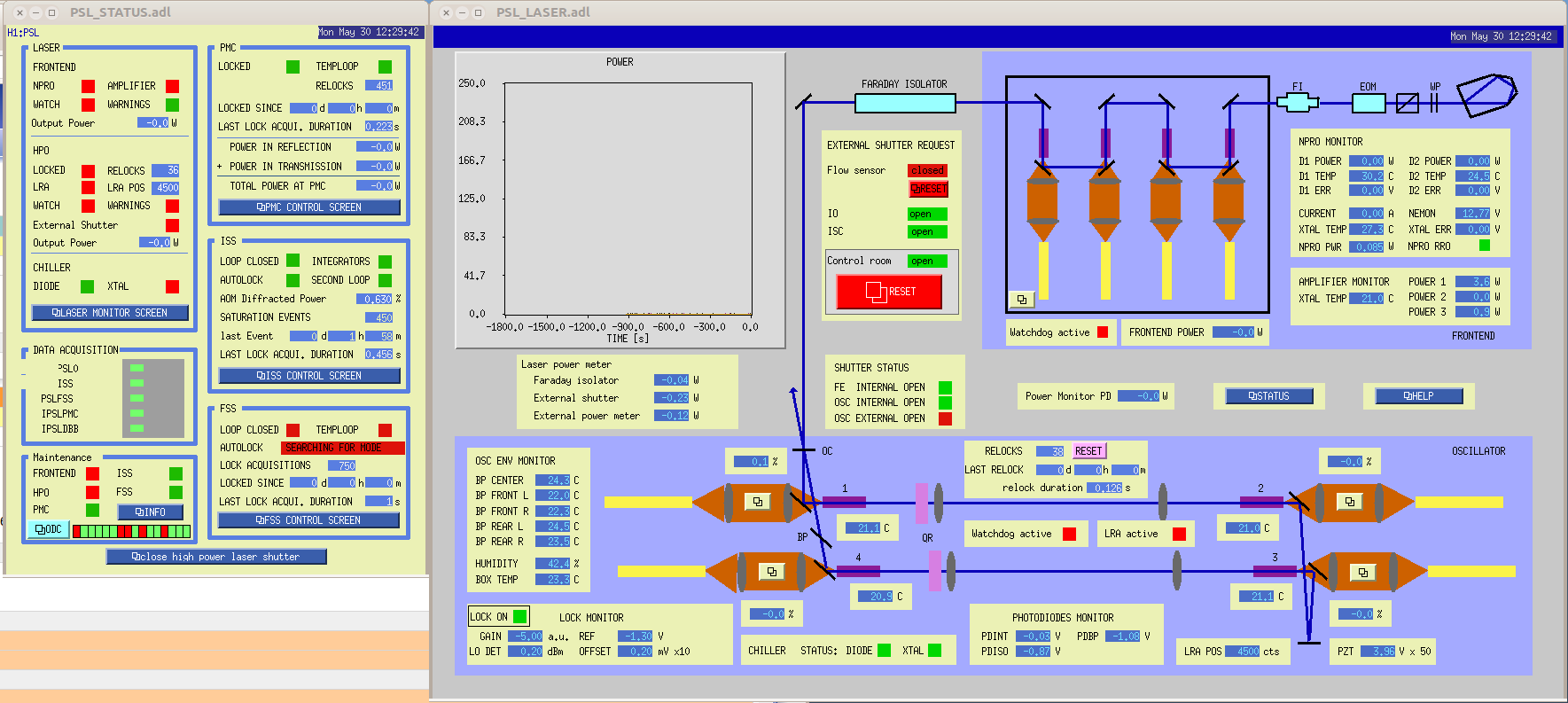
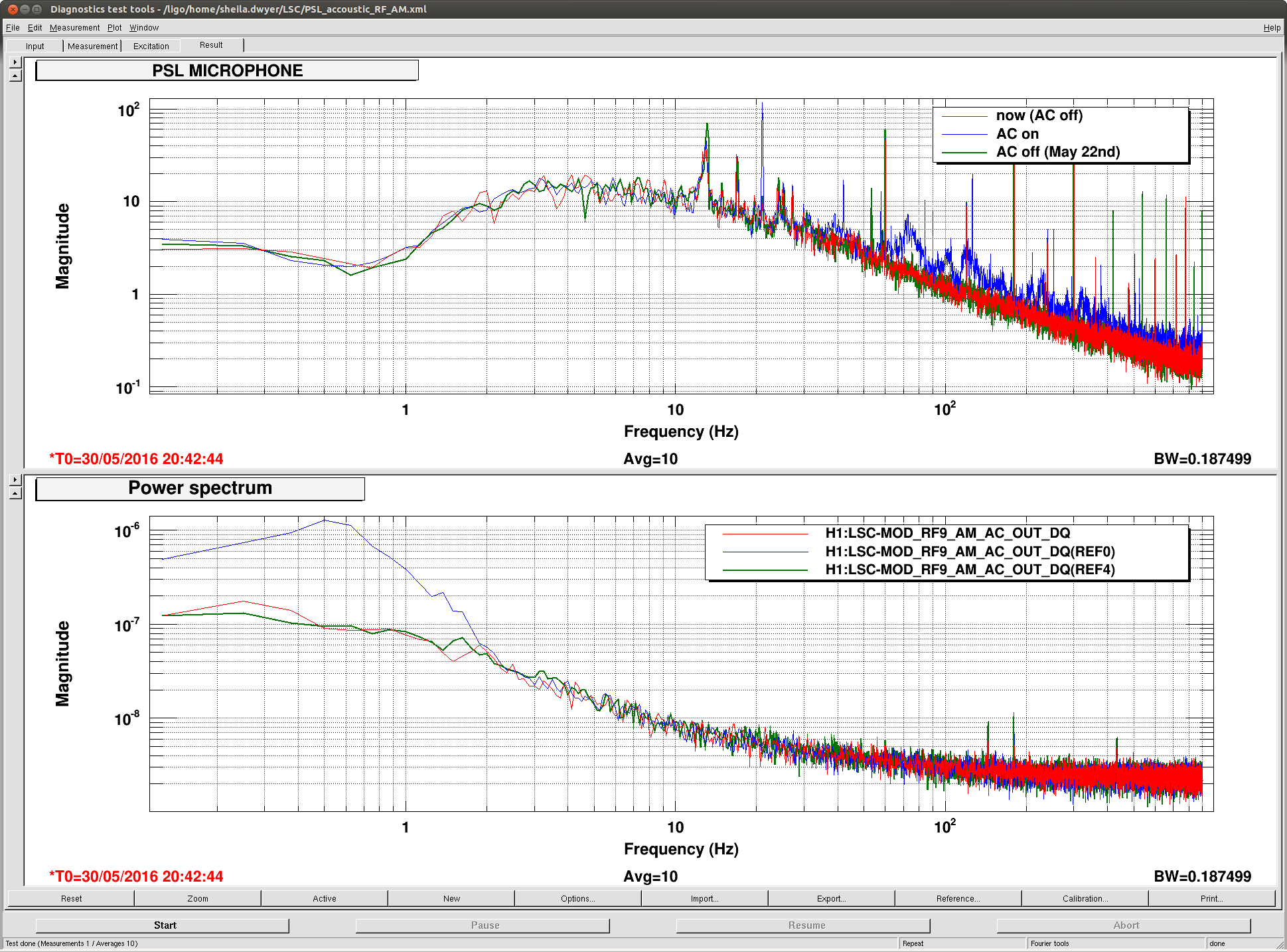
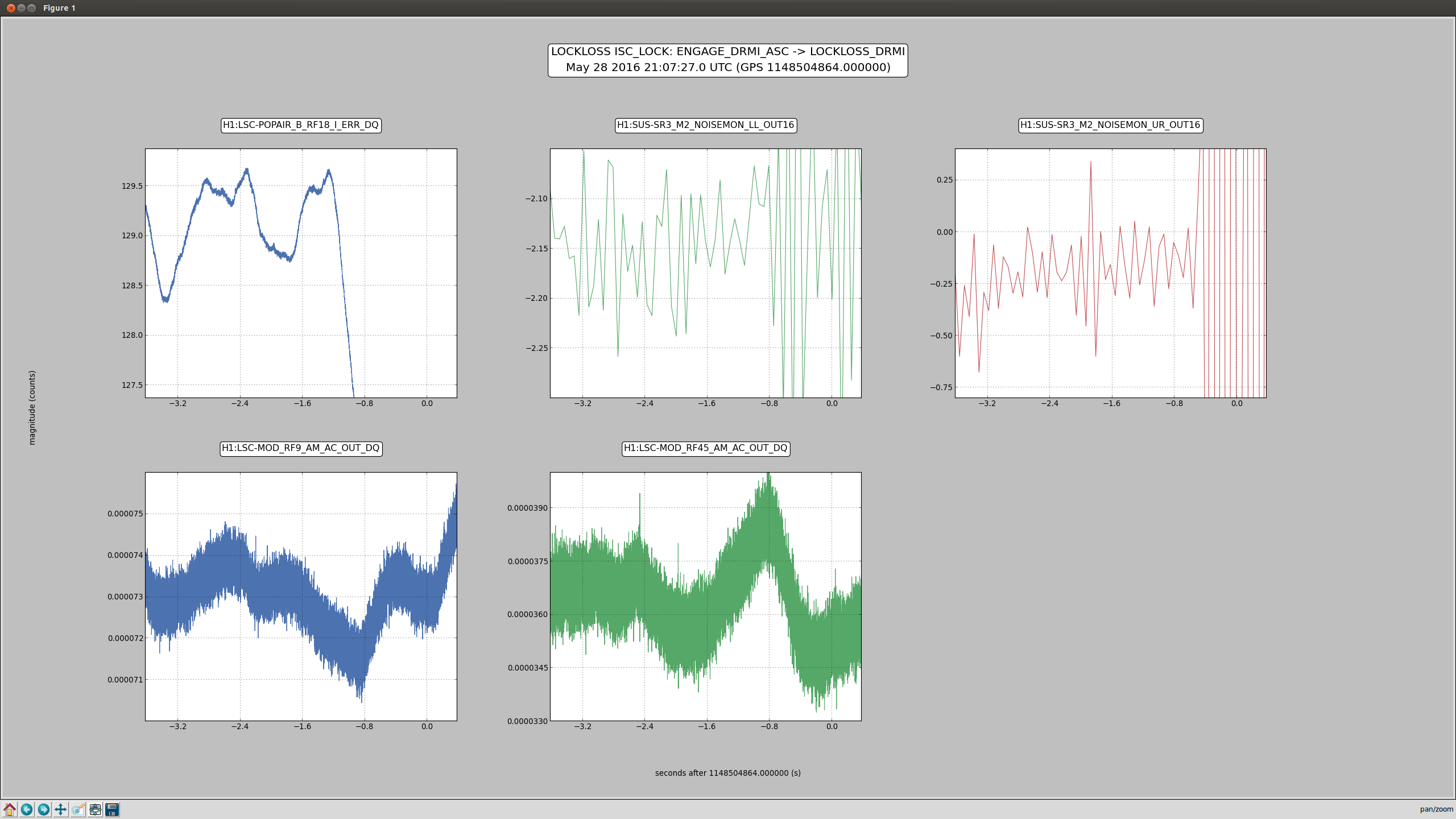
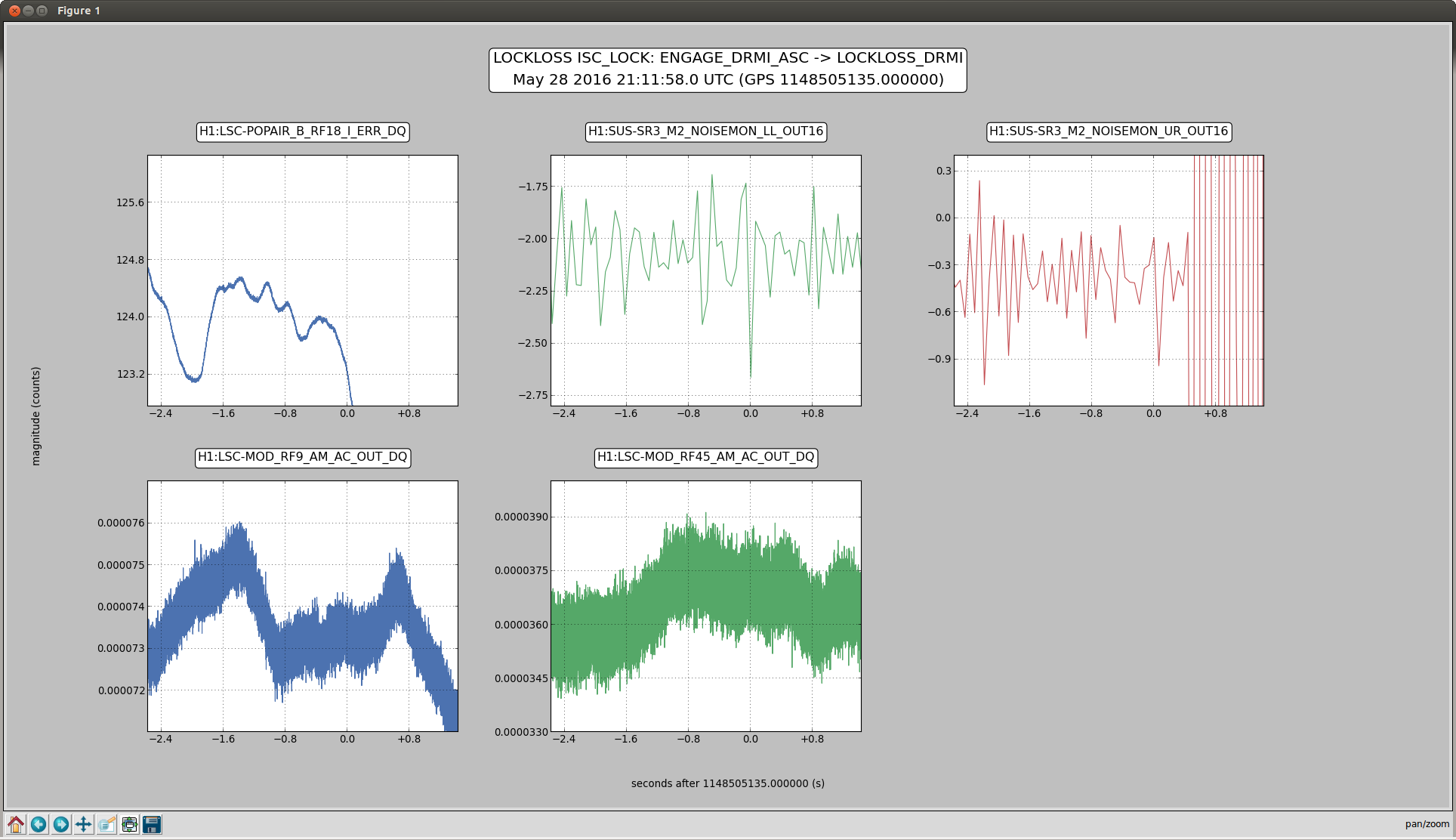
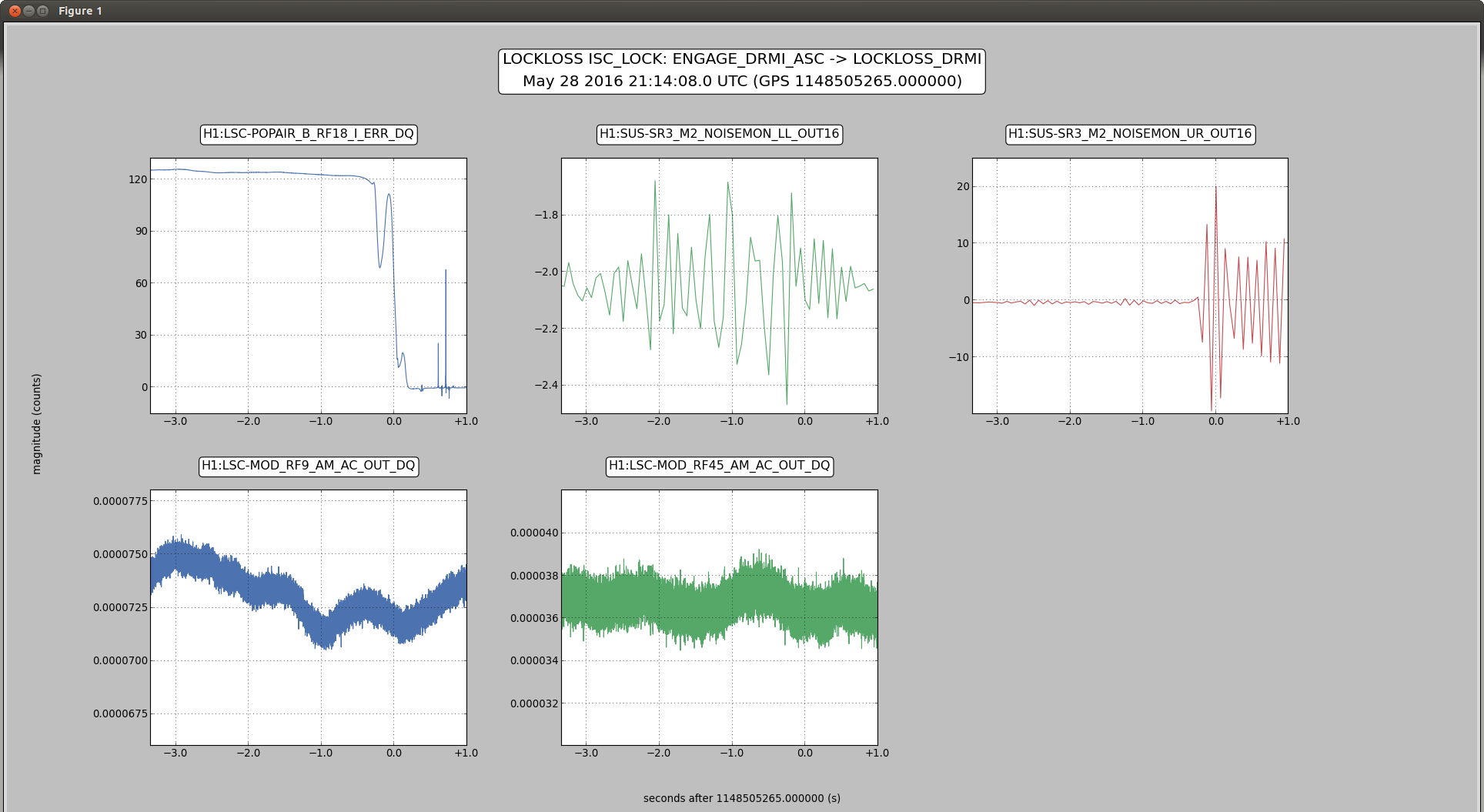
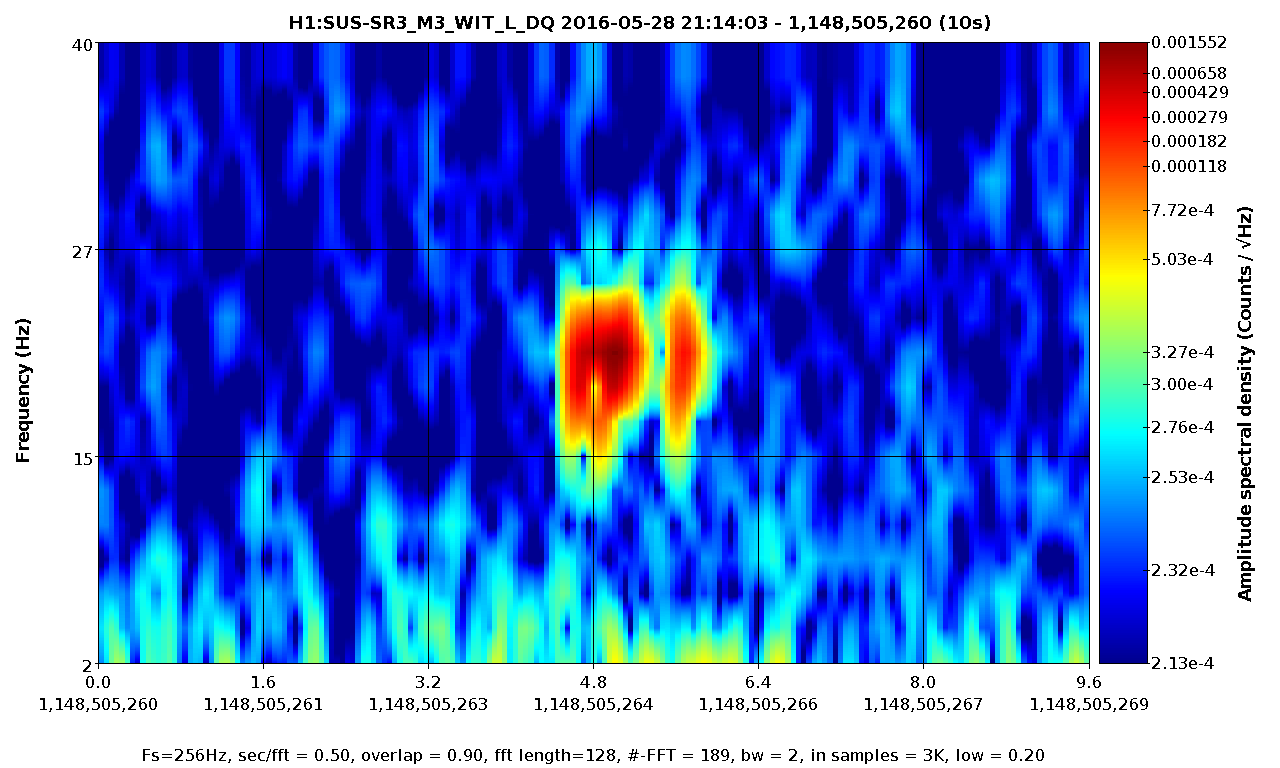
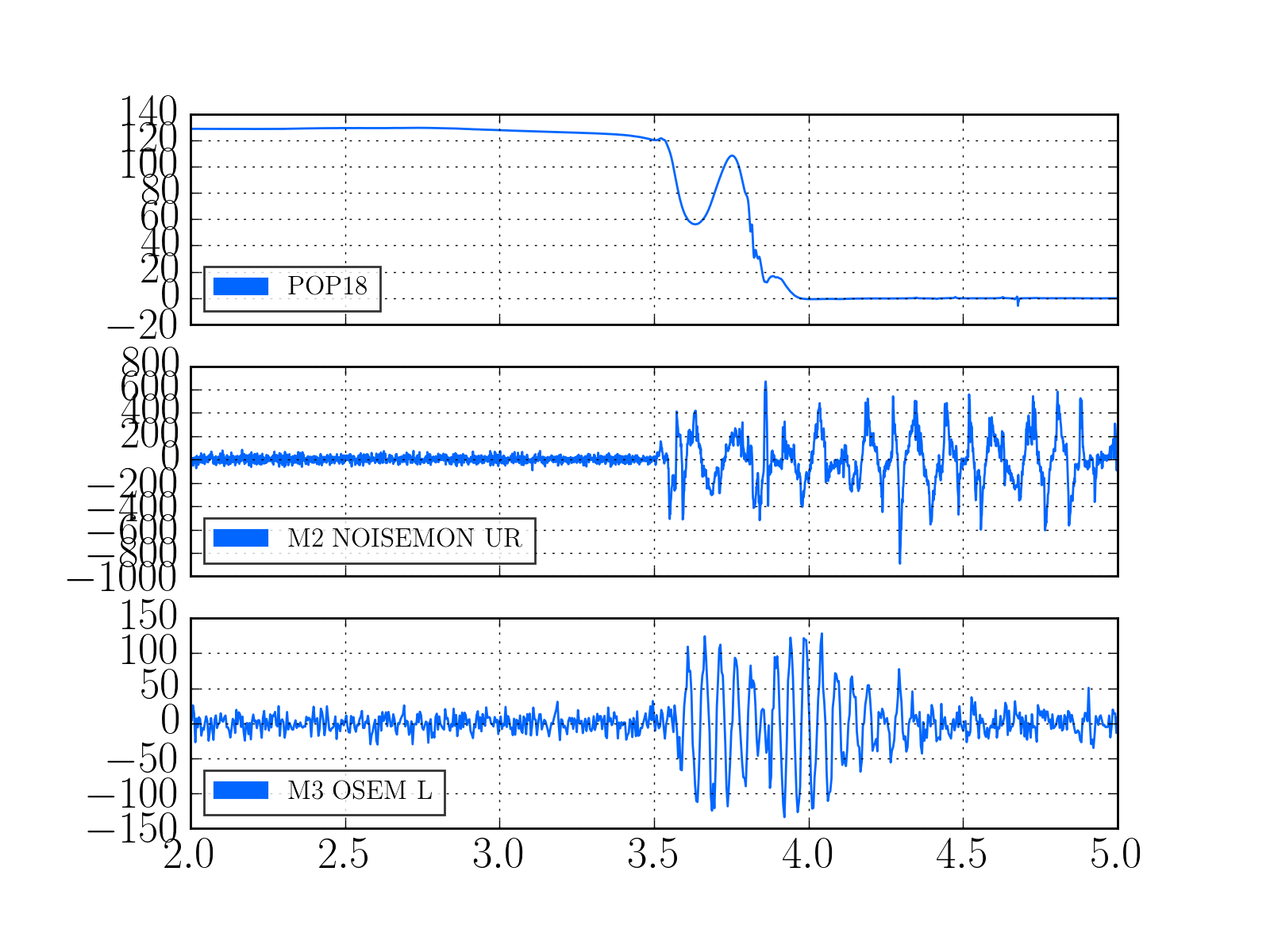
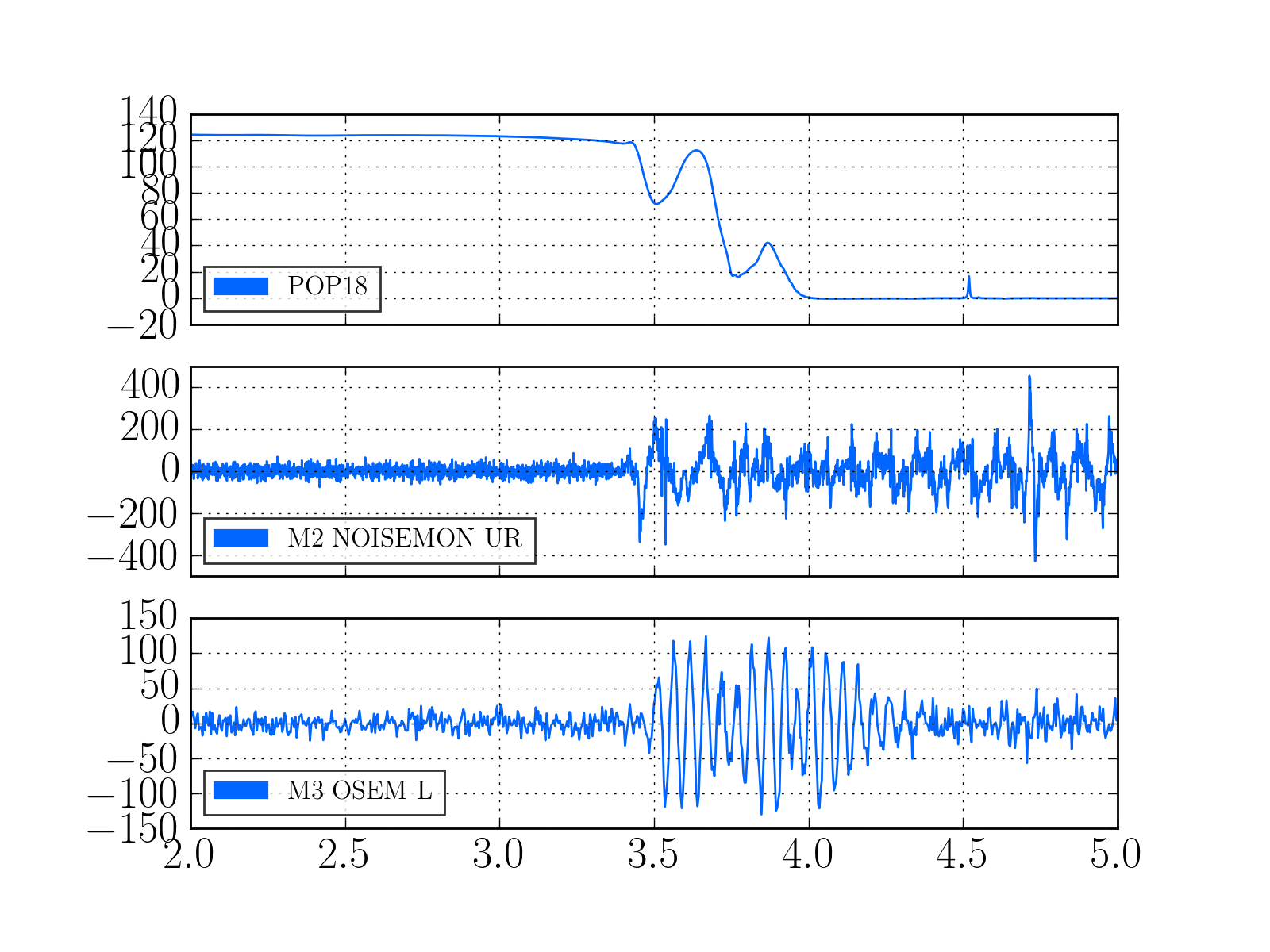
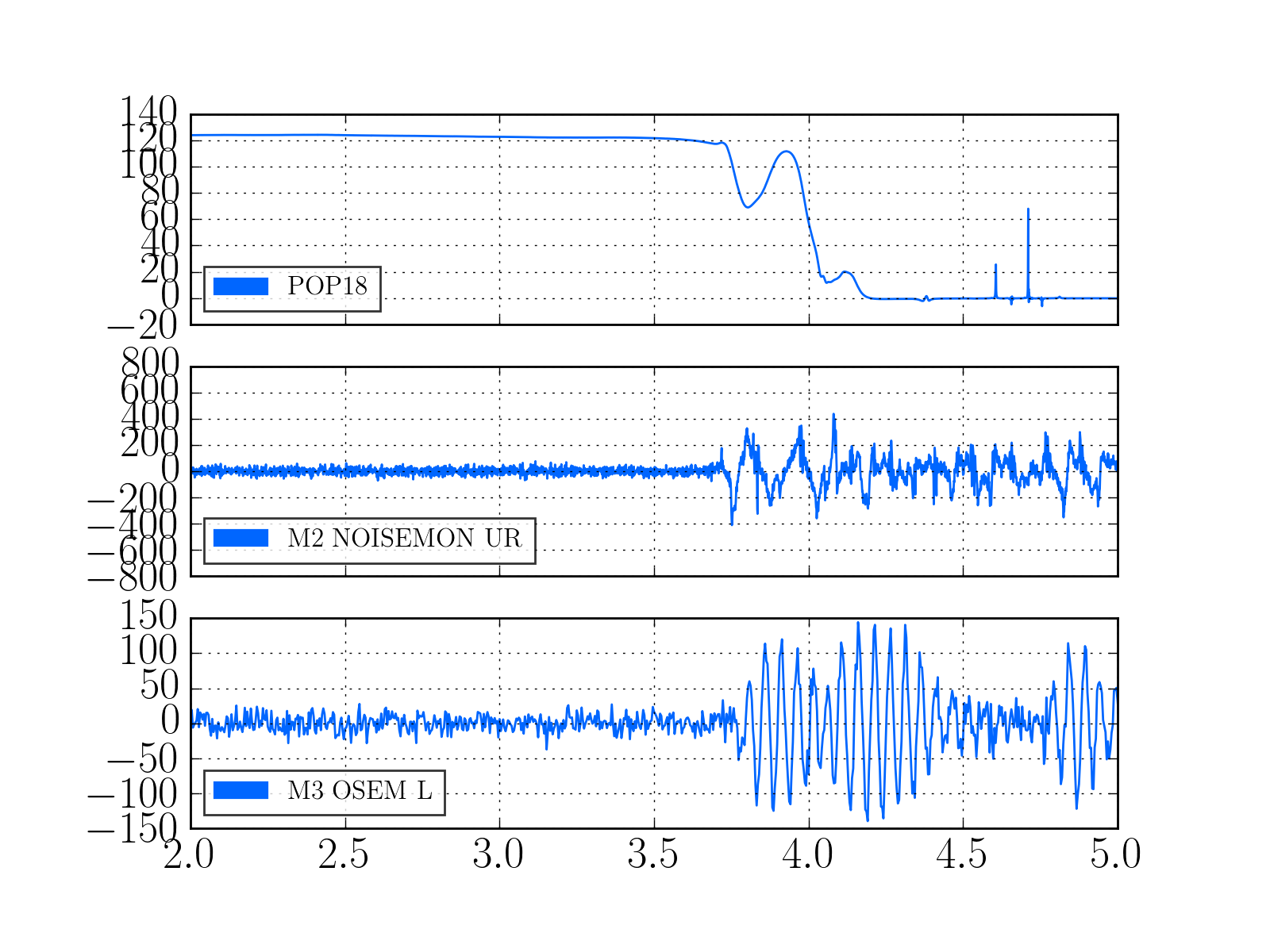
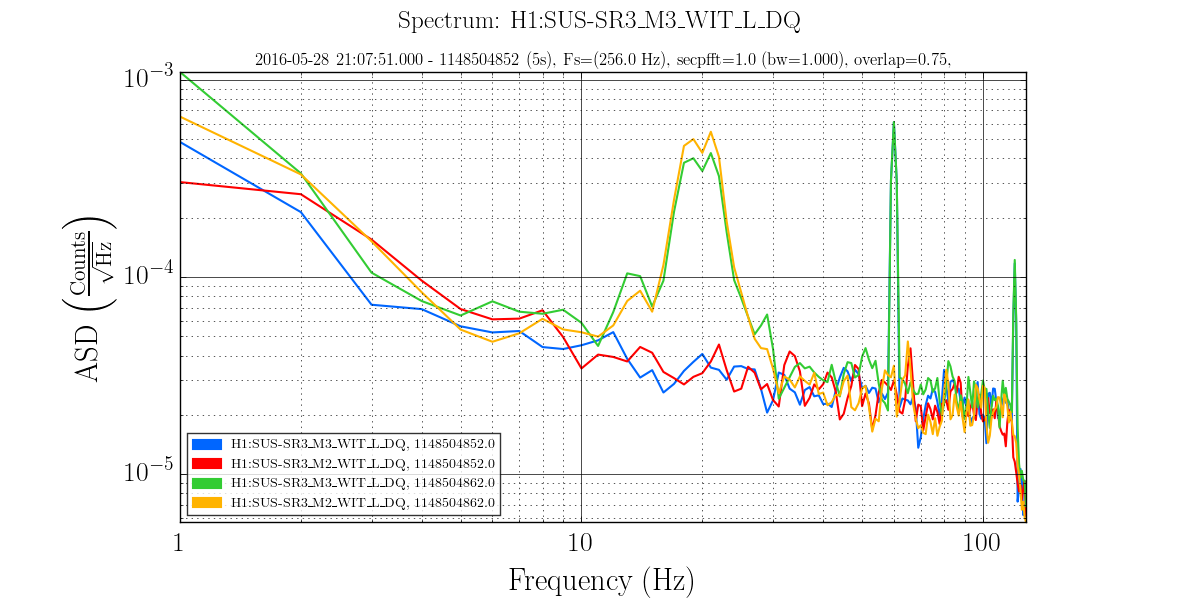
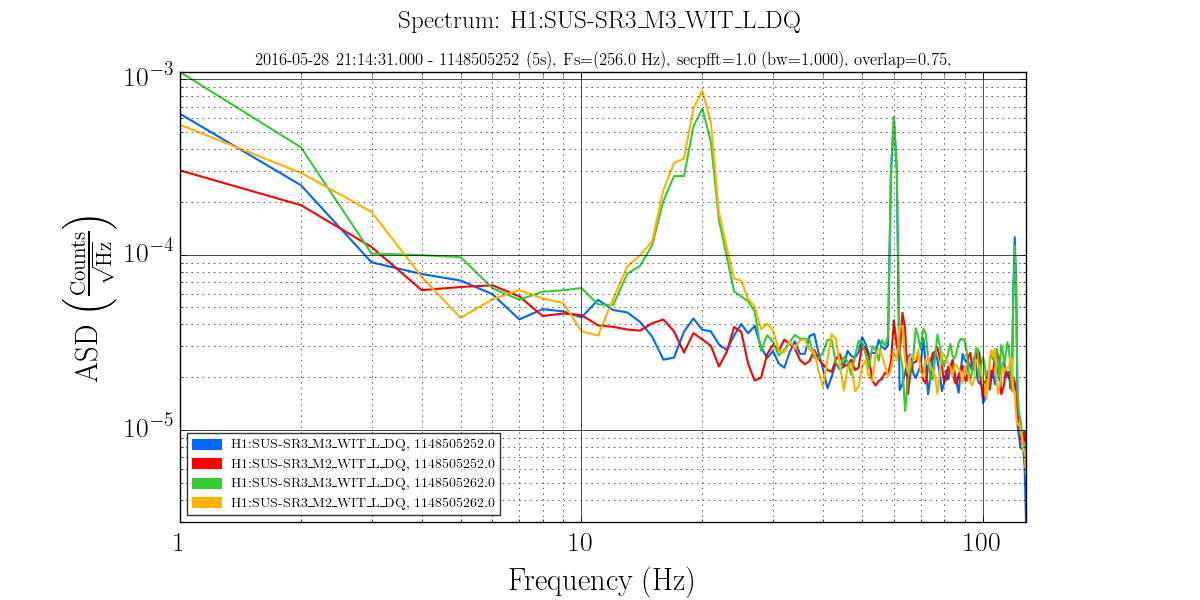
Evan H arrived on site this morning to find the TCS chillers tripped, reset them and found the same behavoir as described in alogs 27381 and 27374
On the OAFIOP GDS TP screen, both the DAC and ADC bits (as well as DK) were red, the ADC error cleared with a diag reset but the DAC error would not reset. We called Dave and he asked us to check that the DAC outputs were all zero by looking at the DAC MON screens (accessed by clicking the blue buttons labeled D0). This means that it is the same DAC problem Nutsinee described.
To fix the problem, you need to stop and start all the models on the front end, including the IOP model. This can be done by:
1)maybe check SDF before you kill models (I frogot this step)
2) log in to h1oaf0 as controls
3) run a script /etc/kill_models.sh, wait for all models to be shut down in the correct order, with the IOP model last
4) run a script /etc/start_models.sh
5) Dave said that for the PEM model only we restore the settings by loading the OBSERVE.snap and hitting LOAD TABLE +EDB. Since I frogot to check SDF before killing the models I am using the automatic burts to restore the rest of the models. Confusingly, the automatic burts always appear to indicate that there are no diffs, because all channels are no mon in them, so to actually check you need to select full table, select all mon, then set the table back to setting diffs. Time machine doesn't work for the SDF screens, which would be handy in a situation like this.
Go to the mezzanine and follow instructions here https://lhocds.ligo-wa.caltech.edu/wiki/TCS to restart the chillers, and the laser controllers near the TCS tables.