Adrew Lundgren has written a script that can be easily used to identify which suspensions saturate in which order in a lockloss. The script is in USERAPPS/sys/common/scripts/ and should work for LLO as well. The script is called with a time which can be either a gps time or any format that tconvert accepts, it checks for suspension MASTER_OUT_DQ channels that go above 2^17 for 10 seconds before or after the time given. This may be integrated with the summary pages and/or the graphical lockloss tool soon, but now it is ready to go from the command line. For now it is not checking things like RMs, OMs, IMs, but they can be added if anyone wants them.
Thanks to Andy for putting this together so quickly, and to Jamie, Johnathan Hanks, and Greg Mendell for helping to get it running here.
sheila.dwyer@opsws2:/opt/rtcds/userapps/release/sys/common/scripts$ lockloss list
2015-05-27 03:47:29.151290 ISC_LOCK INCREASE_POWER -> LOCKLOSS
2015-05-27 05:55:09.044630 ISC_LOCK DC_READOUT -> LOCKLOSS
2015-05-27 06:26:54.136390 ISC_LOCK DC_READOUT -> LOCKLOSS
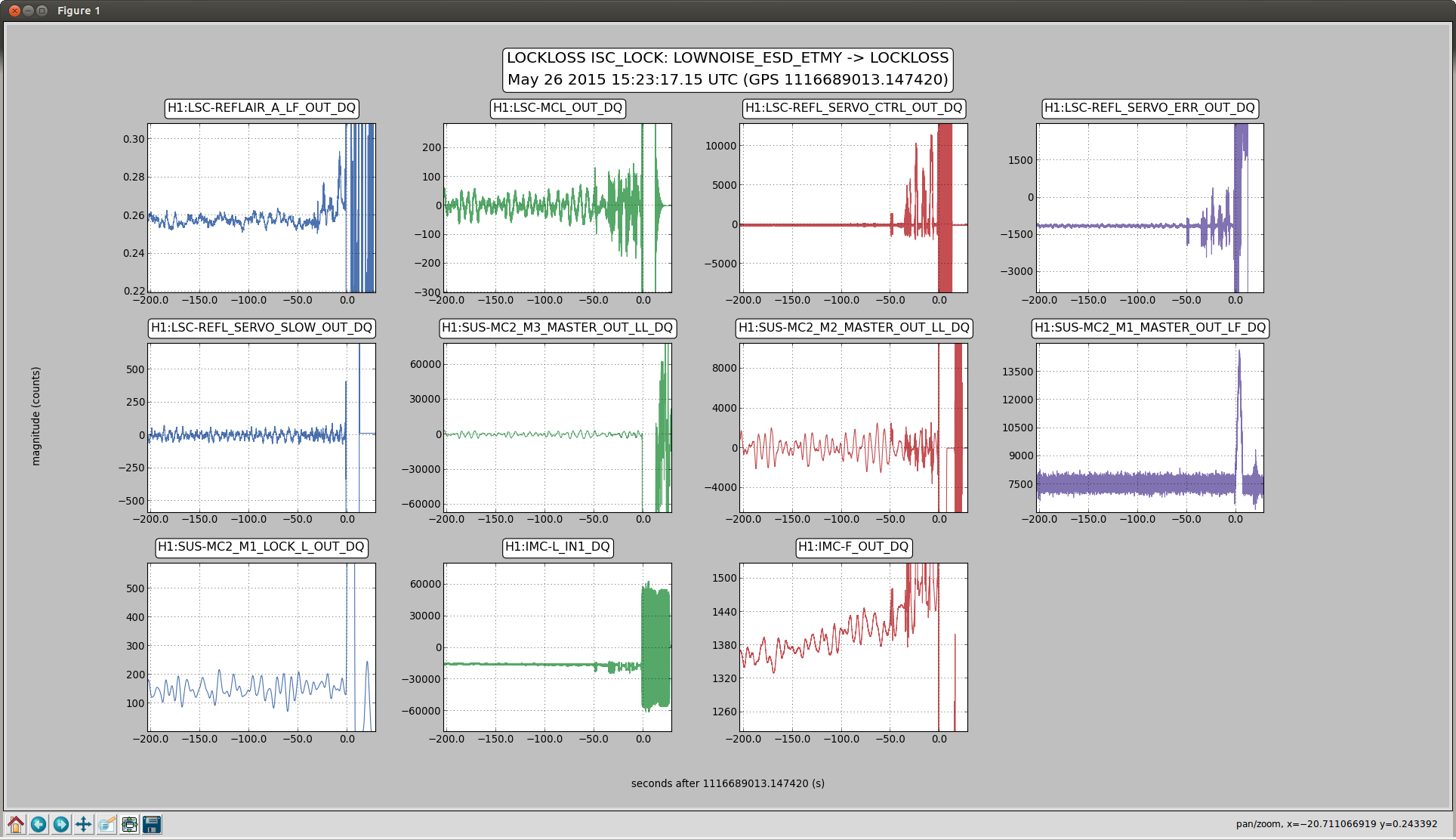
sheila.dwyer@opsws2:/opt/rtcds/userapps/release/sys/common/scripts$ ./lockloss-sus-sat 2015-05-27 06:26:54.136390
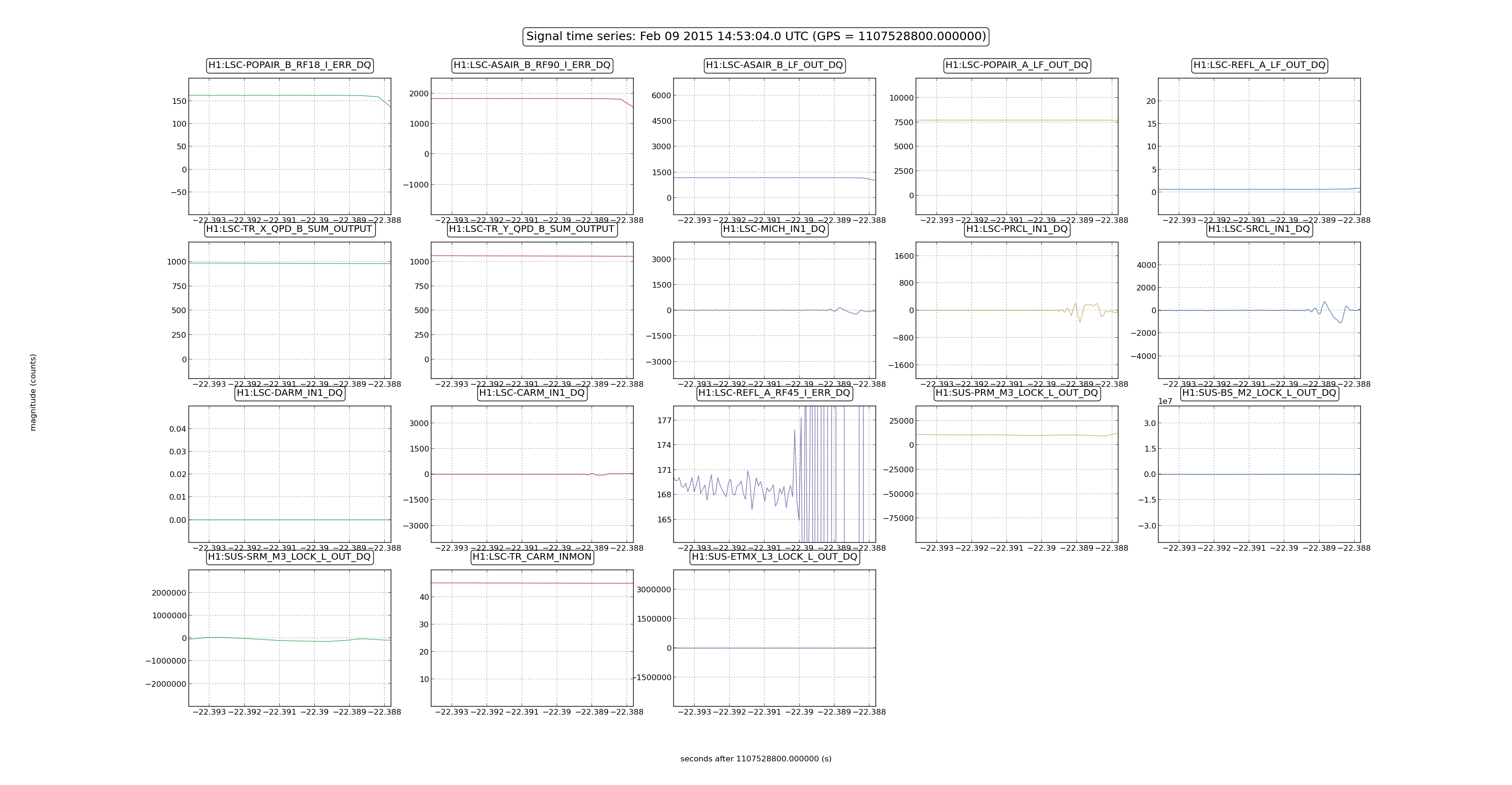
First saturation at 1116743228.92 by SRM M3 LL
SRM M3 UR saturated at +0.0015
OMC M1 LF saturated at +0.0361
OMC M1 RT saturated at +0.0361
SRM M3 LR saturated at +0.1064
SRM M3 UL saturated at +0.1528
SR2 M3 LL saturated at +0.2544
SR2 M3 UR saturated at +0.2549
SR2 M3 UL saturated at +0.2563
SR2 M3 LR saturated at +0.2563
OMC M1 T2 saturated at +0.3252
OMC M1 T3 saturated at +0.3252
ETMY L2 LL saturated at +0.3545
ETMY L2 UL saturated at +0.3560
ETMY L2 LR saturated at +0.3579
ETMY L2 UR saturated at +0.3706
ETMY L3 UL saturated at +0.3730
ETMY L3 UR saturated at +0.3730
ETMY L3 LL saturated at +0.3730
ETMY L3 LR saturated at +0.3730
MC2 M3 UL saturated at +0.4136
MC2 M3 UR saturated at +0.4185
MC2 M3 LL saturated at +0.4375
MC2 M3 LR saturated at +0.4424
SR2 M1 T2 saturated at +1.2725
SR2 M1 T3 saturated at +1.2725
ETMX L1 LR saturated at +1.2959
ETMX L1 LL saturated at +1.2969
ETMX L1 UR saturated at +1.3232
ETMX L1 UL saturated at +1.3242
ETMY L1 LL saturated at +1.5869
ETMY L1 LR saturated at +1.6074
ETMY L1 UL saturated at +1.6123
ETMY L1 UR saturated at +1.6318
PRM M3 UR saturated at +2.5864
PRM M3 UL saturated at +2.6104
PRM M3 LR saturated at +3.2441
PRM M3 LL saturated at +3.2832
PRM M2 LR saturated at +3.6689
PRM M2 LL saturated at +3.7305
PRM M2 UR saturated at +3.7900
PRM M2 UL saturated at +3.8564




{kind=link}