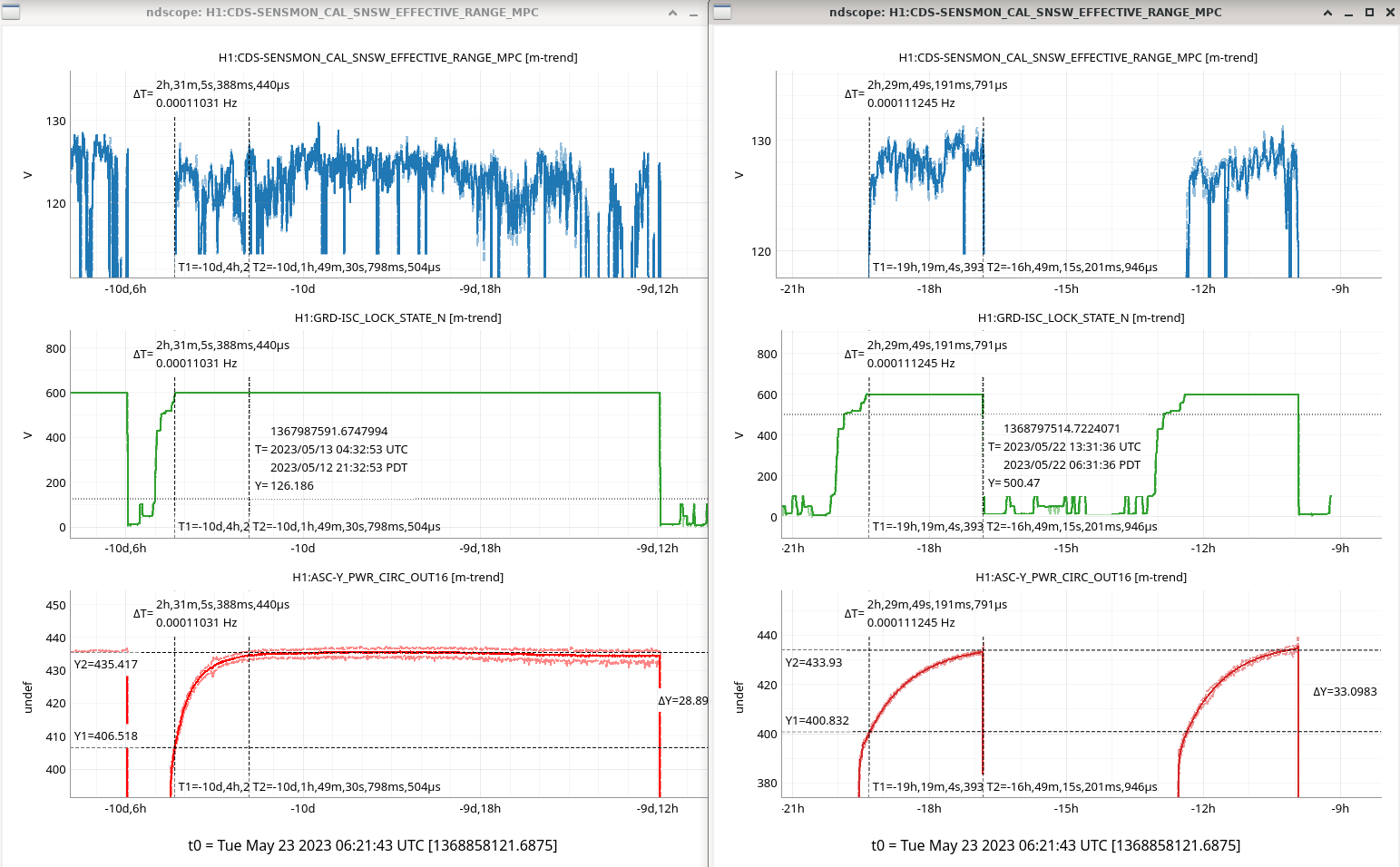
Regarding the number of data sets, (c), where LHO:69593 only characterized 3 data sets, here I've gathered 10, all since May 10th 2023. The times and durations are:
UTC Start UTC Stop GPS Start GPS Stop Duration Ref. ID Notes
2023-05-20 22:00 2023-05-21 02:00 1368655218 1368669618 4.00 1 (has systematic error lines amp increase)
2023-05-20 15:40 2023-05-20 19:40 1368632418 1368646818 4.00 2 (has systematic error lines amp increase)
2023-05-20 07:45 2023-05-20 11:45 1368603918 1368618318 4.00 3 (has systematic error lines amp increase)
2023-05-19 19:30 2023-05-19 23:30 1368559818 1368574218 4.00 4 (has systematic error lines amp increase)
2023-05-18 11:00 2023-05-18 15:00 1368442818 1368457218 4.00 5
2023-05-17 18:48 2023-05-17 22:00 1368384498 1368396018 3.20 6
2023-05-16 04:48 2023-05-16 08:47 1368247698 1368262038 3.98 7 (has glitch)
2023-05-15 04:50 2023-05-15 08:50 1368161418 1368175818 4.00 8
2023-05-14 08:15 2023-05-14 11:45 1368087318 1368099918 3.50 9
2023-05-10 11:18 2023-05-10 15:18 1367752698 1367767098 4.00 10
Note, here, unlike the few datasets before, we've (sadly) had enough lock losses that I can select for lock stretches that are 4 hours or longer.
This way, if we go with *time* synchronization, we have enough data within each stretch for the data to comfortably be declared "thermalized."
Regarding synchronization of data sets, Jamie had the idea of synchronizing the sensing function to IFO Arm Power rather than time, since the varies ways of looking at the data from LHO:69593 indicate that the sensing function evolves on several, mixed, exponential, if not random functions of time (especially with the first 30 minutes of the IFO achieving nominal input power). On the other hand, at least by eye and with what limited study we had, the arm power seemed to be evolving in the same way as the sensing function (and this intuitively made sense given that the optical spring present in the sensing function is some relationship between the carrier power in the arm cavities vs. the power in the SRC).
The pdf attachment, sensingFunction_syserror_vs_power.pdf, shows the comparison between these 10 data sets.
(i) Page 1: shows all 10 data sets' arm power as a function of time, and then
(ii) Pages 2-11: show 3D bode plots, where the frequency, magnitude, and phase of the sensing function systematic error transfer function are show against arm power (on the left) and time (on the right).
Note each "arm power" data point over the 4 hour stretch is the median power value over each two minute stride of 16 Hz data, and the data is created by the average of the two arm powers at each 16 Hz data point, from the channels
H1:ASC-X_PWR_CIRC_OUT16
H1:ASC-Y_PWR_CIRC_OUT16.
Here's what I observe from this collection of data sets:
(1) These additional data sets' sensing function is just as inconsistent in the first 30 minutes after achieving the nominal 76W PSL input power as the previous three from LHO:69593.
So, that means, if we're going to create a model of this systematic error to add to the collection of time-dependent response function's systematic error like we did in O3, it's going to *have* to have large uncertainty, at least in the first 30 minutes.
(2) The arm power vs. time evolution is also inconsistent from lock-stretch to lock strength, both in rate of change as well as final thermalized arm power.
(x) During the discussion of the plots in LHO:69593, during last week's LHO commissioning meeting, the suggestion was that the thermalization may be dependent on how cold the optics are at the start of heating them back up, or -- phrased differently -- if it's been a while since the last well-thermalized, high power lock segment, then the heating up may look different.
This is consistent with what's seen here -- the orange data set (set 9, starting at 2023-05-14 08:15 UTC) is one of the lower starting powers, and achieves a higher power than the other 9 sets, at a faster rate. Unlike the other 9 data sets, set 9 had 13 hours of "dead time" prior to re-lock-acquisition, vs. most other data sets had "only" 3 hours or less of "dead time," so the supposition is that the optics have not yet full cooled down.
(y) Also, the thermalized power is different, but as much as 4-5 kW. This should be less of a big deal, because the SRC detuning will have landed on the SRCL offset value that *retunes* the response, which means the only thing *left* changing with time, or between lock stretch to lock stretch in the sensing function is the optical gain and cavity pole, which are constantly being measured and corrected for.
(3) The arm power will be about as good a metric for thermalization as log(time) -- not perfect good, but better than linear time.
So, we'll go with the arm power as the metric for thermalization, 'cause ...why not? We're winging this anyways, and we don't have time to research other channels or ideas (or even go back to other older ideas).
Now it's on to manipulating this data into arm power (as a proxy for time) slices, and them fitting the *collection* of 10 transfer function values at each arm power, such that we have a representative sensing function systematic error transfer function -- with quantified uncertainty -- at each arm power level. I.e. we'll "stack" these arm-power slices and feed them to the GPR fitting monster and then create a the desired look-up table of fits per arm power.















{kind=link}