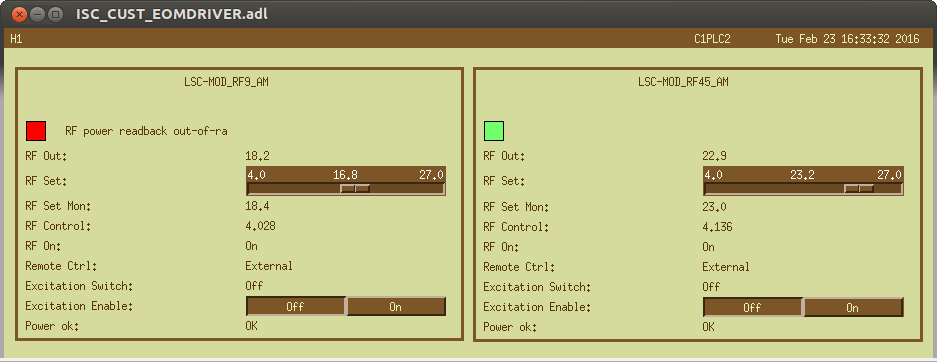
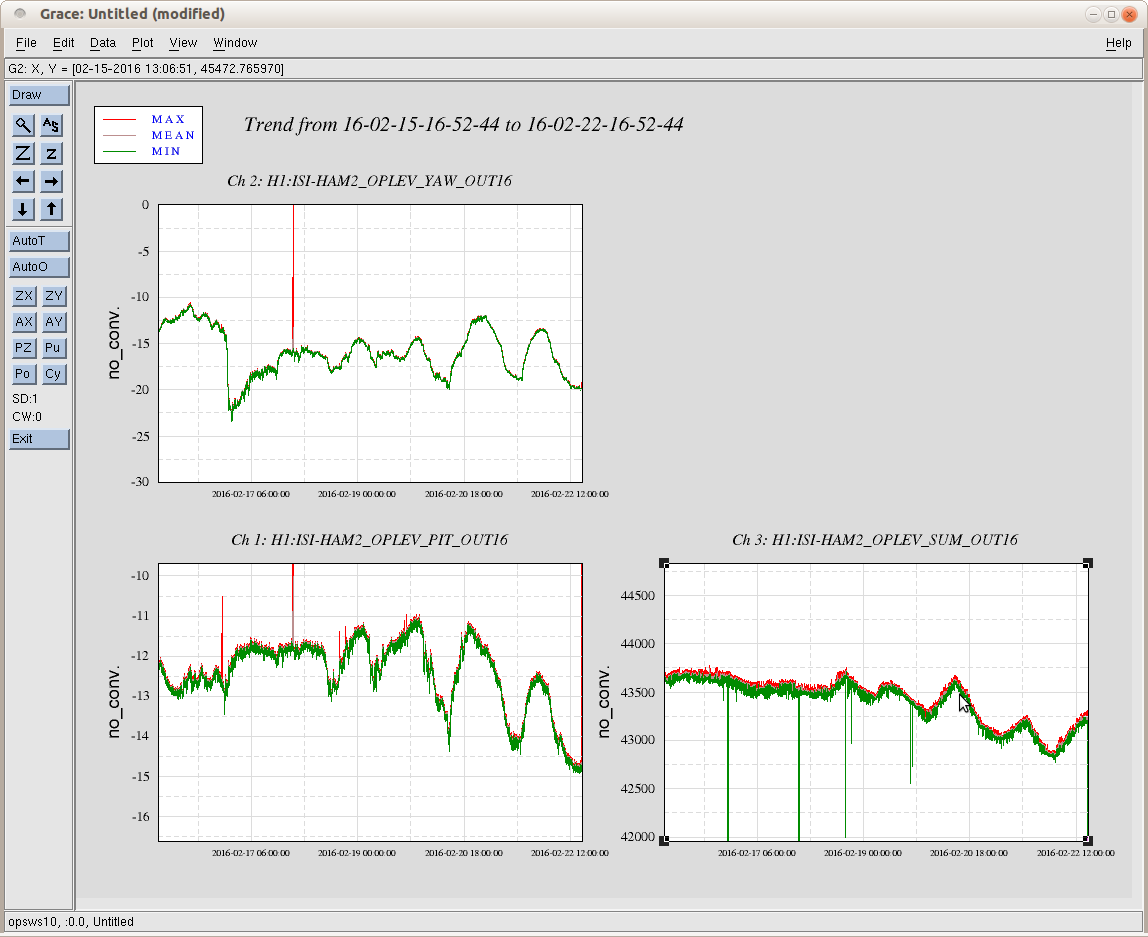
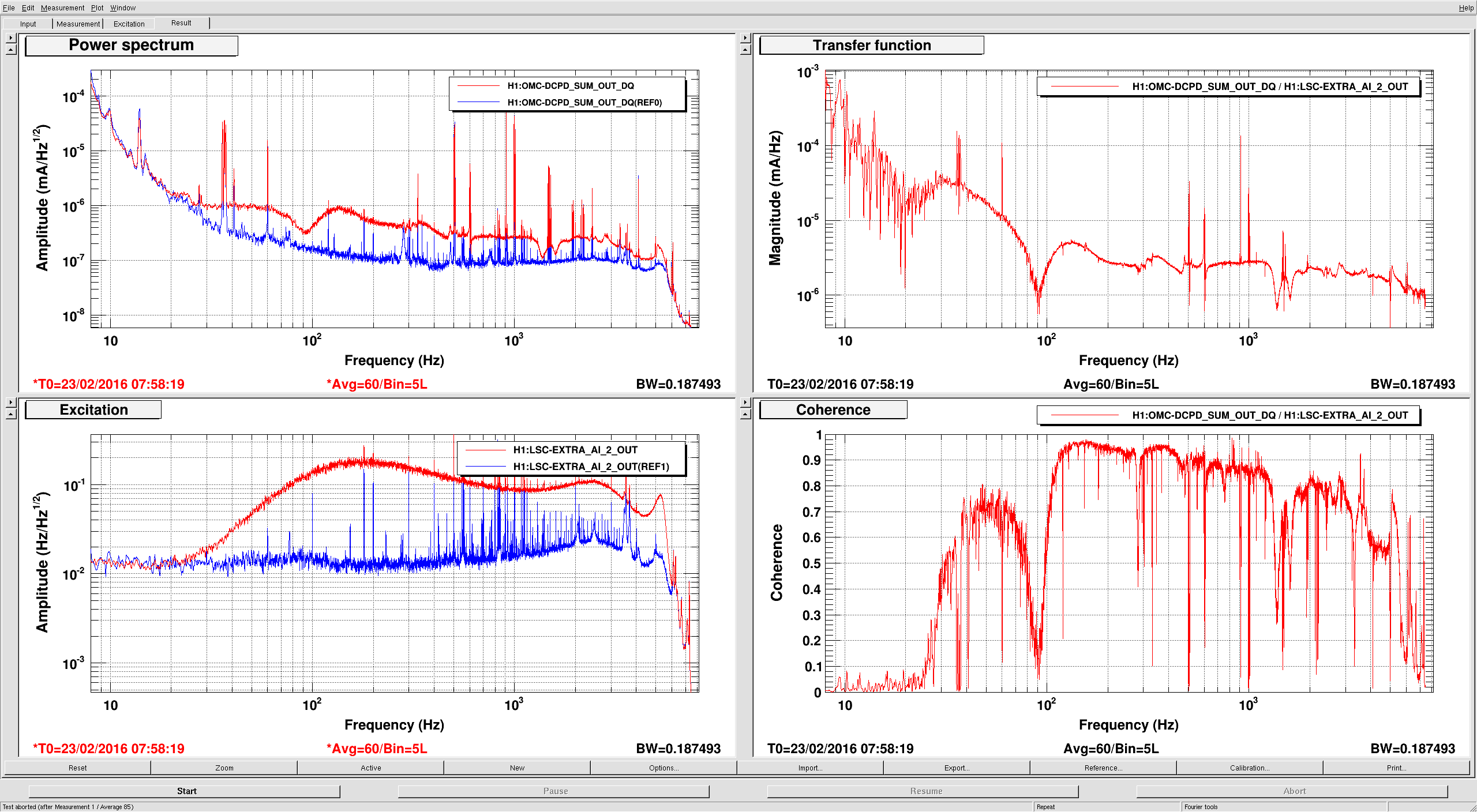
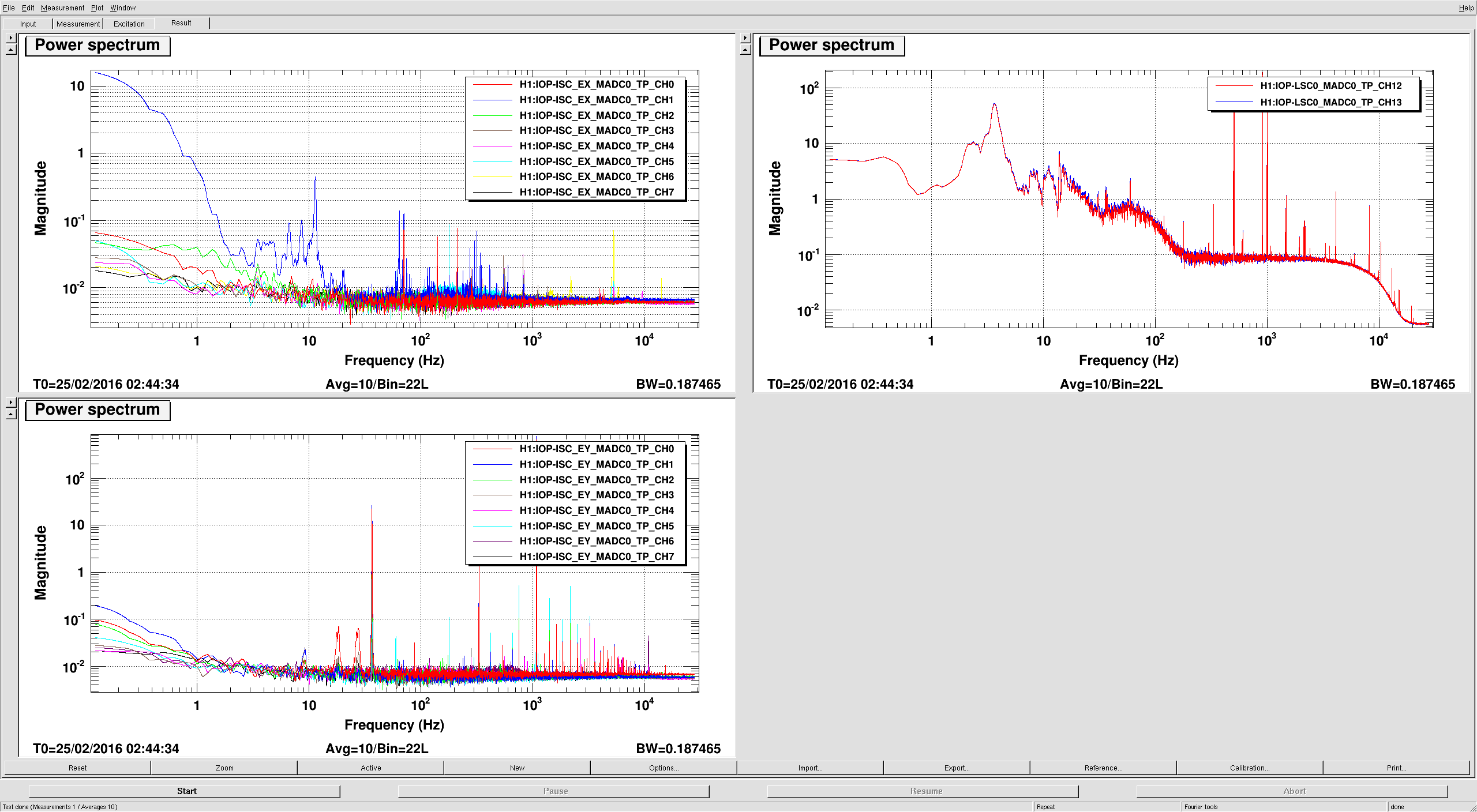
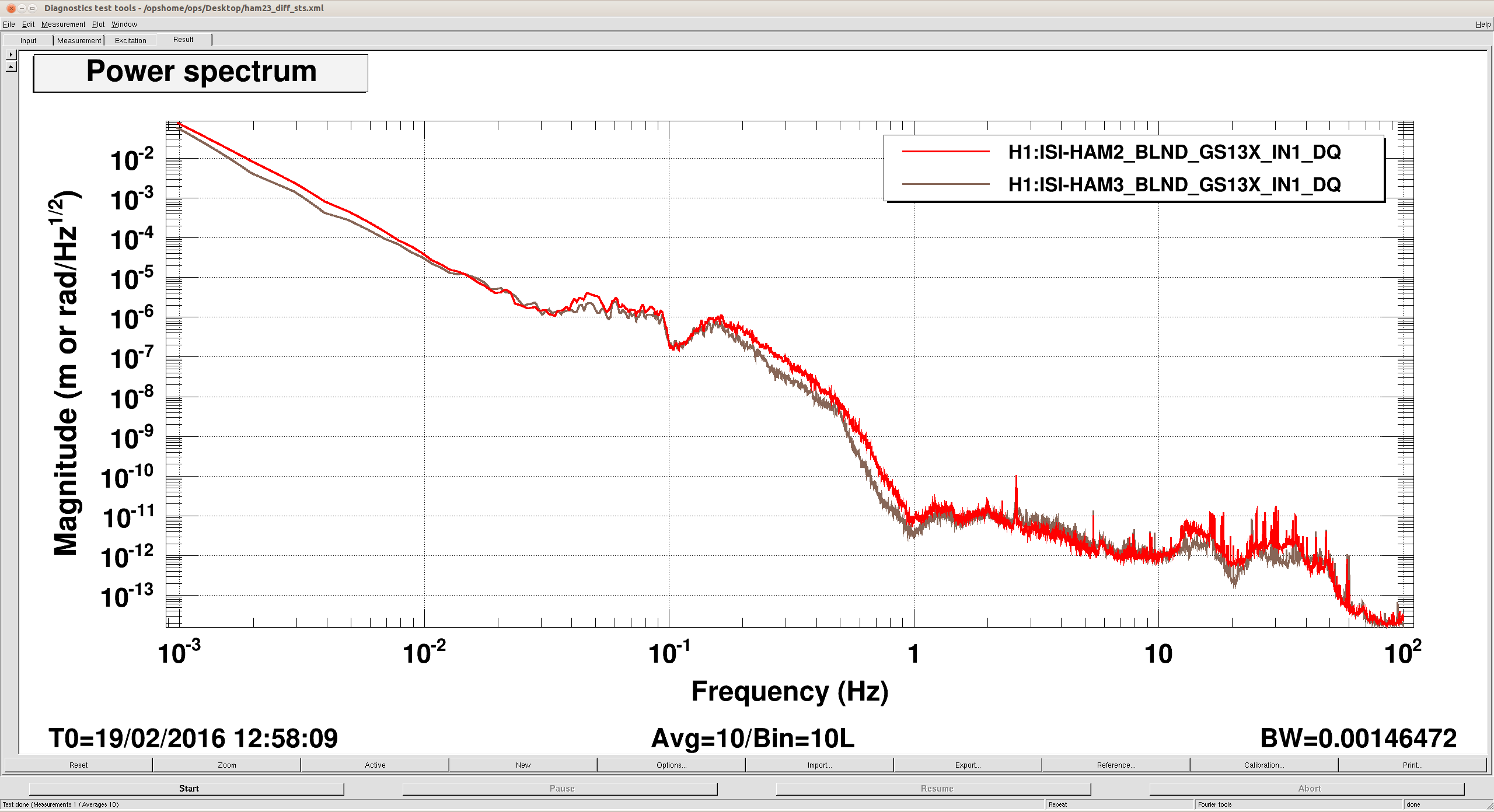
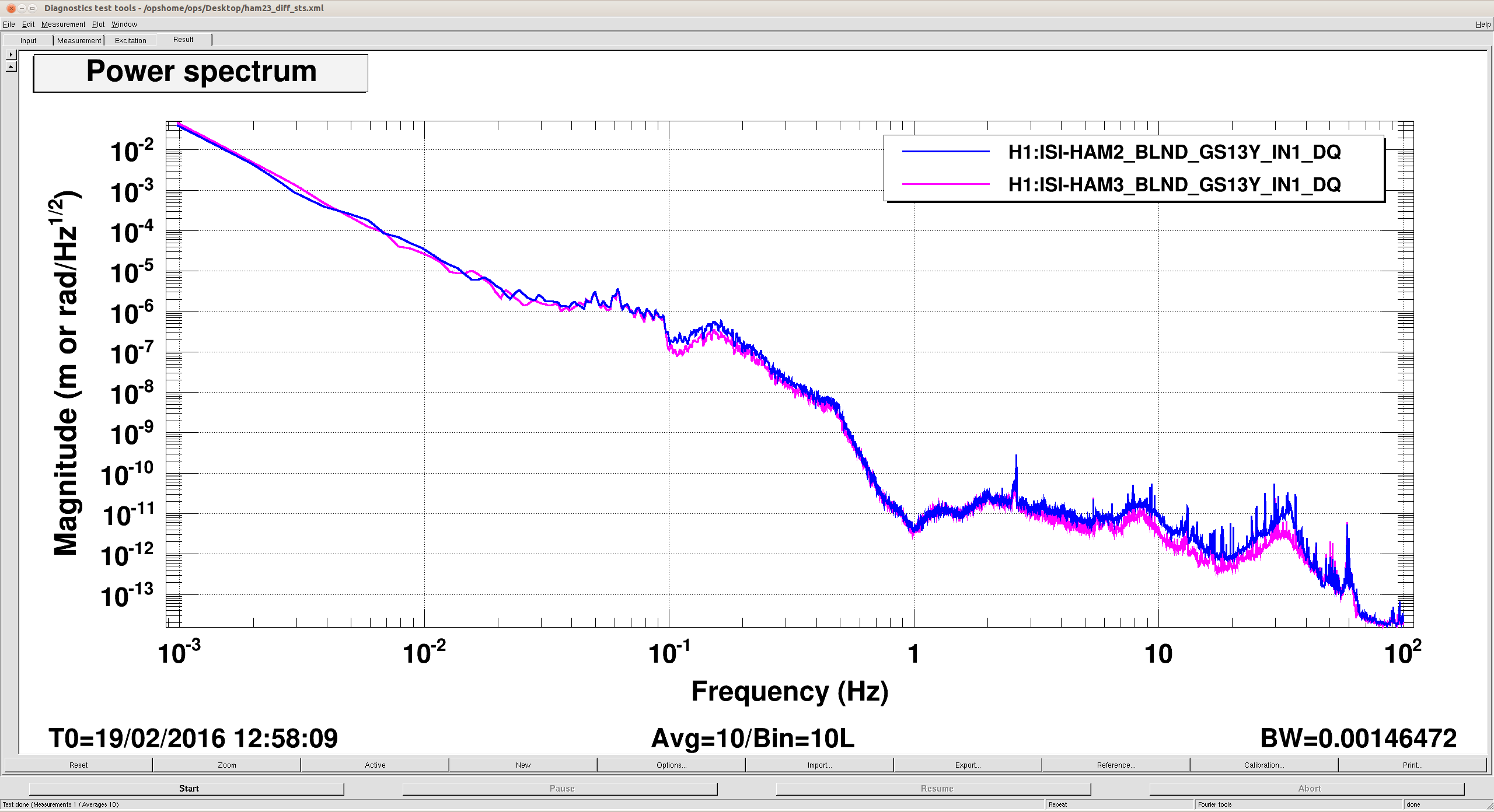
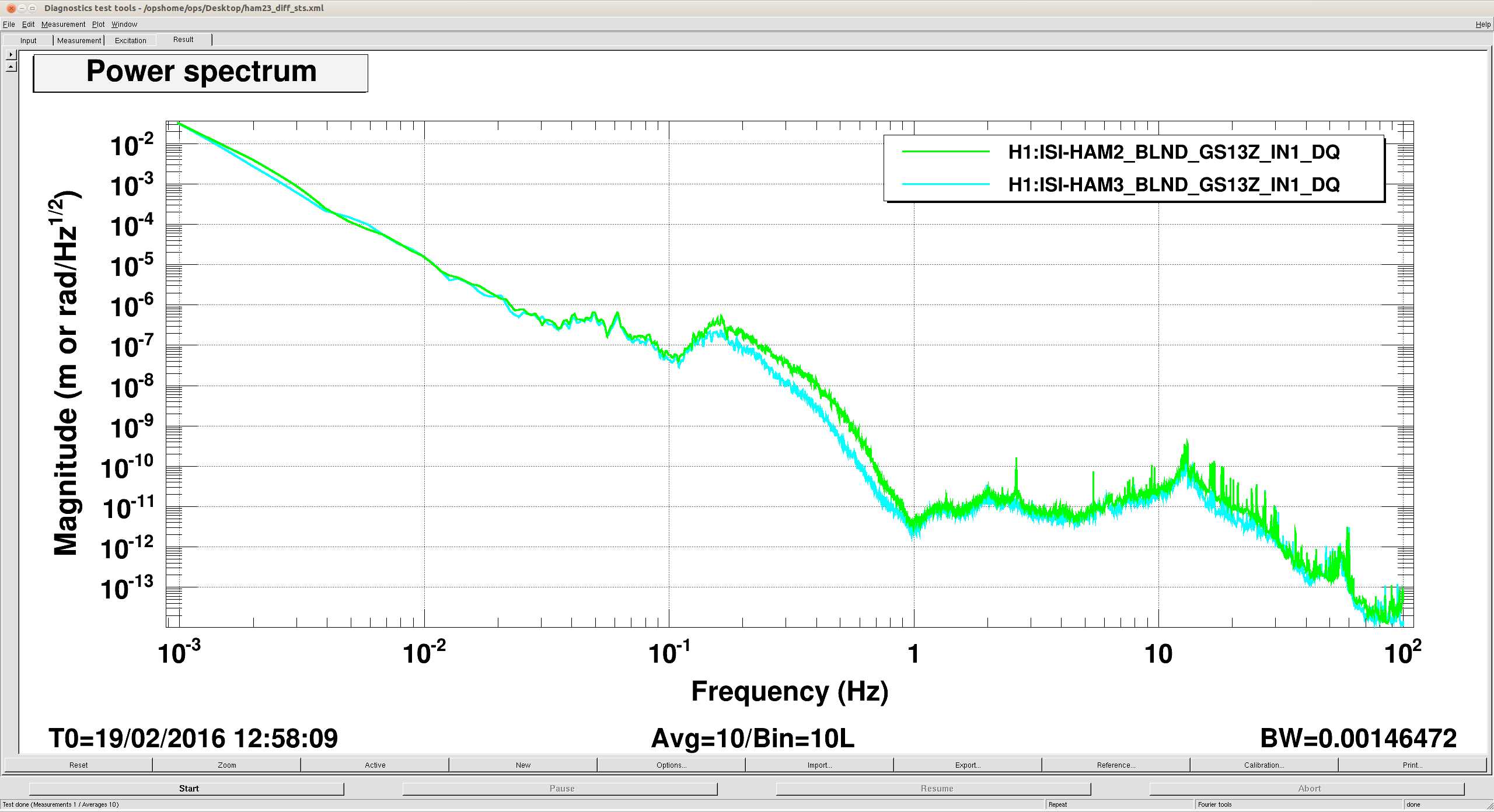
(All time in UTC)
15:20 Chris S. to X-arm (150 yards from corner station)
16:04 Jeff B. to Y end (Test Dust Monitor)
16:17 Let pest control in
16:30 Transitioned LVEA to LASER SAFE. Bubba to LVEA.
16:35 Joe escorting pest control through LVEA and VEAs.
16:37 Richard + Calos was up on the roof, not anymore (WP5743)
16:50 Hugh to both end stations (HEPI pump maintenance)
17:00 GRB/Supernova alarm
17:07 Brought MC1 and MC3 to SAFE for Richard's work
17:15 Bubba out of LVEA
17:29 Carlos rebooting NUC machines
17:30 Jim rebooting Guardian machine
17:42 Rick to PSL enclosure
17:47 Hugh back
Let Hanford fire dept. in -- to X arm
17:52 Richard going on the roof
Guardian restart seems to be completed but all the HPI have 'CODE ERROR'. Can't be cleared with LOAD or by restarting Guardian.
18:02 Joe and pest control done in all the VEAs.
18:10 Another Hanford fire dept. came to do some testing.
18:19 Jeff B. back from EX
18:27 Rick left the laser room in the "commissioning" mode
18:30 PRM, PR3 to SAFE. Put MC1 and MC3 back to SAFE.
Bubba closing GV5, GV7 for heavy crane work.
18:38 Richard back to LVEA
18:43 Rick done
18:49 Dave restarting ISC node Guardian
19:06 Dick to Electronics rack by PSL.
19:41 Dave rebooting Guardian machine
19:53 Dave done
Bubba out of the LVEA. GVs are opened.
19:54 Pest control done everywhere.
20:25 Keita and Daniel out of PSL. Going back after lunch.
20:40 Richard done for now. Put PRM, PR3, MC1 and MC3 back to ALIGNED
20:47 Let another fire dept. in.
21:03 Karen and Christina back to LVEA + open rollup door.
21:04 More fire dept. in. Joe taking them to EX and EY.
21:05 Keita's going back to the floor.
21:22 Richard going back out on the floor. Putting PR3, IM1, IM2, IM3, IM4 to SAFE
21:29 Bubba out to do more crane work.
22:39 Bubba out.
22:55 Richard done.
23:22 Let a delivery truck in And sent them back out to LSB.
23:58 Joe done escorting fire dept at VEAs.
00:00 IM3 WD tripped. After untripped there's no counts going out. Richard is working on it. Hand off to TJ