patrick.thomas@LIGO.ORG - posted 15:58, Wednesday 10 May 2017 (36128)
Ops Day Shift Summary
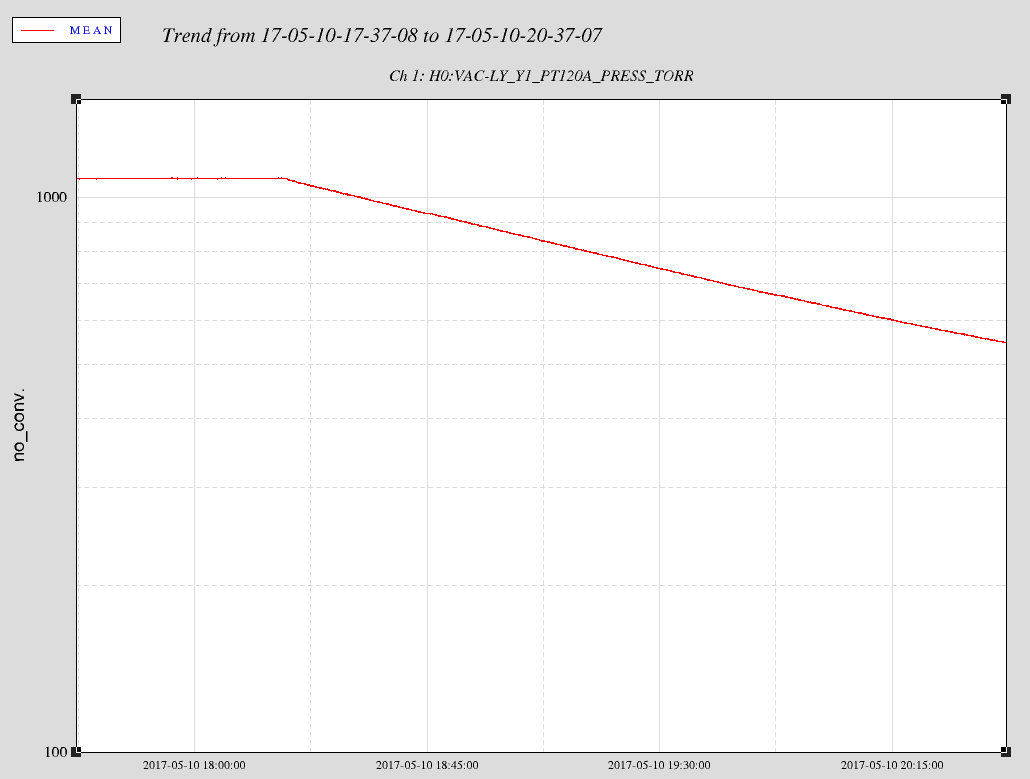
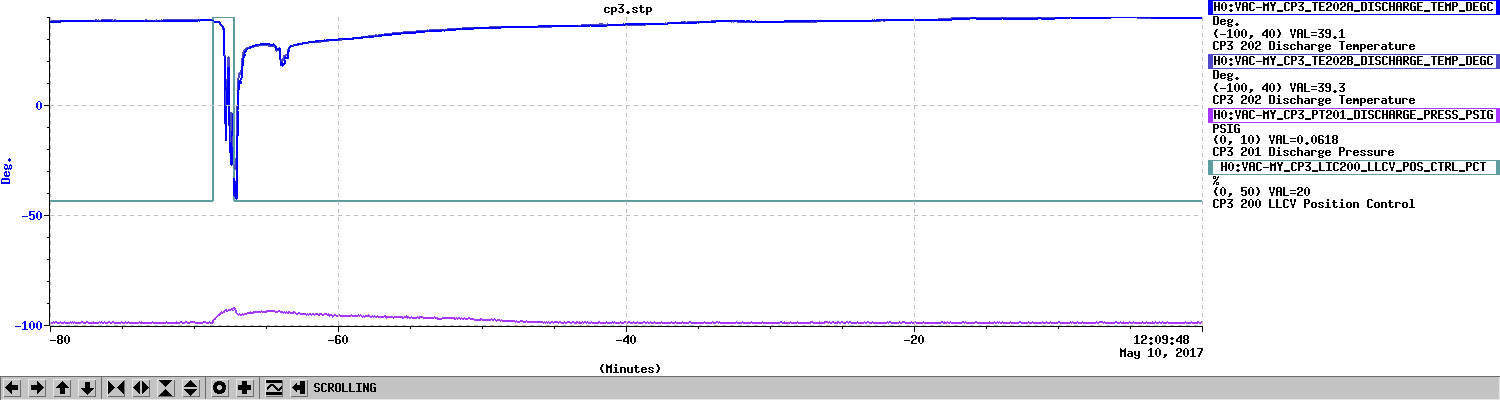
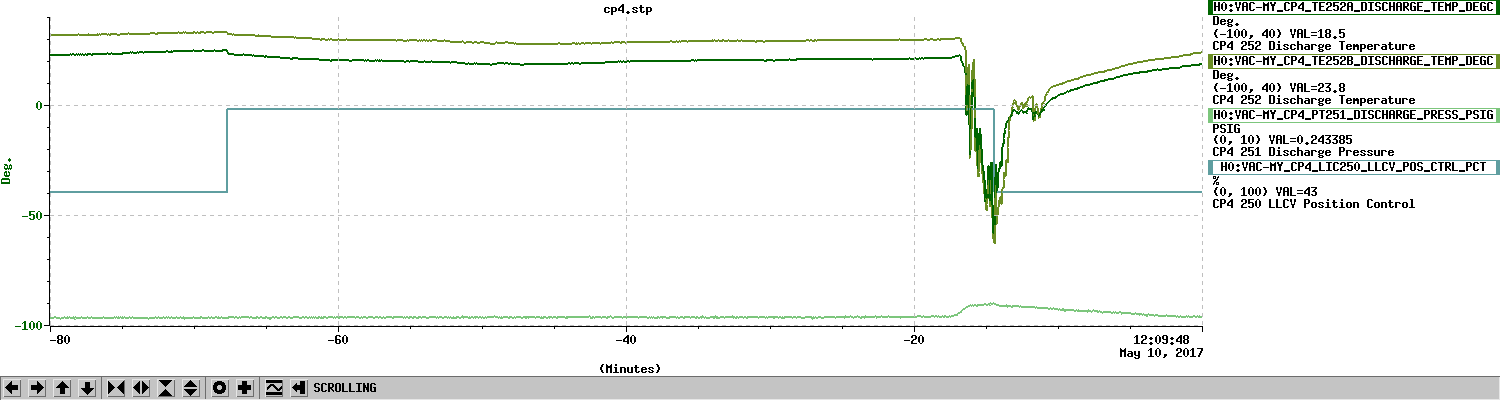
TITLE: 05/10 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC STATE of H1: Planned Engineering INCOMING OPERATOR: None SHIFT SUMMARY: Pump down of chambers has begun. LOG: 15:05 UTC Amber leading tour in control room 15:20 UTC Tour leaving control room 15:20 UTC Jeff B. to LVEA and cleaning area, survey for plumbing work 15:32 UTC Gerardo to CER mezzanine to check on HV, and to LVEA 15:46 UTC Jeff B. out 15:57 UTC WP from Chandra to begin pumping 16:00 UTC Travis to beer garden to clean up equipment 16:18 UTC Apollo at end Y, shutting down HVAC for FMCS upgrade 16:18 UTC Kyle to mid X and end X looking for cable 16:30 UTC Apollo through gate 16:37 UTC Kyle back 16:45 UTC Travis done (from email) 16:46 UTC Filiberto and Richard to LVEA tables to document serial numbers of photodiodes 16:47 UTC Karen to VPW and then staging building 17:39 UTC Filiberto and Richard done. Heading to end stations. 17:46 UTC Amber leading tour through control room 17:49 UTC Mike taking guest into LVEA 18:17 UTC Mike and guest out of LVEA 18:21 UTC Hugh had me set CS HEPI pumpcontroller setpoint to 0 18:17 UTC Roughing pumps have been started 18:28 UTC Richard and Filiberto back 19:22 UTC Gerardo, Kyle and Chandra out for lunch 19:37 UTC Hugh had me set CS HEPI pumpcontroller setpoint to 70 19:45 UTC Hugh done in CS 20:24 UTC Aidan and Nutsinee to LVEA to start rebuilding TCS table 20:37 UTC Jim and Hugh to end stations for HEPI accumlators and pump station maitenance 21:05 UTC Gerardo to LVEA to pick up equipment 21:06 UTC Marc to mid Y to pick up parts 21:08 UTC Filiberto to LVEA to help TCS crew reconnect cable 21:19 UTC Hugh at end Y 22:00 UTC Site Weekly meeting 22:54 UTC Hugh to LVEA