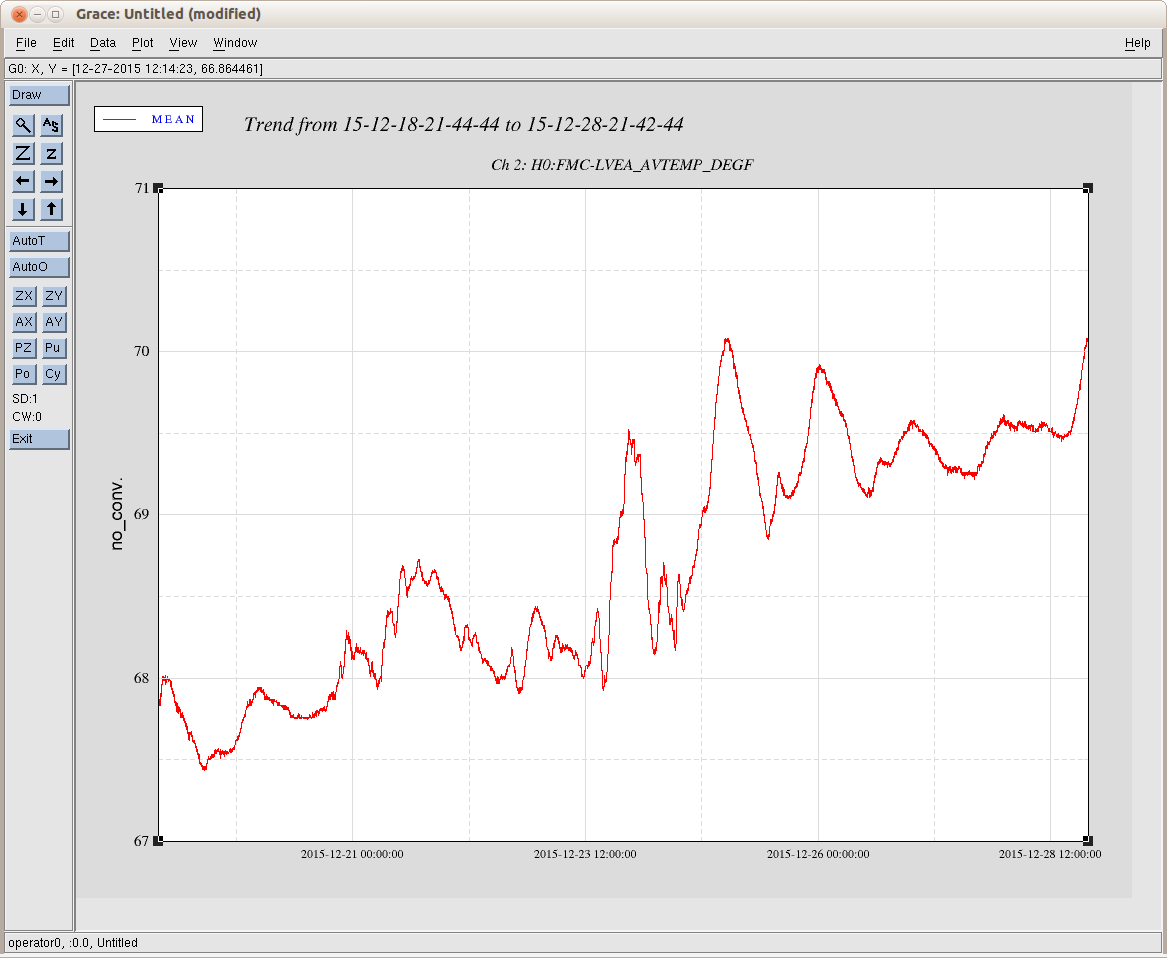
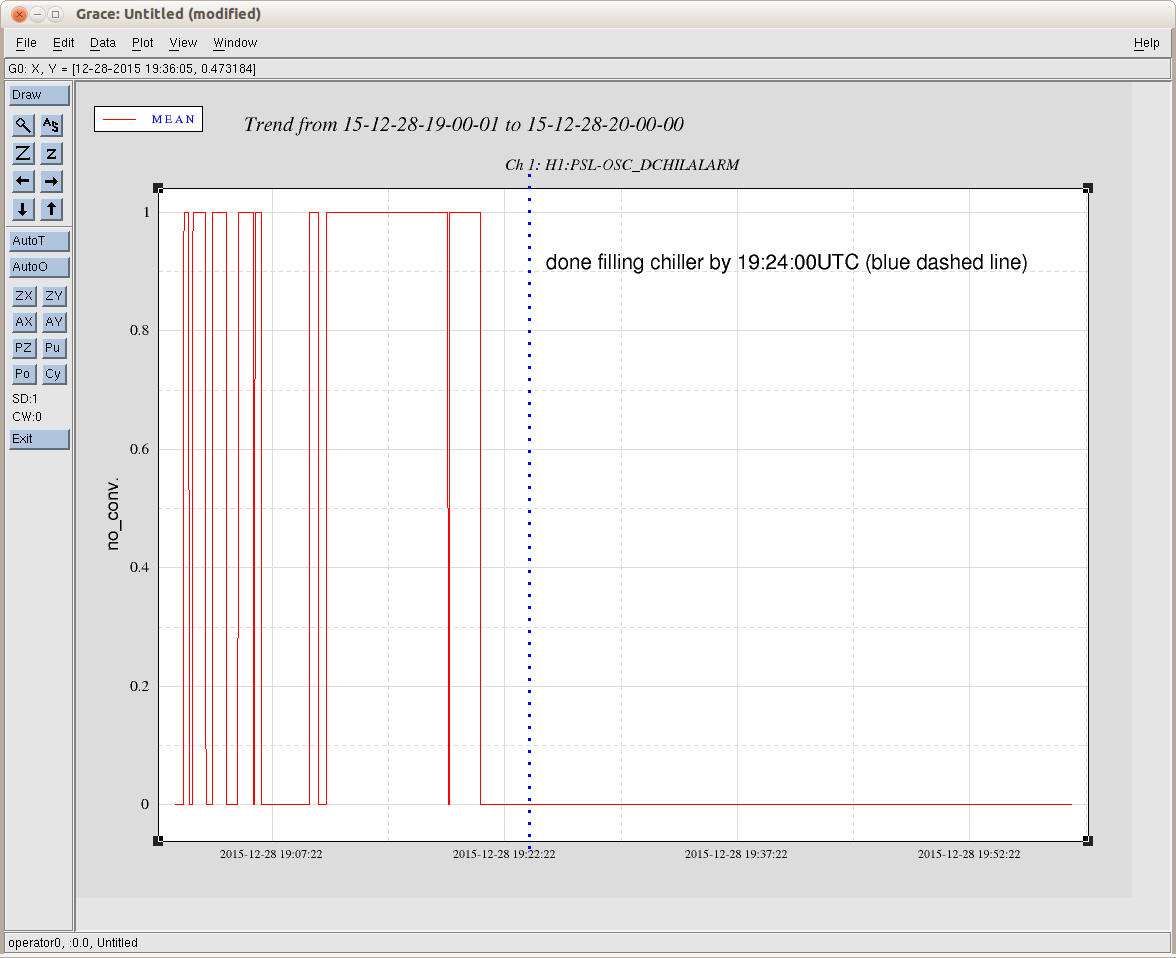
jeffrey.bartlett@LIGO.ORG - posted 16:30, Monday 28 December 2015 (24524)
Ops Evening Shift Transition
Title: 12/28/2015, Evening Shift 00:00 – 08:00 (16:00 – 00:00) All times in UTC (PT) State of H1: 00:00 (16:00), The IFO has been in Observing mode for the past 5 hours (IFO has been locked for over 40 hours, but there was a break in observing). Environmental conditions are good. The wind is calm (0- 1mph); seismic is flat and microseism is centered around 0.3um/s. Outgoing Operator: Cheryl