[Sheila, TVo, Jenne]
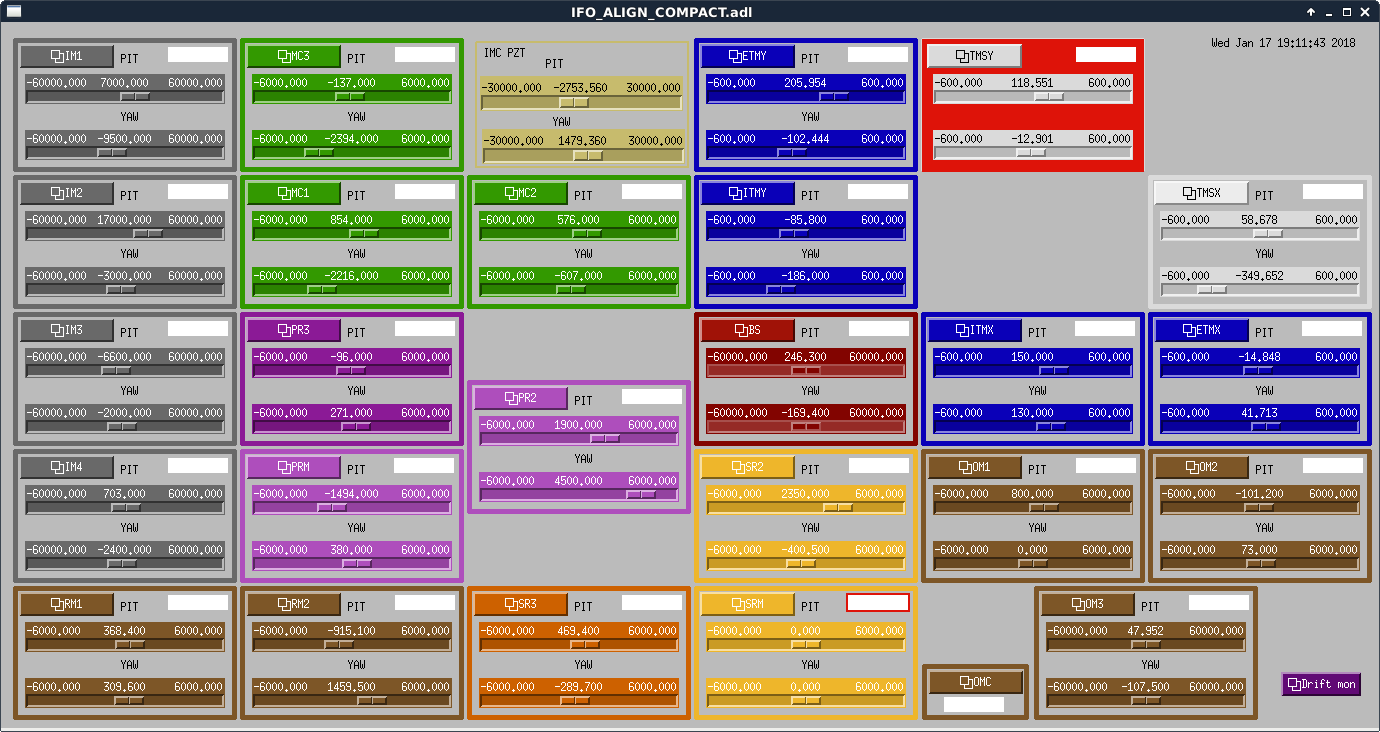
Today was an exercise in trying to get PRX aligned, so that we trusted our input beam and were on our way to being ready to align the HAM6 table. So far, we think that we have the beam aligned to ITMX, and that ITMX is aligned well enough to retroreflect the beam. We have not, however, been able to see flashes for PRX. We are seeing fringing on the REFL camera, and on REFL_RF9_I. Hoooray! (This is a little bit stream-of-consciousness...we were definitely totally absolutely going home several hours ago)
- Moved IM4 such that we're hitting the ASC_POP A&B QPDs. These are in the forward-going POP path.
- Moved PRM such that we're getting beam at the IFO REFL PDs and the camera on ISCT1.
- Moved PR2 such that we think we're centered on the aperture in front of PR3 (by looking at PR3 camera, which was refocused today).
- Moved PR3 such that the reflection from ITMX seemed centered in the PR3 aperture. Note that this was done with the non-final ITMX position, but it's pretty close.
- Moved ITMX such that we see light on the LSC_POP_A_LF channel, the DC of the RFPD. This PD is in the backwards POP path, so hitting it means that ITMX is retroreflecting the beam incident on it. Attached is a screenshot of the alignments in this situation (beam_on_LSC_POP_and_REFL_ITMX.png).
- Scanned PRM, looking at POP and some REFL signals in hopes of seeing flashing of PRX (peaks in POP diodes, dips in REFL). So far, we're not seeing anything flashing. So, pretty confusing, but if we're happy with the beam going to the ITMs, and can set the BS, maybe we don't care about the PRM right now, as we prepare to align HAM6?
- Noticed that it was possible to move ITMX such that there was more power on the ASC_POP, but we lost the power we were seeing on LSC_POP. Sheila and TVo were able to walk ITMX and PRM such that they got light on both LSC and ASC POP diodes, which means that both the forward-doing and backward-going POP beams are hitting their PDs. However, in this situation the beam is not going to the REFL port. Attached is a screenshot of the alignments in this situation (Return_beam_on_ASC_POP_A_LSC_POP_from_ITMX.png).
- We'd like to see if there is a way to move the input beam, and then have the PRM and ITMX follow, such that we have beam on REFL, LSC_POP and ASC_POP all at the same time. Hopefully this puts us in a place where we see PRX flashes.
- Currently trying this, using IM4 to keep the beam on LSC_POP, PR2 to keep the beam on ASC_POP, and moving the PRM to get back to the REFL port. When IM4 can't recover LSC_POP all the way, we moved ITMX a little bit (A thought - maybe moving IM4 was the wrong thing. If we are no longer hitting the ASC_POP diodes when the ITM is misaligned, then we should undo the IM4 move and compensate with ITMX).
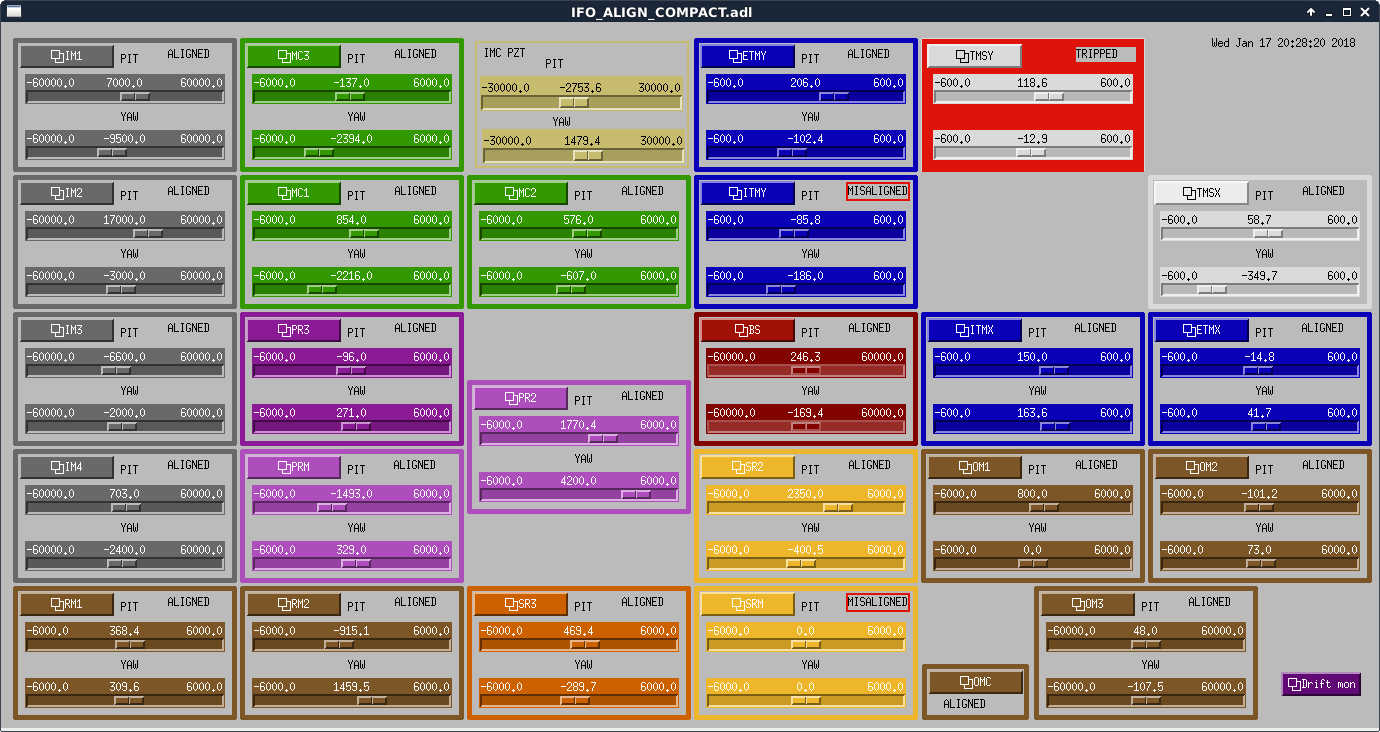
- [some time later....] It's working! We are seeing fringing on the REFL camera, and on REFL_RF9_I. (screenshot attached: ITMX_beam_on_LSC_POP_ASC_POP_REFL.png)
- I moved the RMs a bit to get centered on the REFL WFS, but maybe that wasn't needed. We can undo as we like.
- We're getting some real fringes! We lost some of our power on LSC_POP. Some of that was aligning for better fringes, but we also had a step that we don't know why we lost power. Sheila had been touching PRM pit, but went back to where she started and the power didn't come back. So, a little confused there, but very encouraged by our good fringes. Screenshot attached showing alignment, and some fringes on dataviewer: PRX_fringes_lost_LSC_POP_a_little.png.
- Currently adjusting ITMX to get back on LSC_POP, and using PR2 to recover fringes. We got a little better, so we're attaching a screenshot: PRX_fringes_LSC_POP_recovered_a_little.png
- Heading home.
Plan for going forward:
- We also want to set BS + ITMY such that we get beam retroreflected to the LSC and ASC POP diodes. We'll likely do this with ITMX misaligned, but once we restore ITMX we should be seeing MICH fringes.
- It will help a lot to have the BS camera back online as soon as possible.
- Once the BS camera is back, it would also be helpful if someone had a chance to check other cameras on the output arm (SR optics).
Note from Cheryl: There is some scattered light somewhere near the output of the Faraday. She has a photo looking in one of the viewports, and it's clear that there's light in places where we don't want light. Her suggestion was that perhaps the input beam is too close to a mirror near the output of the Faraday, and we're clipping. Her proposed check was moving IM1 to see if that scattered light glow (as seen on the PRM camera view that she set up) changed. Moving by a few thousand counts on IM1 didn't change the PRM camera image, so I'm not sure that it's the Faraday or the input beam we're having a problem with. We'll continue checking on this in parallel with the main alignment work.

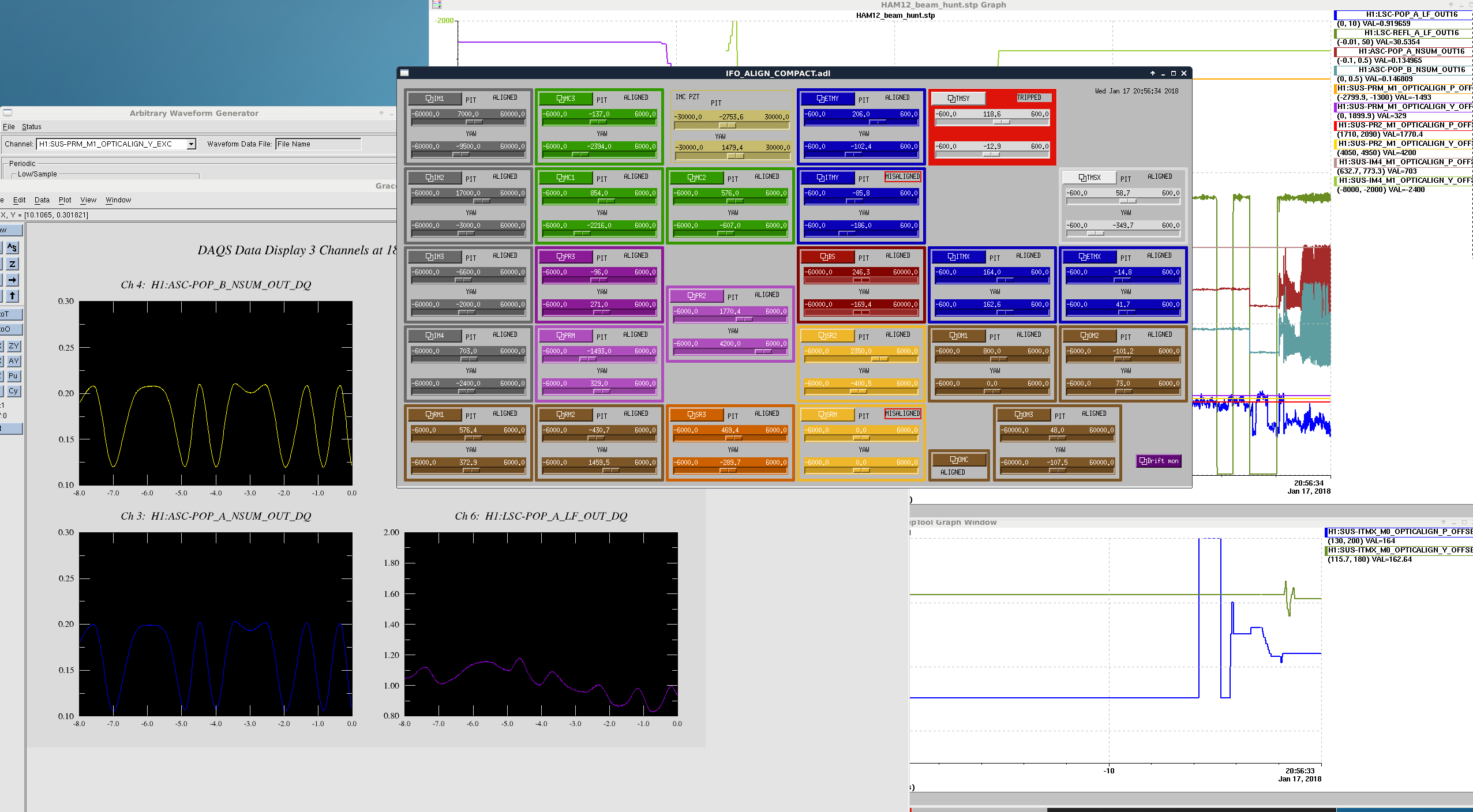
- Just kidding. We got excited and aligned BS and ITMY. Screenshot attached with PRY fringes (ITMX slider values correct, but the optic is misaligned via guardian). PRY_and_PRX_fringes.png
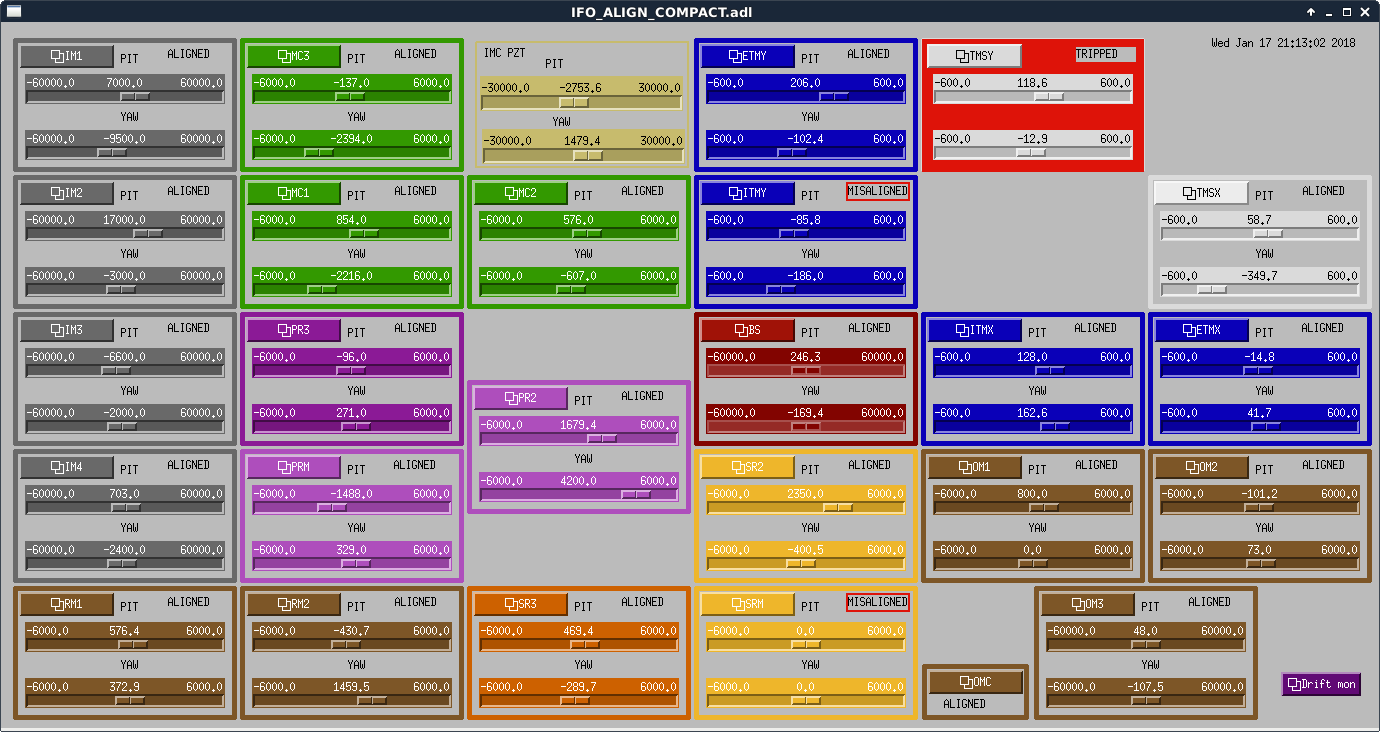
- We misaligned PRM and aligned both the ITMs, and saw nice MICH fringes. I think that we could lock to the POP LSC PD if we felt like it. See MICH_fringes.png
- Restoring PRM, we see that we're getting flashes on LSC_POP_A_LF. We need to check the alignment of ISCT1 so that we can use the sideband buildups for triggering.
We don't have analog cameras for POP, SR2. They might be unplugged? And I guess we need some CDS help to get the BS camera back. It would be helpful for alignment if we could have those all working tomorrow.
Note to ourselves: Tomorrow we will try to do SRY alignment to get down to HAM6.