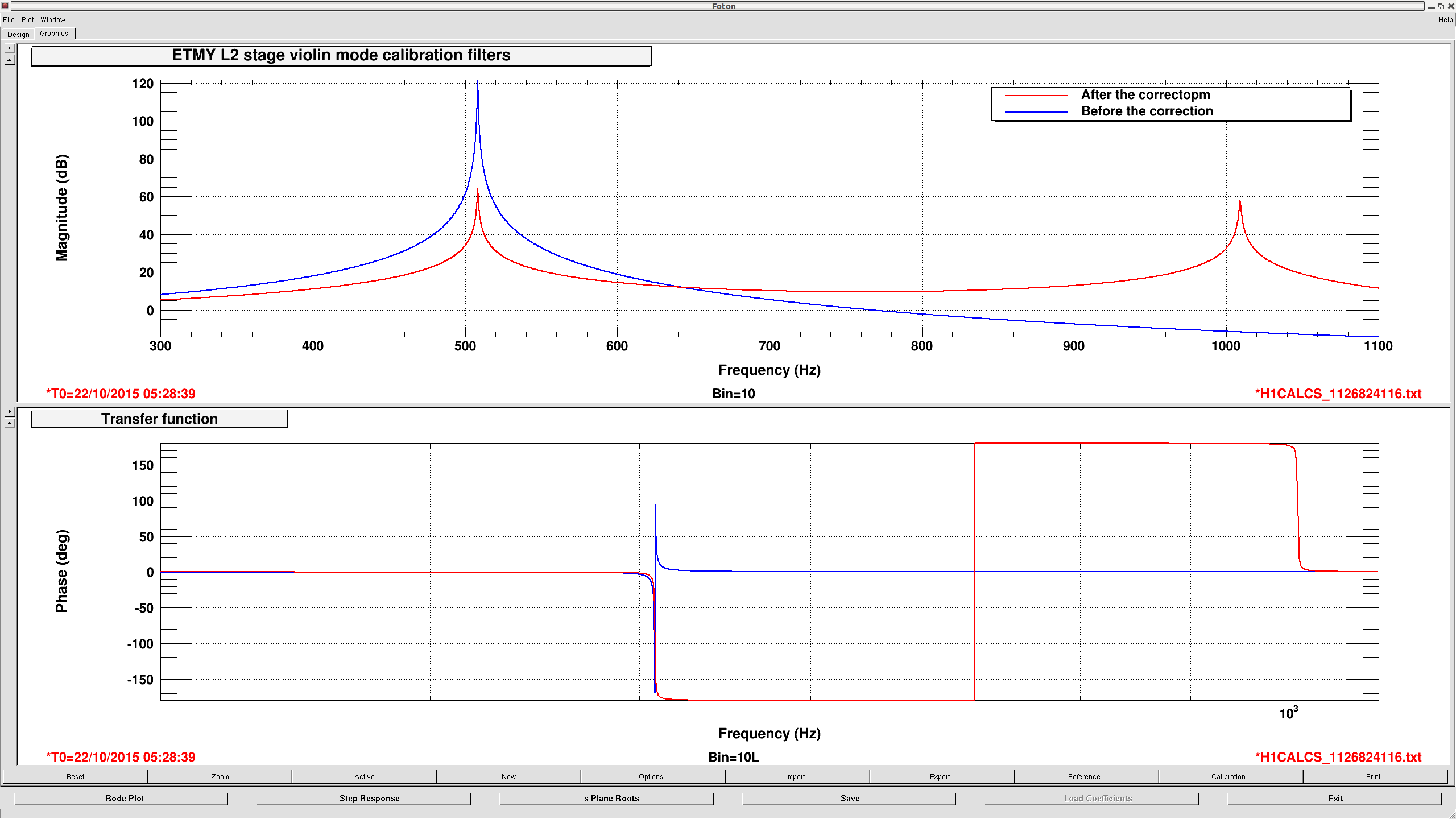
H1 SYS
(CAL, CDS, DAQ, GRD, INJ, ISC, PEM, PSL, SEI, SUS, TCS, VE)
J. Kissel, for R. McCarthy, J. Worden, G. Moreno, J. Hanks, R. Bork, C. Perez, R. Blair, K. Kawabe, P. King, J. Oberling, J. Warner, H. Radkins, N. Kijbunchoo, E. King, B. Weaver, T. Sadecki, E. Hall, P. Thomas, S. Karki, D. Moraru, G. Mendell
Well, it turns out the IFO is a complicated beast with a lot of underlying infrastructure that we rely on to even begin recovering the IFO. Since LHO so infrequently loses power, I summarize the IFO systems that are necessary before we can begin the alignment / recovery process with pointers to aLOGs and/or names of people who did the work, so that we have a global perspective on all of the worlds that need attention when all power dies. One could consider this a sort of check-list, so I've roughly prioritized the items into stages, where the items within each stage can be done in parallel if the man-power exists and/or is on-site.
Stage 1
--------------------
Facilities - Richard
Vacuum - John / Kyle / Gerardo
Stage 2
--------------------
CDS -
Work Stations - Richard
Control Room FOMs - Operators / Carlos
DC Power Supplies - Richard
Stage 3
--------------------
CDS continued
Front-Ends and I/O Chassis - Dave (LHO aLOG 22694, LHO aLOG 22704)
Timing System
Guardian Machine (comes up OK with a simple power cycle)
Beckhoff PLCs - Patrick (LHO aLOG 22671)
PSL - Peter / Jason / Keita (LHO aLOG 22667, LHO aLOG 22674, LHO aLOG 22693)
Laser
Chillers
Front Ends
TwinCAT Beckhoff (separate from the rest of the IFO's Beckhoff)
IO Rotation Stage
TCS Nutsinee / Elli (LHO aLOG 22675)
Laser
Chillers
TCS Rotation Stage (run on same Beckhoff chassis as IO Rotation Stage, and some PSL PEM stuff too)
ALS Green Lasers - Keita
The interlock for these lasers are on-top of the ISCT-Ends, and need a key turn as well as a "start" button push, so it's a definite trip to the end-station
PCAL Lasers - Sudarshan
These either survived the power outtage, don't have an interlock, or can be reset remotely. I asked Sudarshan about the health of the PCAL lasers, and he was able to confirm goodness without leaving the control room.
High-Voltage - Richard McCarthy
ESD Drivers, PZTs
HEPI Pumps and Pump Servos - Hugh (LHO aLOG 22679)
Stage 4
------------------
Cameras - Carlos
PCAL Spot-position Cameras
Green and IR cameras
SDF System - Betsy / Hugh
Changing the default start-up SAFE.snap tables to OBSERVE.snap tables (LHO aLOG 22702)
Hardware Injections - Chris Biwer / Keith Riles / Dave Barker
These have not yet been restarted
DMT / LDAS - Greg Mendell / Dan Moraru (LHO aLOG 22701)
May we have excercise this list very infrequently if at all in the future!