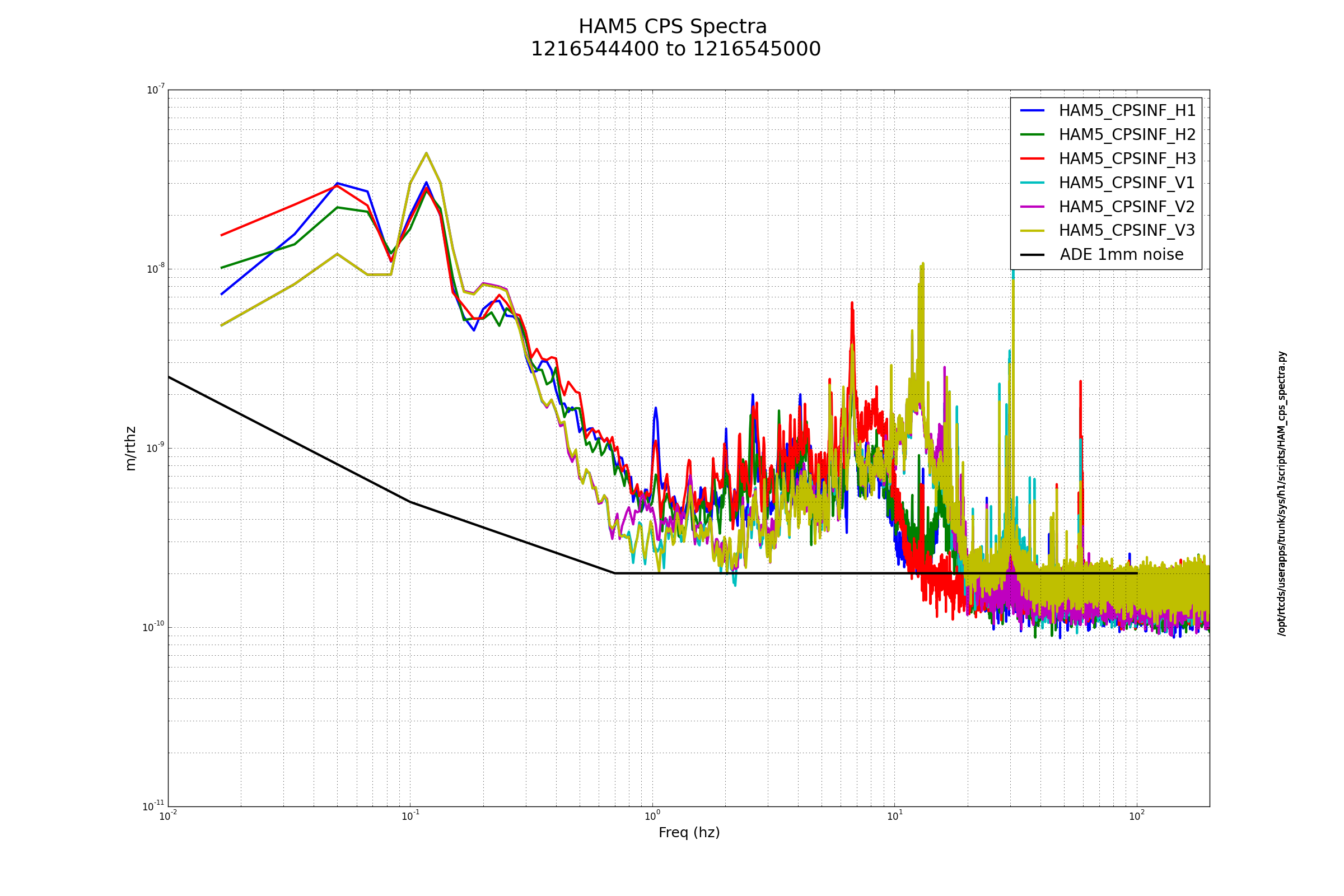
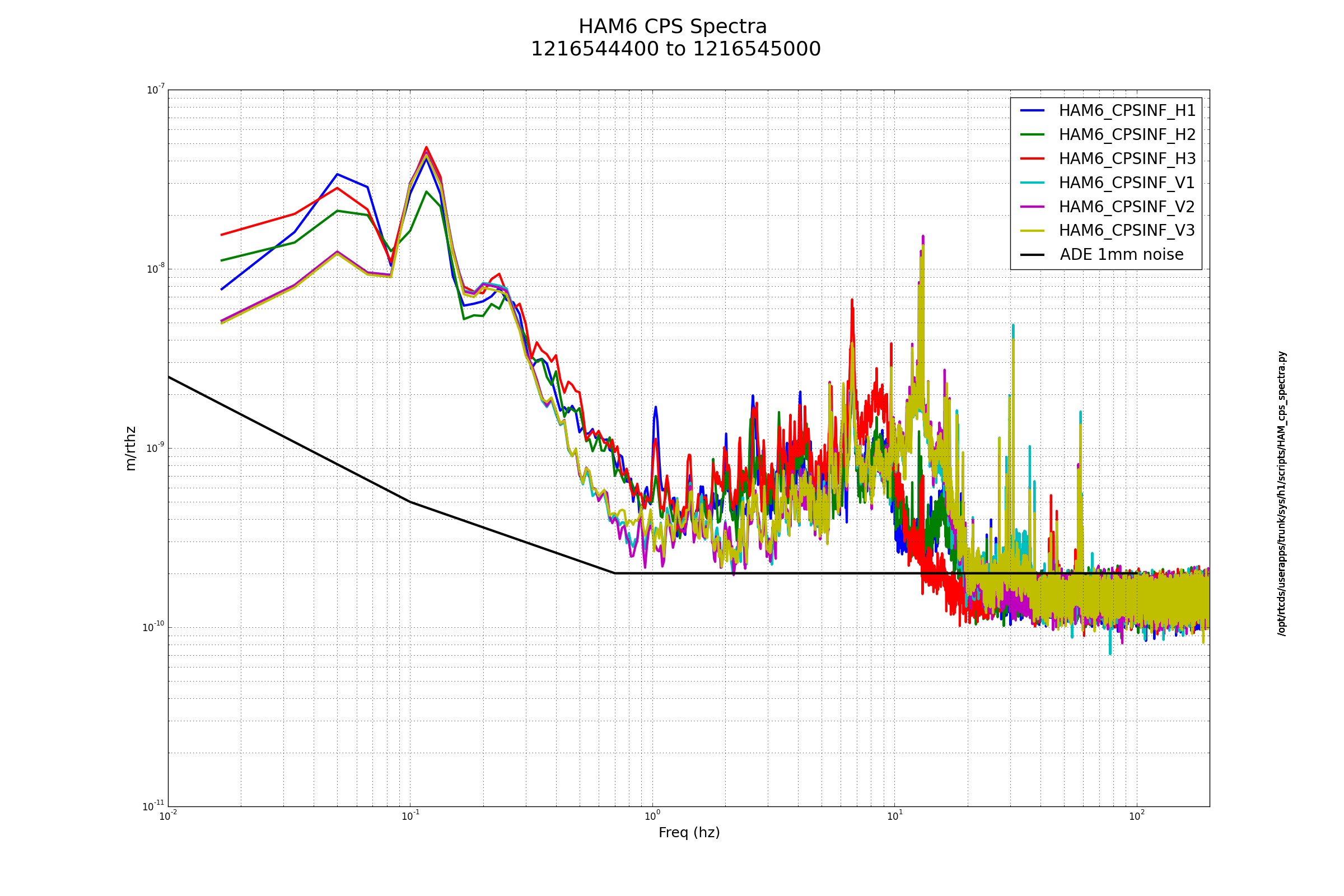
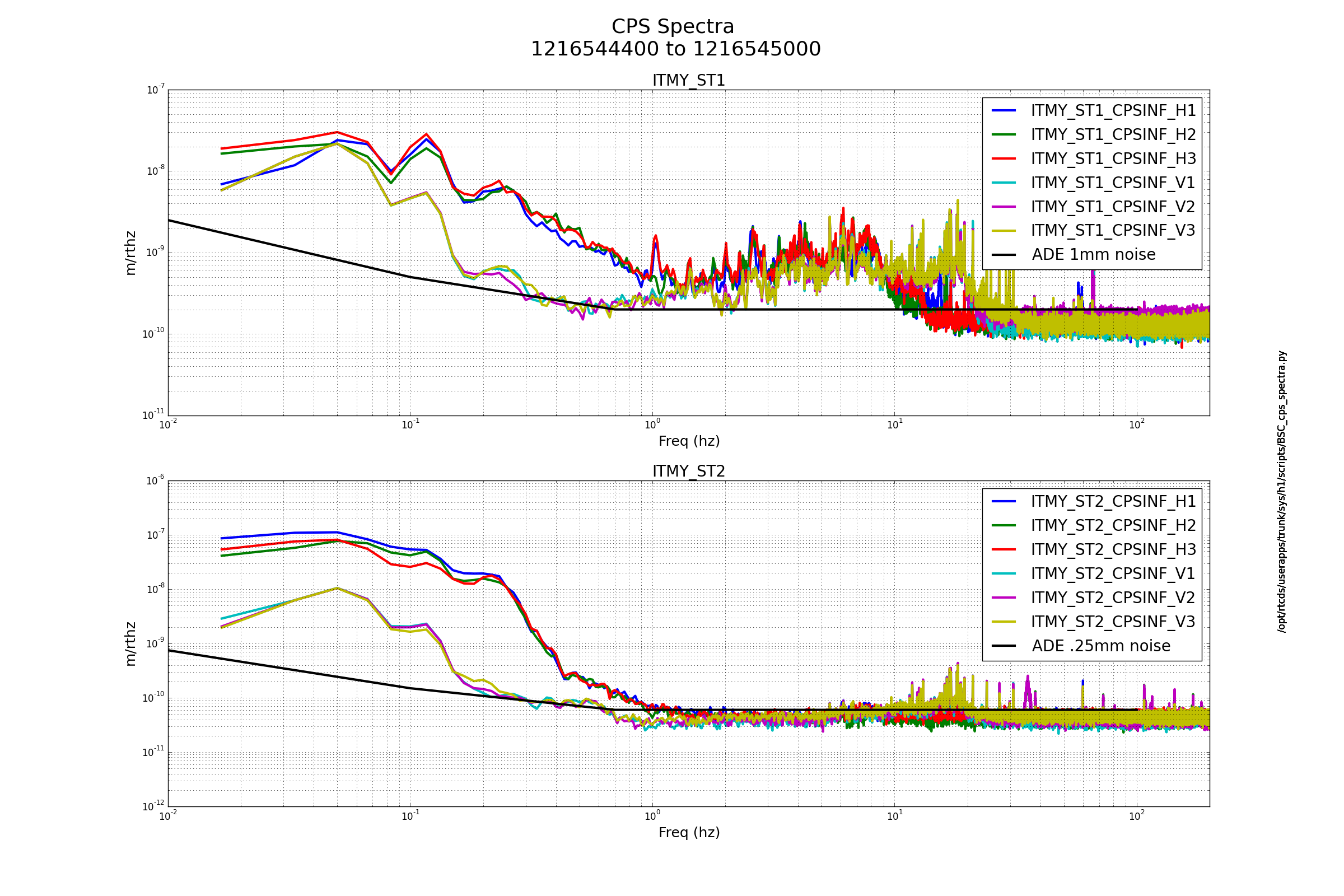
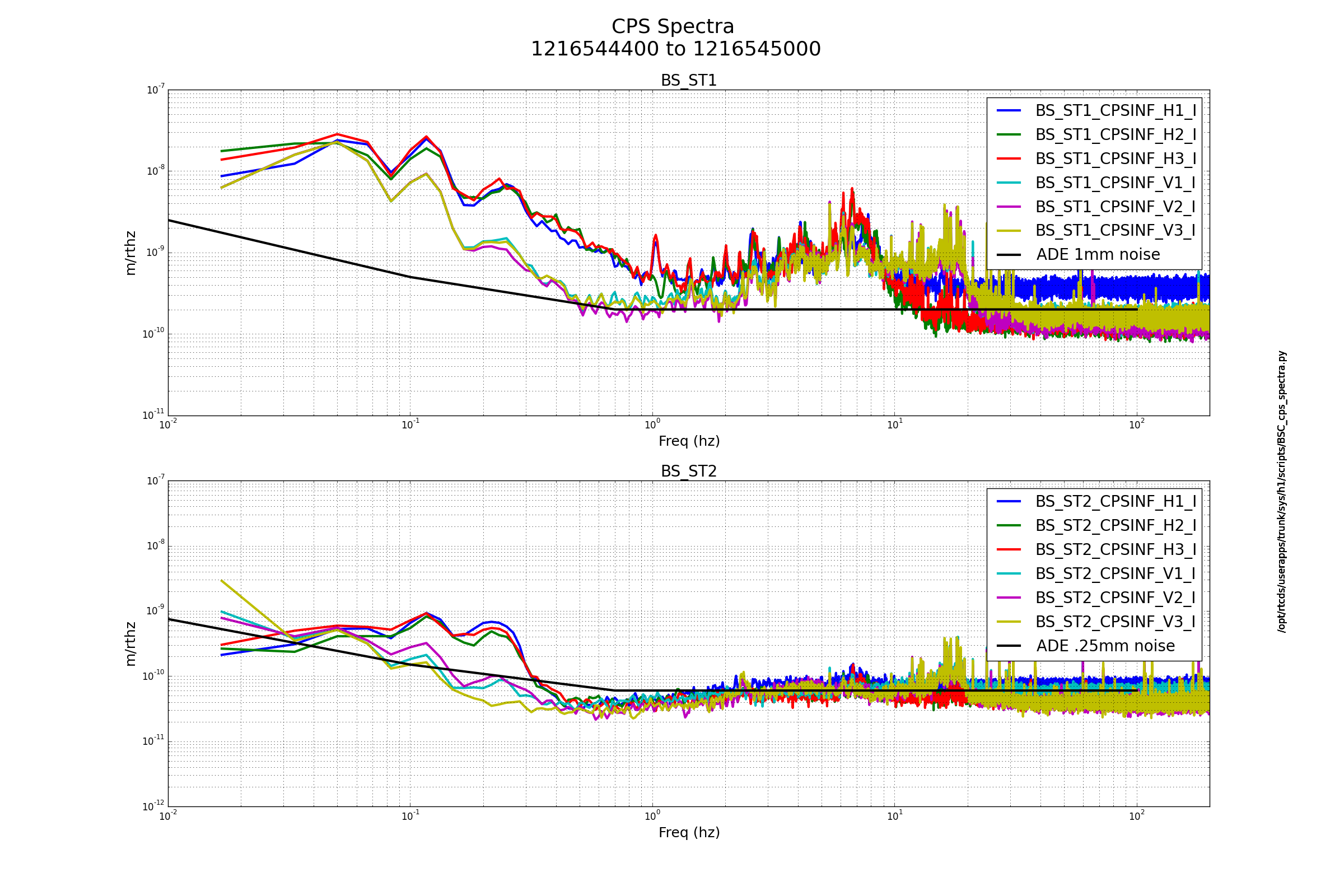
Sheila, Craig
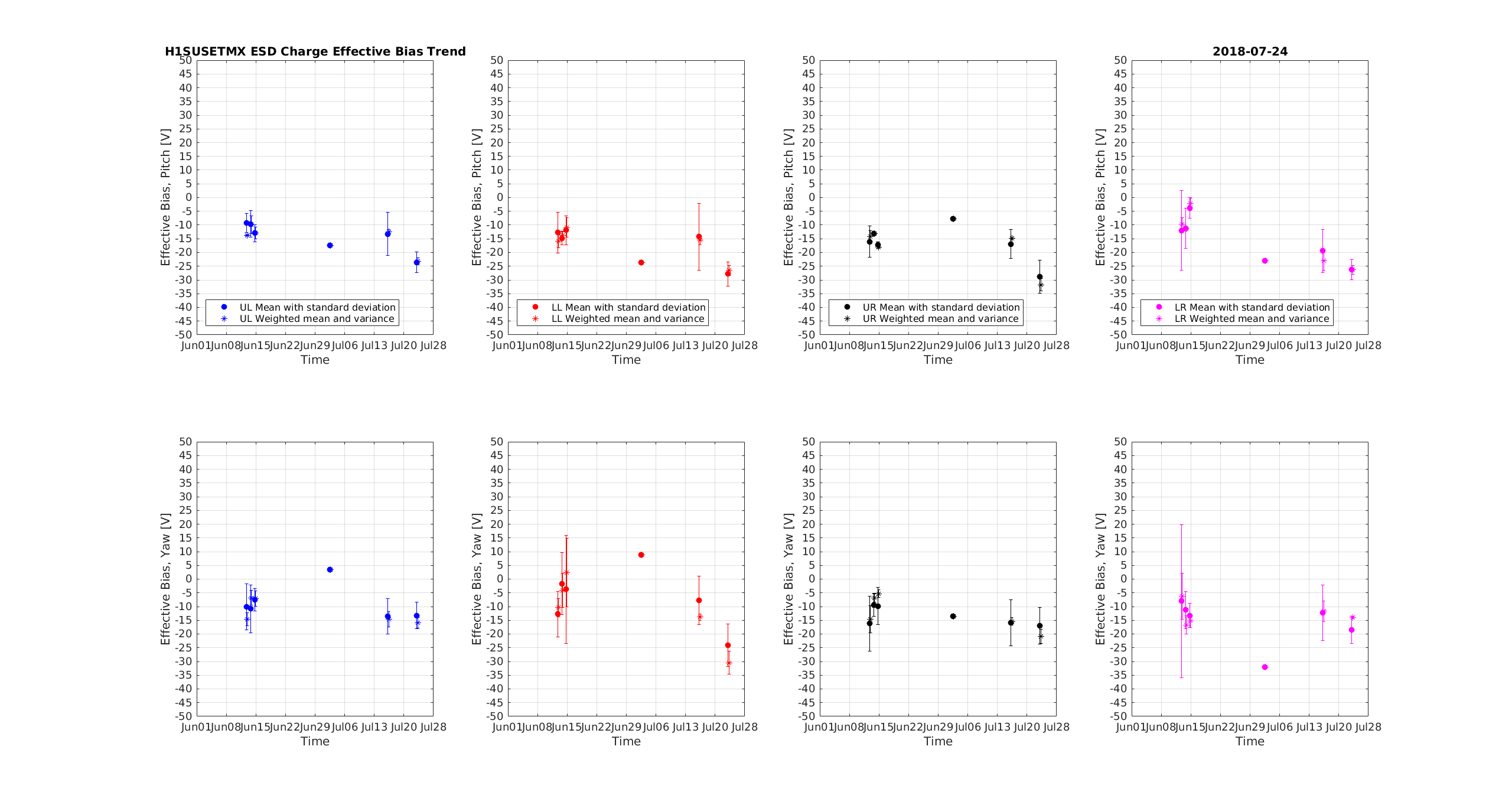
Sheila asked me to look at all our POP PDs during PRMI locks now (GPS=1216359318) and on June 21 (GPS=1213724178) for checking if the ASC and LSC POP PDs saw different relative levels of light.
If the LSC POP PDs saw less light now, we would have smoking gun for clipping in the LSC_POPAIR path, since the LSC POP PDs monitor light returning from the beamsplitter.
ASC and LSC POP PDs have the same relative amount of light on them now as in June.
Results
Below are the results of the comparison. The first column of numbers are associated with the June 21 PRMI lock, and the second is PRMI from two days ago. The third column is the raw ratio of the PDs, and the fourth is normalized for the input power as read by IM4 trans.
Channel Name PRMI Locked Time 1, PRMI Locked Time 2, Ratio Time 2/Time 1, Power Normed Ratio
GPSTimes 1213724178 1216359318
H1:IMC-IM4_TRANS_SUM_OUT_DQ 284.918762207, 67.9162597656, 0.238370612264, 1.0
H1:IMC-IM4_TRANS_PIT_OUT_DQ 0.407760709524, 0.477381646633, 1.17073965073, 4.91142606735
H1:IMC-IM4_TRANS_YAW_OUT_DQ 0.883432805538, 0.855117201805, 0.967948198318, 4.06068611145
H1:LSC-POPAIR_B_RF18_I_ERR_DQ 195.512329102, 16.1139144897, 0.0824189186096, 0.345759570599
H1:LSC-POPAIR_B_RF18_Q_ERR_DQ -94.1860046387, -3.70564484596, 0.0393439009786, 0.165053486824
H1:LSC-POPAIR_B_RF90_I_ERR_DQ 286.353973389, 44.0622596741, 0.1538733989, 0.645521700382
H1:LSC-POPAIR_B_RF90_Q_ERR_DQ -75.2995452881, 2.58768701553, -0.0343652404845, -0.144167274237
H1:LSC-POPAIR_B_LF_OUT_DQ 24.9877510071, 2.98662781715, 0.11952367425, 0.501419484615
H1:LSC-POP_A_LF_OUT_DQ 242.602081299, 29.790473938, 0.122795626521, 0.515145838261
H1:ASC-POP_A_NSUM_OUT_DQ 11.5149688721, 1.42900109291, 0.124099433422, 0.520615518093
H1:ASC-POP_A_PIT_OUT_DQ 0.29082262516, 0.965587258339, 3.32019305229, 13.9287014008
H1:ASC-POP_A_YAW_OUT_DQ 0.0495703965425, 0.11970166862, 2.41478133202, 10.1303653717
H1:ASC-POP_B_NSUM_OUT_DQ 10.5879678726, 1.31313991547, 0.12402190268, 0.520290255547
H1:ASC-POP_B_PIT_OUT_DQ 0.952069103718, 0.95118021965, 0.999066352844, 4.19123125076
H1:ASC-POP_B_YAW_OUT_DQ -0.530693173409, -0.561689078808, 1.05840647221, 4.4401717186
Buildups in RF9 are one third of what they were in June, while buildups in RF45 are two thirds of what they were. Overall power is half. All PD power levels are consistent.
POP_A seems way off in both pitch and yaw, but POP_B is the same.
I checked every PD for differences in the signal chain. There were none except for POPAIR_B_RF18_PHASE_R going from 12.0 to 42.0 degrees, and POPAIR_B_RF90_PHASE_R changing from 24.0 to 49.0 degrees.
Sanity Check
We can estimate what the PRMI POPAIR_B_LF power ratio should be from the new modulation depths and our POPAIR_B sidebands:
^2 P_9 + 2 J_1(Gamma_{45})^2 P_{45})_2}{(2 J_1(Gamma_9)^2 P_9 + 2 J_1(Gamma_{45})^2 P_{45})_1} dfrac{P_mathrm{in1}}{P_mathrm{in2}} approx 0.52)