tl;dr: Alignment of IMs and RMs should be checked, then re-run an initial alignment.
Xarm green alignment
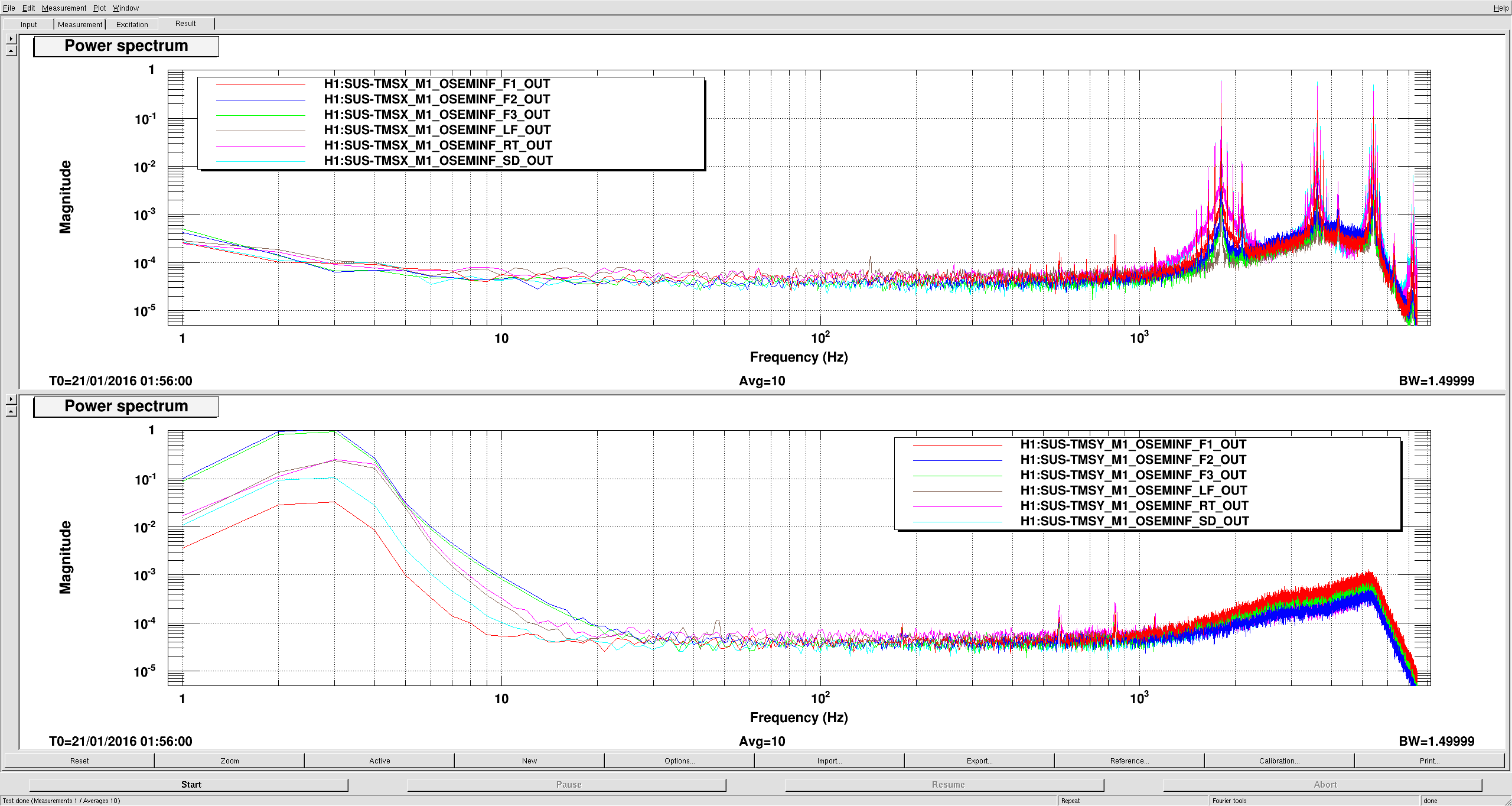
Ed was struggling with the Xarm green alignment. We set the guardian to locked no slow, no wfs. I then turned on the loops one at a time. Usually the camera centering loops are the problem, but they were the easy ones this time. Eventually it was DOF2 that was causing trouble, so I had DOFs 1 and 3 closed and touched TMS by hand to get the error signals for DOF2 closer to zero. I was able to close all the loops, and let the alignment run like normal after that.
Xarm IR alignment
Not really sure what the problem is here, but it's getting late and I'm getting frustrated, so I'm going to see if I can move on with just hand aligning the input.
I suspect that the IMs need some more attention, so if Cheryl (or someone else following Cheryl's procedures) could check on those again in the morning, that would be great.
Also, I'm not sure if the RMs got any attention today, but the DC centering servos are struggling. I've increased the limits on DC servos 1 and 2, both pitch and yaw (they used to all be 555, now they're all 2000). I also increased H1:SUS-RM2_M1_LOCK_Y_LIMIT from 1000 to 2000.
Allowing the INP ASC loops to come on is consistently causing the arm power to decay from 0.85ish to lockloss. I didn't touch the ITM or ETM, but I'm not getting any more power by adjusting PR2 or IM4.
MICH Dark not locking. Discovered that BS's M2 EUL2OSEM matrix wasn't loaded, so no signal being sent out. Hit load, MICH locked, moved on.
Bounce needed hand damping (guardian will prompt you in DARM_WFS state), roll will probably need it too. This isn't surprising, since it happens whenever the ISI for a quad optic trips. Recall that you can find the final gains (and the signs) for all of these in the ISC_LOCK guardian. I like to start with something small-ish, and increase the gain as the mode damps away. No filters need to be changed, just the gains. My starting values are in the table below, and I usually go up by factors of 2 or 3 at a time.
| (starting gain values) | Bounce | Roll |
| ETMY | +0.001 | -1 |
| ETMX | +0.001 | +1 |
| ITMX | -0.001 | +1 |
| ITMY | -0.001 | -1 |
I lost lock while damping the bounce mode (in DARM_WFS state), and the DRMI alignment is coming back much worse than the first few DRMI locks I had.
I don't actually have a lot of faith in my input beam alignment, so I probably wouldn't be happy with any ASC loop measurements I take tonight even if I got the IFO locked. Since we have an 8am meeting, I'm going to call it a night, and ask the morning operator to check my alignment and fix anything that sleepy-Jenne messed up.
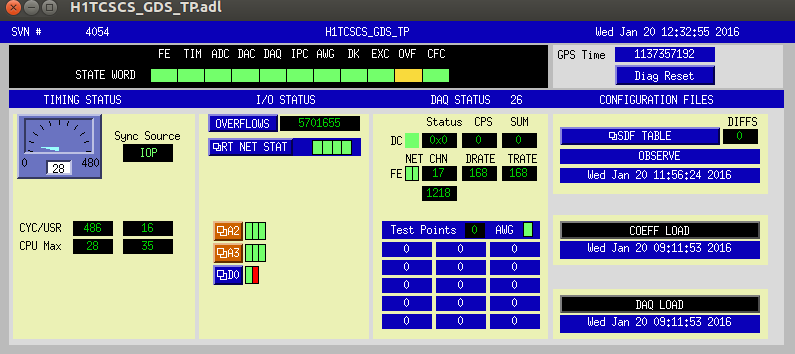
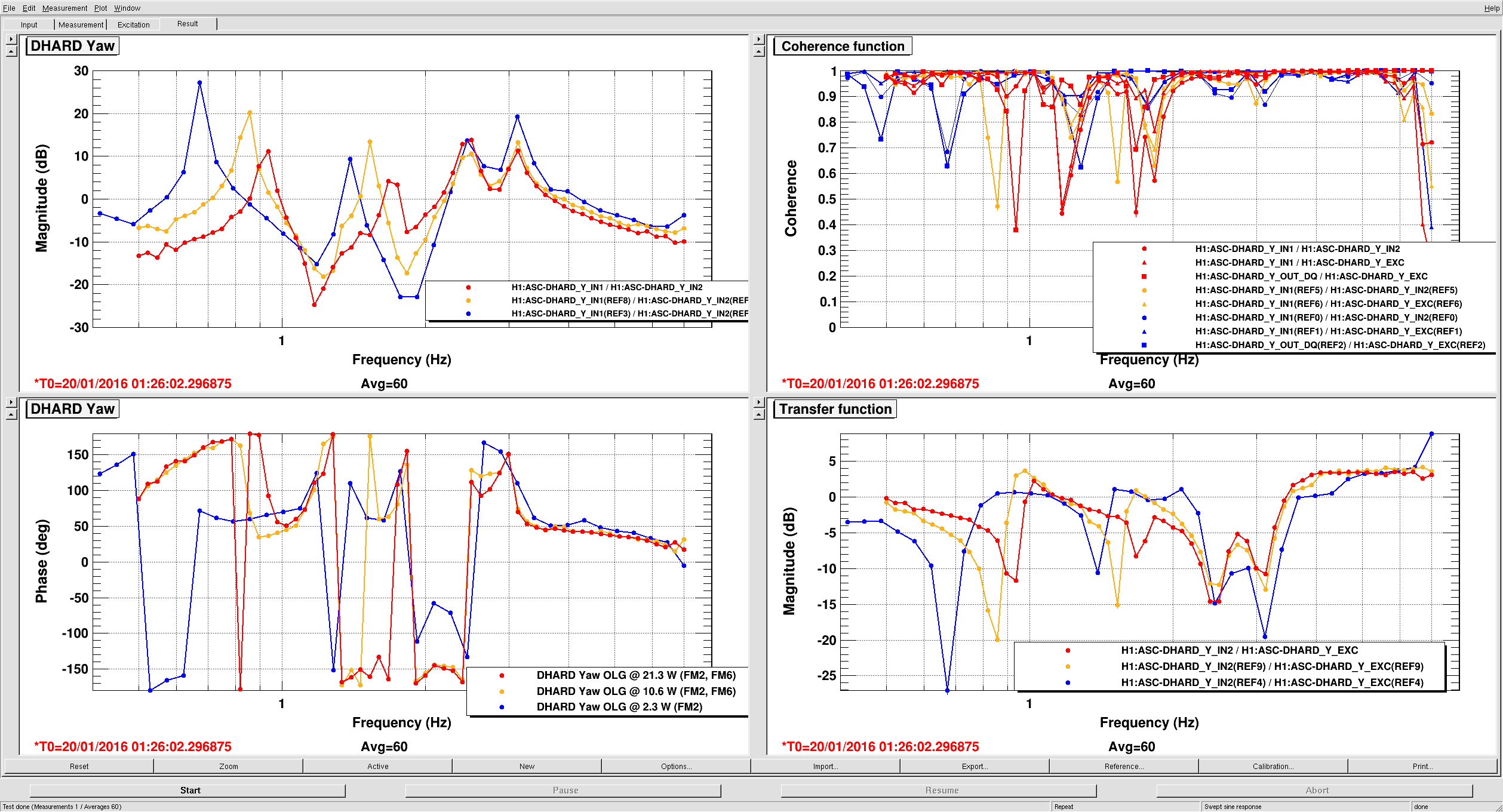
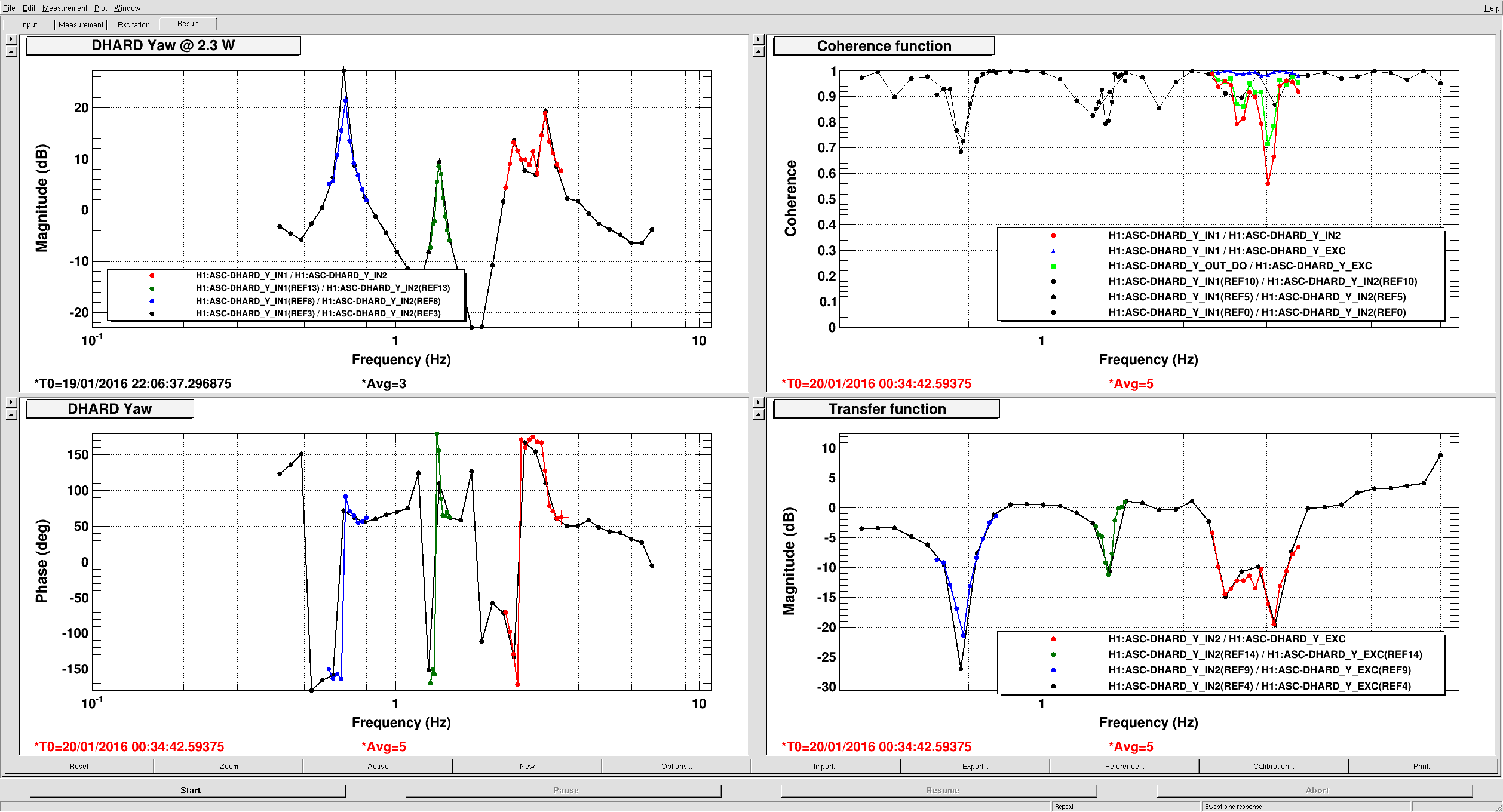


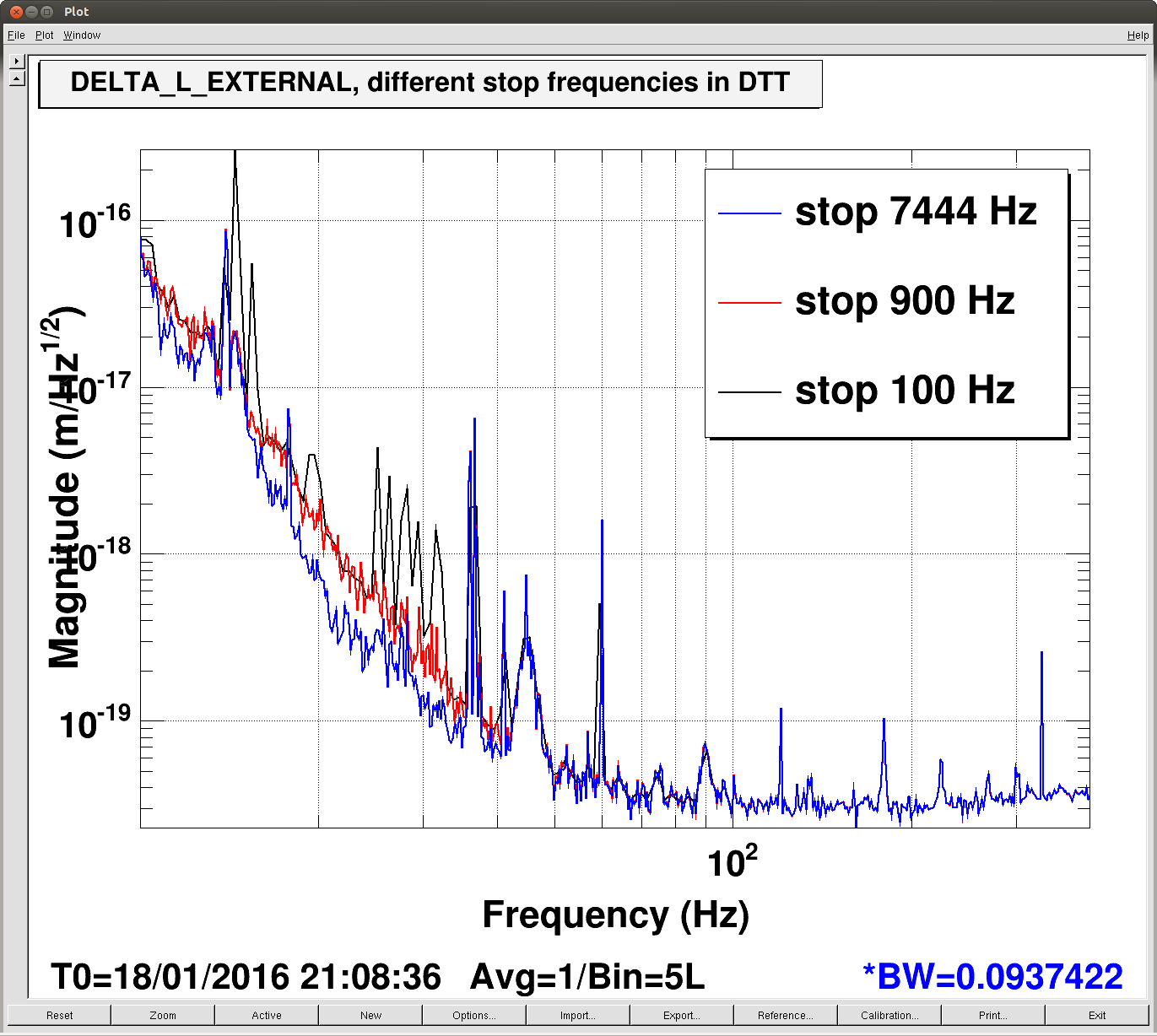
I put a quick line in the DOWN state that loads the BS EUL2OSEM matrix.