We have had trouble with alingment since maintence day today. There were several things that happened that could potentially impact alingment: SUS models were restarted, HEPI work, and adding picomotors to the PSL before the PMC. The PSL work is probably the most likely culprit. I hope that we will be more selective about what we choose to do on maintence day from now on.
Alingment symptoms:
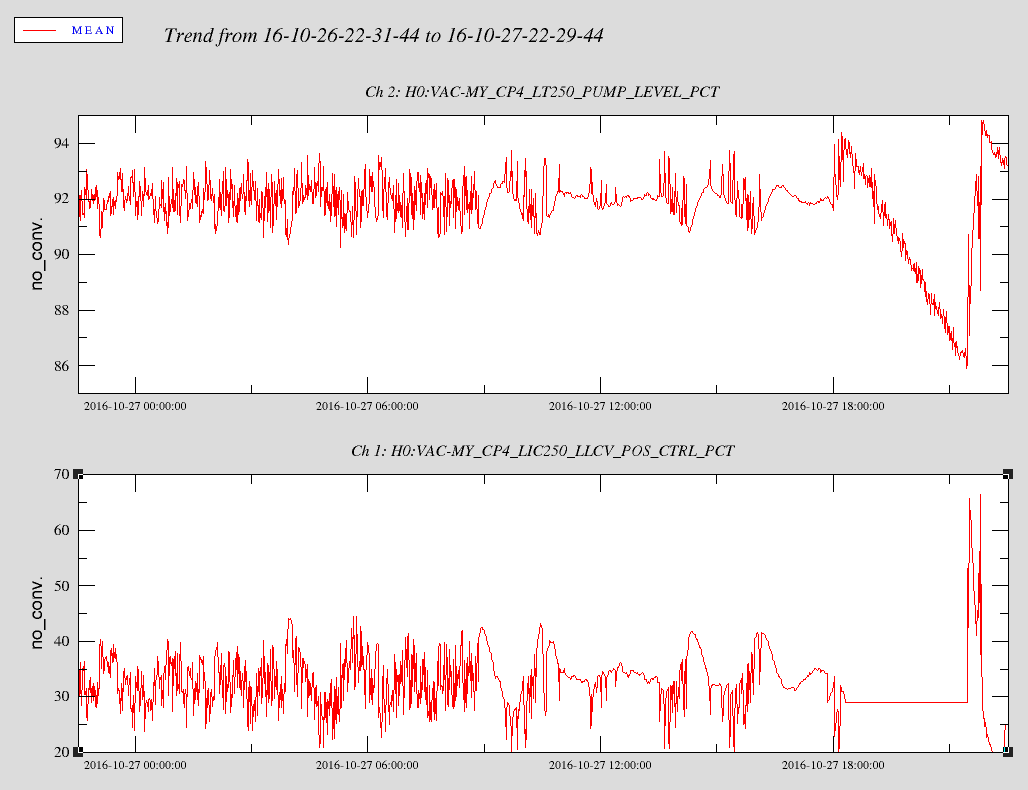
The PMC alingment is not as good as it had been. There were also shifts in the alingments of MC1+3, especially in yaw. Were these from model reboots or did someone intentiaonally change them to relock the mode cleaner? The spot on IM4 trans move from 0.2 in yaw to -0.35 or so. TJ and I trended all the IM osems and they hadn't moved much, but we restored the small changes. Once Jeff B and I finally got the IFO locked (I engaged the soft loops one at a time by hand), our recycling gain was very low (below 24). I tried to move MC1+3 in yaw to restore the position on IM4, both earlier with TJ and with the full IFO locked, the MC WFS generally drag it back to where it was. With the full IFO locked I moved IM3 in yaw, which did help the recycling gain (I chose IM3 because it's after teh Faraday, not because I think it is what moved). I moved it too fast and broke the interferometer lock, so we finished using it to restore the position on IM4 Trans with just the mode cleaner locked. We partially reverted this because we saw no flashes in the arm, and are going to give up for the night now.
If we still have this problem in the morning, it is probably worth taking a look at the irises that Cheryl placed on the PSL table a while ago to see if the beam goes into the IMC with the same alignment.
REFL WFS don't work for PR2 at 2 Watts:
I changed the ISC_LOCK guardian back to using POPX WFS for acquisition. The point of the POPX WFS is that they can be used even when inital alingment isn't great and the recycling gain is low, so we would like to keep them on for power up and switch to REFL WFS in LOWNOISE_ASC. I've put some code in low noise ASC to switch back, but we haven't gotten to test this yet. I guess that the matrix to use REFL to control PR2 was probably tested at 25 Watts last night but set up in the guardian for use at 2 Watts, because Jeff B couldn't engage the REFL WFS yesterday morning after commisioners left. Tonight it was clearly breaking the lock, which might have been partly because of our bad alingment, but when we changed it back to POPX it was fine.
Initial Alignment changes:
Jeff B and I just made a few changes to initial alingment, after TJ, Evan, and I had difficulty with input align earlier in the night. Although our alingment change today probably contributed to this, I think the changes are good and things I've been meaning to do for a while anyway.
-
We re wrote the REFL WFS Centering states to be identical to the WFS centering states used in DRMI, without the AS loops. This was beacsue the old refl wfs centering state would not always stop the operator from continuing to align if the DC servos were railed.
-
We changed the INPUT align state from using REFL WFS, which have very little light on them but were the only WFS available when we first wrote this state, to using AS45I. These are better signals and I've been meaning to make the change for a while now. To do this we made AS WFS centering states which are a copy of the REFL WFS centering states.



{kind=link}