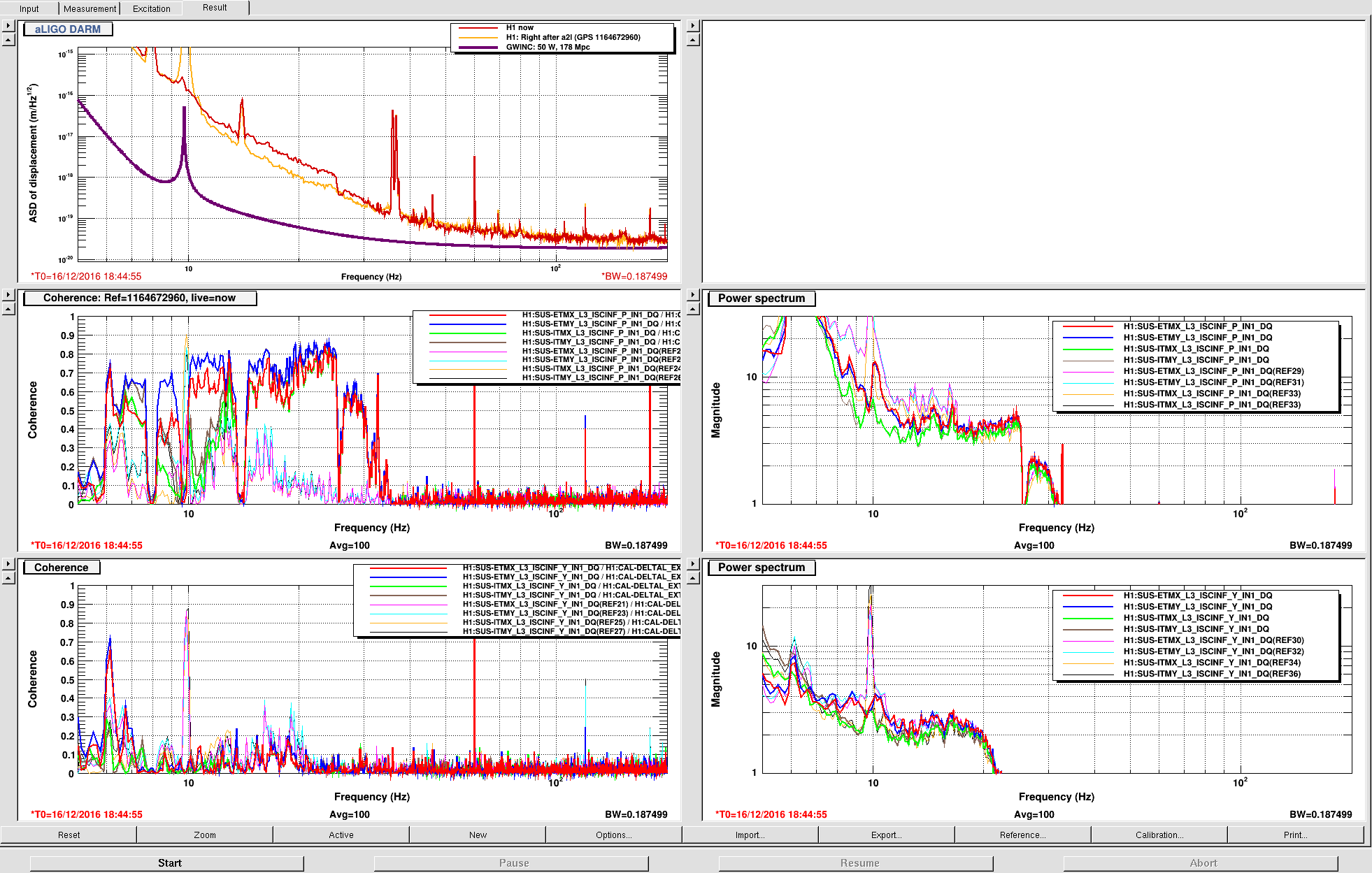
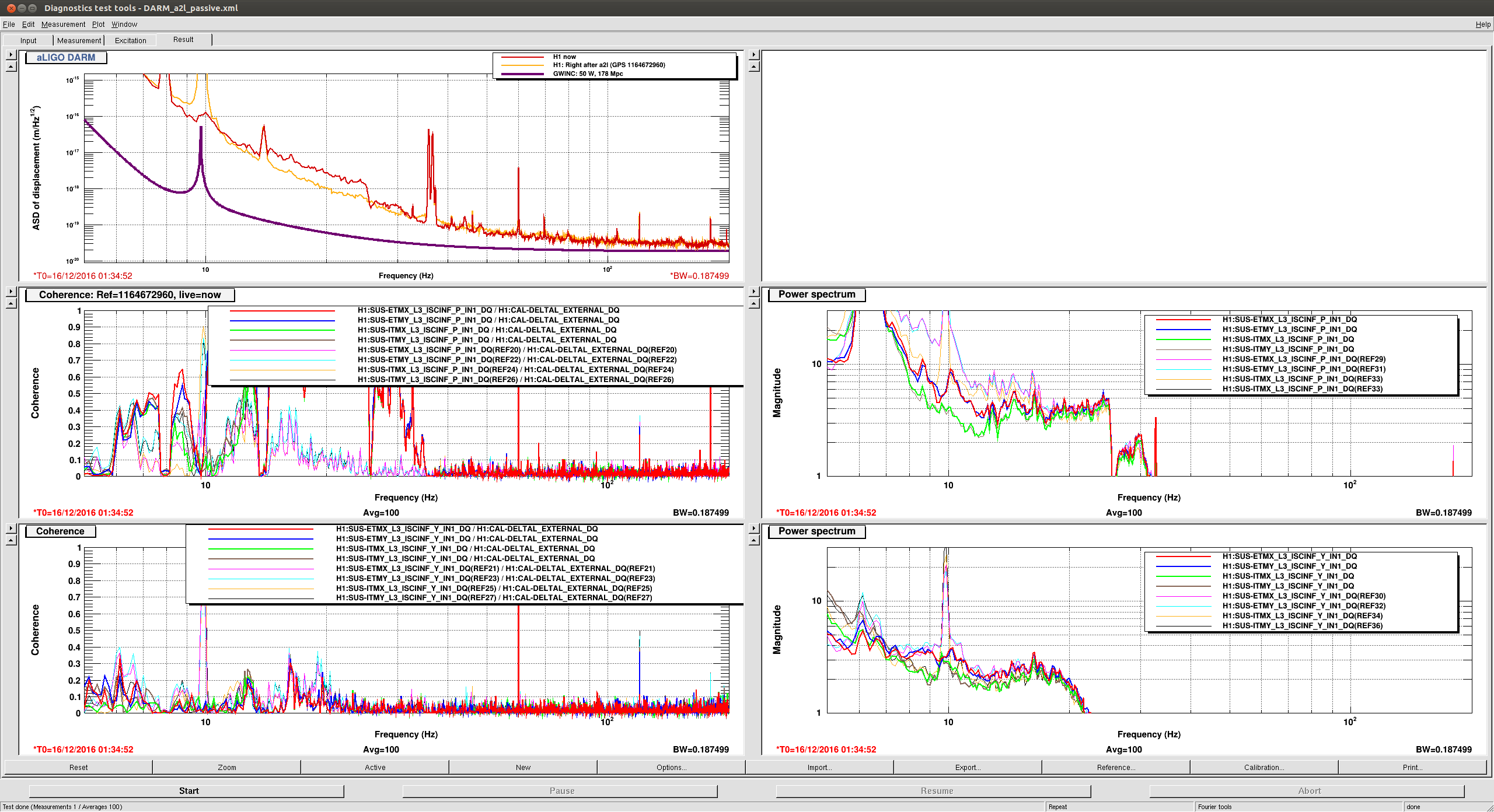
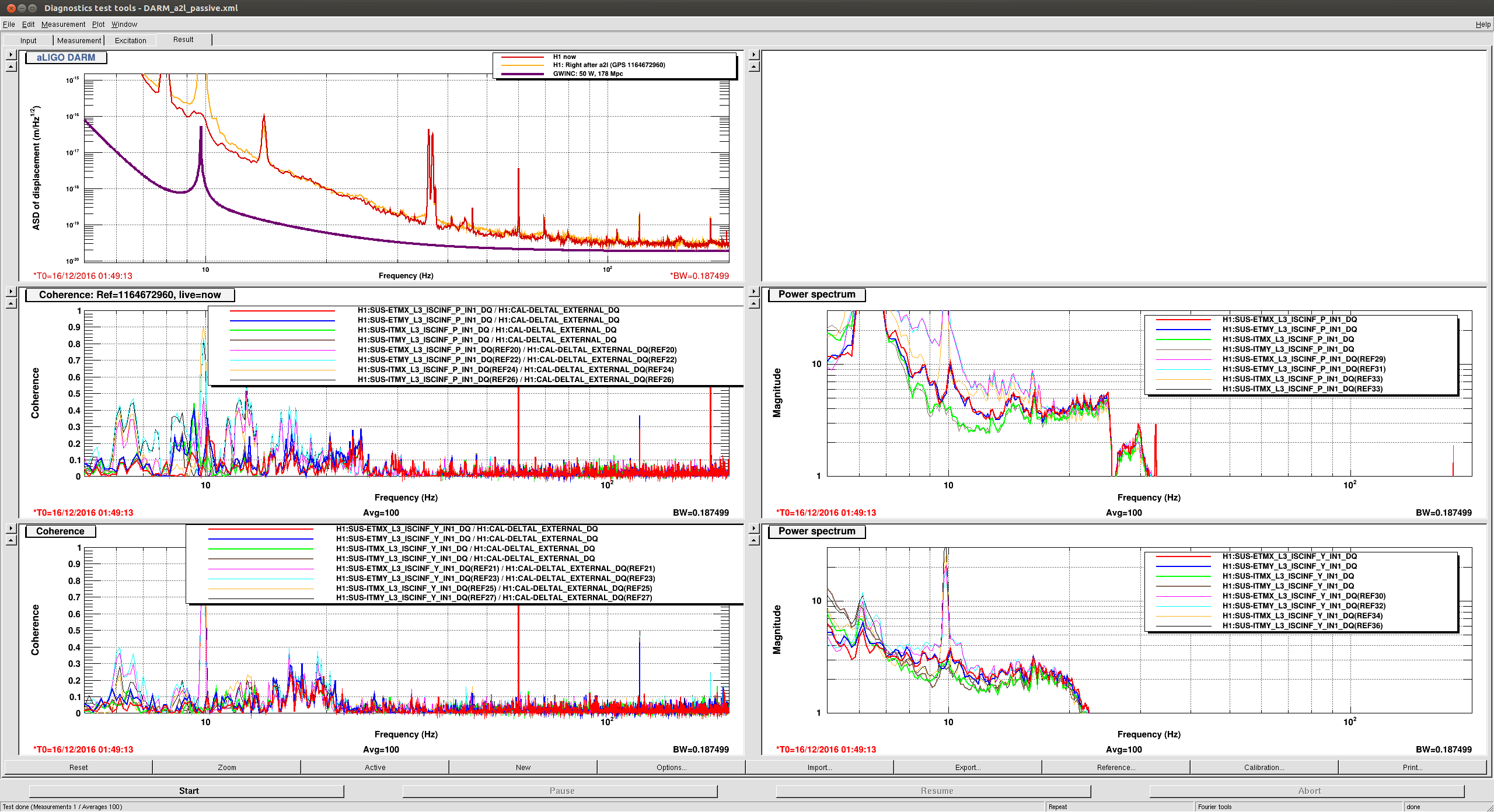
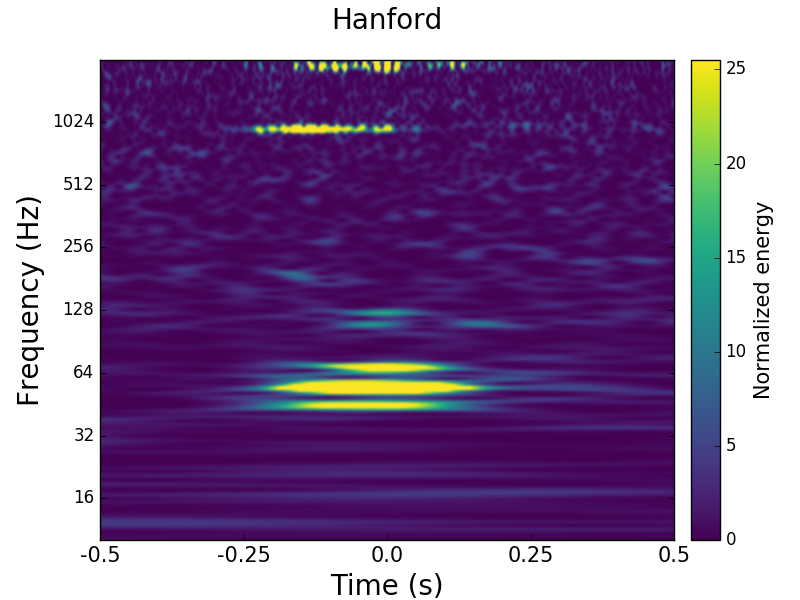
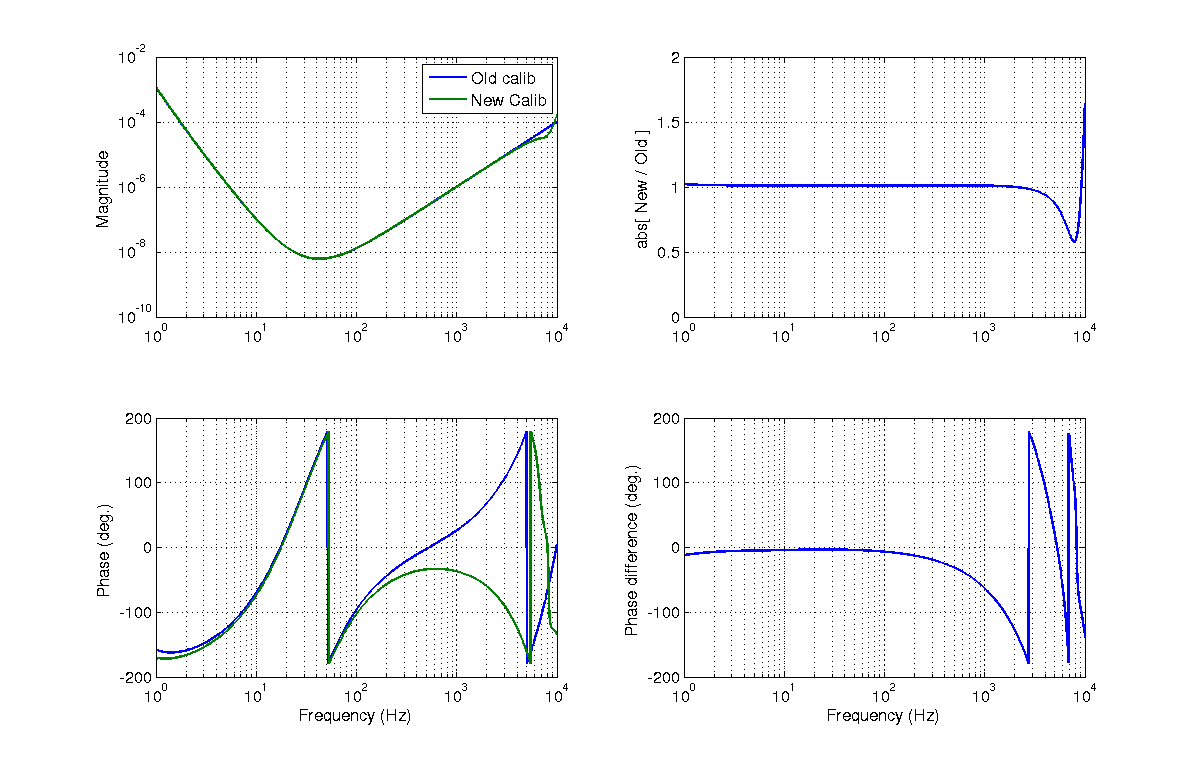
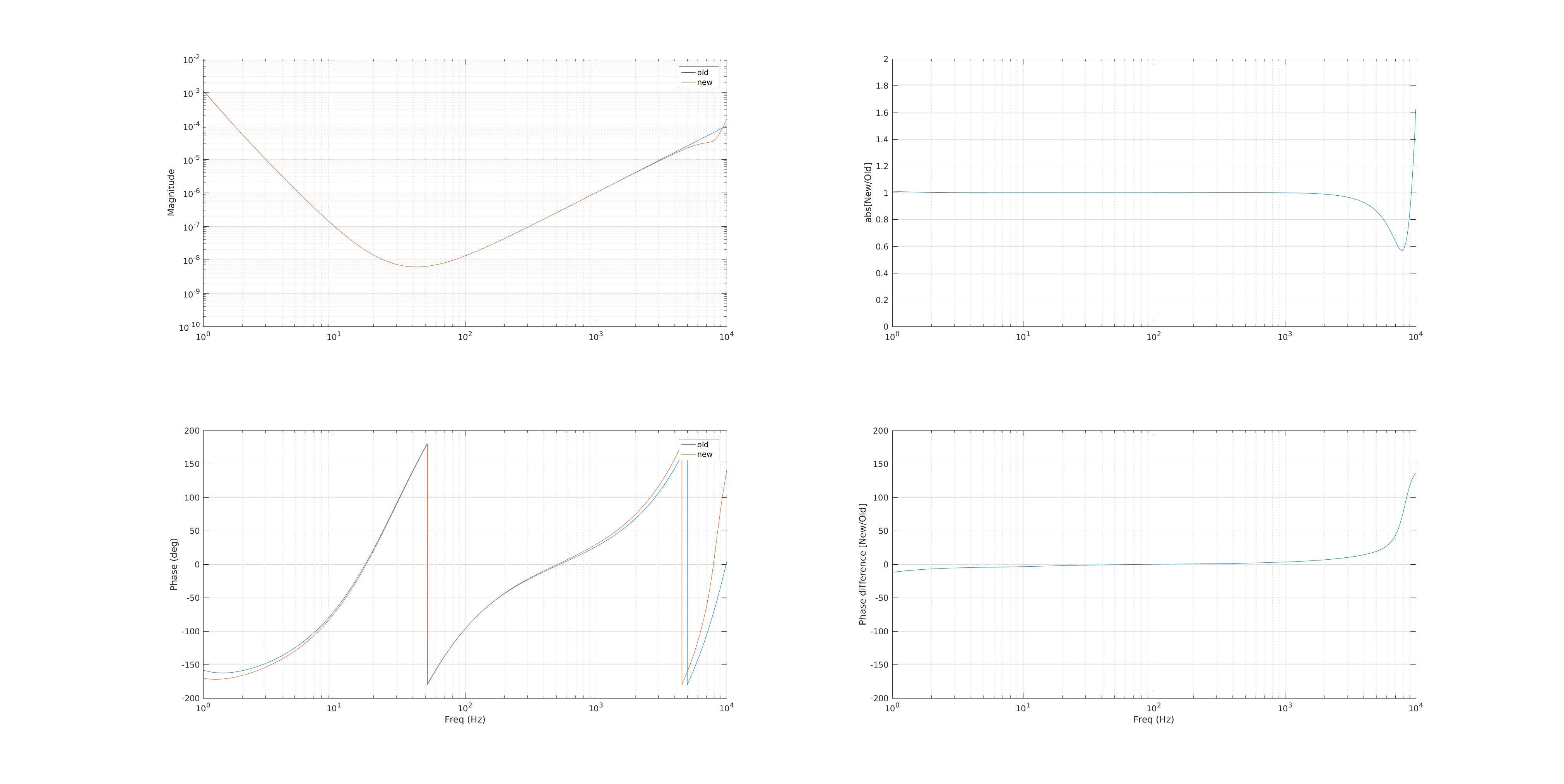
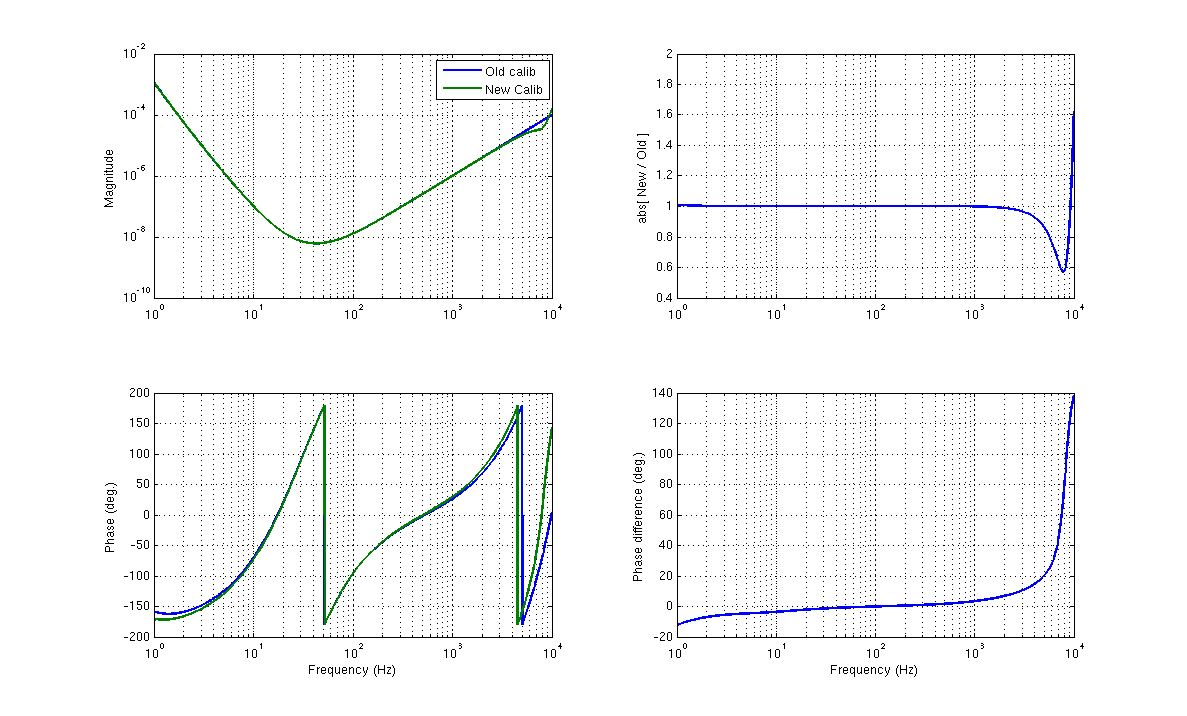
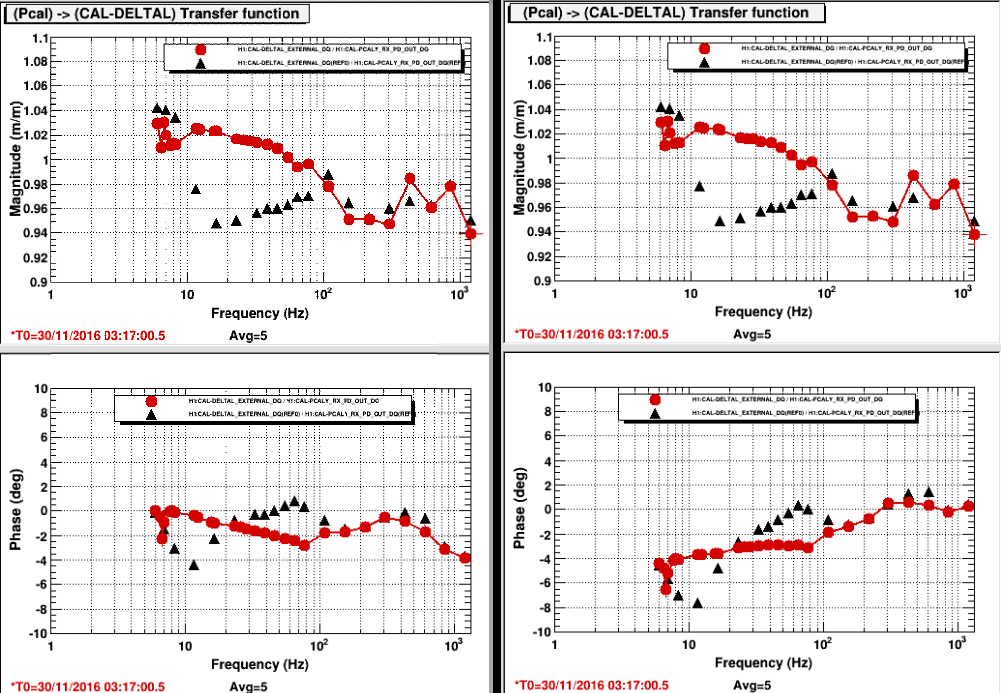
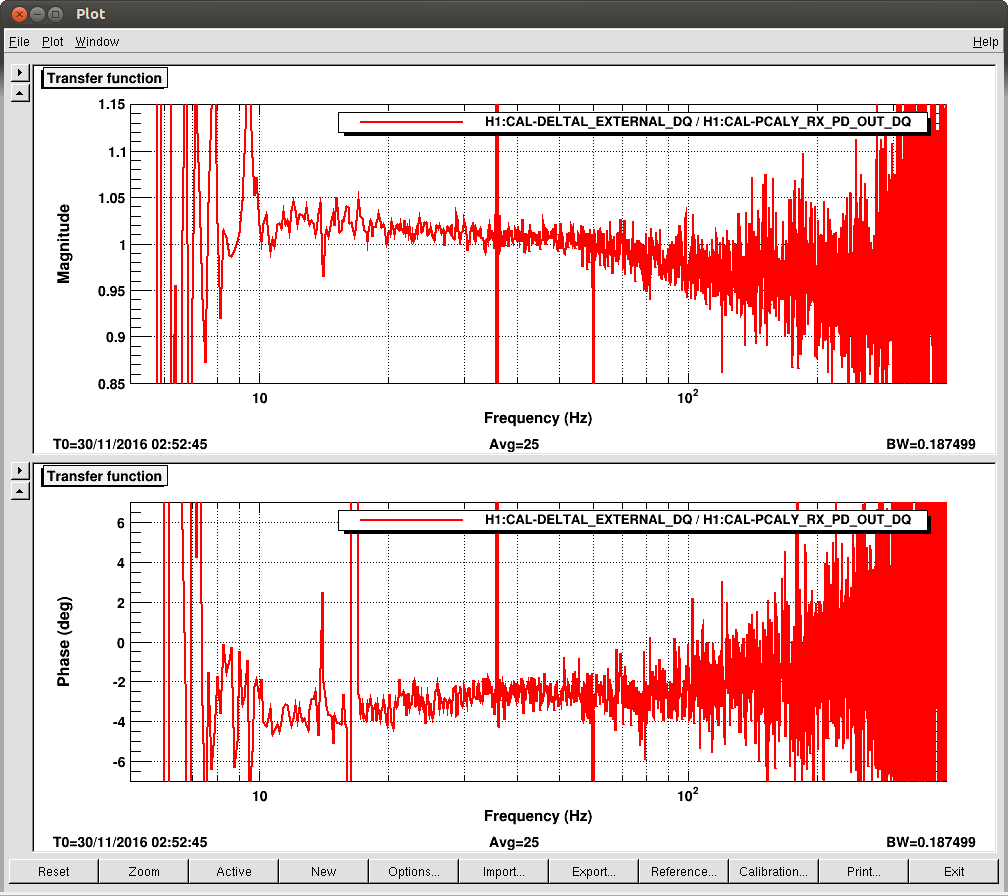
chandra.romel@LIGO.ORG - posted 15:52, Friday 16 December 2016 (32639)
CP3 & CP4 overfill with cron job
3pm local
Patrick, Kyle, Dave, Chandra
Successfully filled CP3 and CP4 using automation code and executing code via cron job. We lifted leads of both TCs on CP3 to mimic faults to verfiy code aborts. We tried to increase exhaust pressure to >2 psig threshhold by closing bypass exhaust valve but due to cold exhaust pipes it never rose above 1 psig. We even cracked the bypass LLCV half turn on CP4 along with doubling LLCV % open. We'll revisit that error test.
CP3 took about 30 seconds to overfill at 50% open.
CP4 took several minutes to overfill at 70% open and 1/2 turn open on bypass LLCV. Raised nominal from 35% to 36%.
Next week we'll test alert messaging.